167The corpus used for the analysis of subgenres in this dissertation is presented in this chapter. Besides the text corpus itself, a bibliographical database of nineteenth-century Spanish-American novels was created. On the one hand, it had the purpose of serving as an information pool from which to retrieve data about authors, works, and editions during the process of corpus creation. On the other hand, it approximates the population from which the actual text corpus was sampled so that eventual particularities of the corpus can be assessed. Furthermore, the digital bibliography and corpus, which were created in the context of this thesis, constitute general databases for digital text or metadata analysis on nineteenth-century novels from Argentina, Cuba, and Mexico. In this chapter, all the aspects of these two resources that are relevant for their use in digital genre analysis are presented so as to provide a thorough documentation of both databases and to encourage reuse, even if not every aspect of the metadata and text encoding is used in the text analysis part of this dissertation.
168The chapter is organized as follows: In chapter 3.1, the criteria used for the selection of texts for the bibliography and the corpus are discussed. The creation of the bibliographical database and the corpus itself – their sources, data model, text treatment, metadata, and text encoding – are outlined in chapters 3.2 and 3.3. Overviews of the contents in the bibliography and the corpus are given in the chapter following this one: In chapter 4.1, the authors, works, editions and subgenres contained in both resources are analyzed and compared regarding their distribution by selected metadata and text parameters (for instance, by country and time period). At some points, the discussion of the selection criteria in chapter 3.1 already refers to digital bibliographical information and full texts as bases for decision-making because the processes of defining the selection criteria and building the databases went hand in hand: an initially broad data basis was analyzed and successively cut to satisfy stricter criteria.
169Unless otherwise stated, the selection criteria that are discussed in this subchapter apply both to the bibliographical database and to the text corpus. As the subject of this study are subgenres of the novel, a definition of the novel itself as the higher-level genre is necessary to be able to select the texts. Texts of all kinds of subgenres are included, even though the analysis focuses on some of them: determining the subgenres is a topic in itself and the corpus serves as a background foil for individual subgenres. The boundaries of the novel are discussed in chapter 3.1.1. Although this dissertation aims to analyze subgenres of Spanish-American novels, not all of the countries belonging to the region are taken into account simply because it would be too challenging to regard all the individual literary-historical contexts of the new nations and old colonies. Instead, it was decided to concentrate on three countries: Mexico, Cuba, and Argentina. In chapter 3.1.2, it is explained why these three countries were chosen and how it was decided which novels are associated with each of them. Chapter 3.1.3 explains which limits of the nineteenth century were used here to select the texts.
170To facilitate an understanding of the examples, also in the cases of lesser-known works, whenever individual works are mentioned, the year of their first publication and a country code is given in parentheses after the title. For all the selection criteria, it was an objective to find ways to decide that are suitable for a quantitative study, in that the amount of necessary close reading of the texts is kept as low as possible, with the goal to make the selection criteria in principle applicable to a corpus of any size.
171The bibliography and corpus are intended to include literary texts that belong to the genre novela. In general, a novel can be defined as a longer fictional narration in prose that is usually published as one or sometimes several independent books (Fludernik 2009, 627Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.; Steinecke 2007, 317Steinecke, Hartmut. 2007. “Roman.” In Reallexikon der deutschen Literaturwissenschaft, edited by Klaus Weimar, Harald Fricke, and Jan-Dirk Müller, 317–323. Berlin, New York: De Gruyter.). Besides the general characteristics of the form, manifestations of the novel are very varied, for example, regarding the content of the texts and the kinds of characters or elements of the plot. Most of the criteria that go beyond the broad formal characterization of the genre are only valid for one or several subgenres, excluding others.113 Because no subgenres or types of novels are excluded here from the outset, the general definition of the novel is followed. However, even the above-mentioned formal elements need to be clarified further because they depend on the cultural and historical context under consideration.114 In the following, the individual elements of the above definition of the novel (fictionality, narrativity, prose, length, independent publication) are discussed for the Spanish-American context in the nineteenth century. The methods used to assess these properties for the texts in question are outlined, with a special focus on borderline cases, in order to exemplify where the boundaries of the novel were drawn. Finally, additional criteria complementing the formal aspects are explained, and the various factors are summarized in a working definition of the novel.
172In a pretheoretical understanding, fictionality describes the property of a text (or other medium) to involve fiction, which means that it is about something imagined and invented. A novel, for example, is about events that did not actually take place, even if the author was inspired by the reality he or she knows and even if the author alludes to this reality in the text. Even so, theoretical considerations of fictionality show that it is not enough to assume that a text is fictional if it is about imaginary worlds (Klauk and Köppe 2014, 3Klauk, Tobias, and Tilmann Köppe. 2014. “Bausteine einer Theorie der Fiktionalität.” In Fiktionalität. Ein interdisziplinäres Handbuch, edited by Tobias Klauk and Tilmann Köppe, 3–31. Berlin, Boston: De Gruyter.).115 Recent approaches focus on pragmatic aspects to determine the fictionality of a text. According to the “institutional” theory of fictionality, for example, certain texts are considered fictional because of a coordinated and conventional social practice (an institution). A text is produced with the intention to be received according to the conventions of the fictionality institution. The sender and recipient of a fictional text enter into a contract establishing that questions of empirical referentiality and truth are not posed within the confines of the fictional text. The reader accepts the existence of the entities presupposed in the text and engages with them imaginatively if he or she recognizes the intention of the author to write a fictional text. For this, the authorial intention needs to be manifest in the text in some way, but ultimately, it is a pragmatic attribution to determine the fictional intention of a text (Köppe 2014, 35Köppe, Tilmann. 2014. “Die Institution Fiktionalität.” In Fiktionalität. Ein interdisziplinäres Handbuch, edited by Tobias Klauk and Tilmann Köppe, 35–49. Berlin, Boston: De Gruyter.; Weidacher 2017, 378–381Weidacher, Georg. 2017. “Fiktionalität und Fiktionalitätssignale.” In Handbuch Sprache in der Literatur, edited by Anne Betten, Ulla Fix, and Berbeli Wanning, 373–390. Berlin, New York: De Gruyter.).
173In accordance with this view, the fictionality of the texts to be included in the bibliography and the text corpus was assessed as follows. Statements of authors and readers regarding the fictionality of a text were taken into account. If it was indicated clearly that the text was conceived and received as fictional at the time and place of its publication, these signals were highly rated. In addition to explicit statements concerning the fictionality of the text, other paratextual and textual signals were evaluated. A comprehensive overview of potential signals of fictionality is given by Zipfel (Zipfel 2014, 97–119Zipfel, Frank. 2014. “Fiktionalitätssignale.” In Fiktionalität. Ein interdisziplinäres Handbuch, edited by Tobias Klauk and Tilmann Köppe, 97–124. Berlin, Boston: De Gruyter.), who organizes them as follows:
174Of the various potential signals of fictionality, peritextual signals were especially useful to evaluate whether texts are to be considered fictional and if they should become part of the bibliography and the text corpus because they are very accessible.116 Details such as author, title and subtitle, place of publication, publisher, and series are usually included in bibliographic descriptions of work editions and can, therefore, also be taken into account when the texts themselves are not available.117 A good indicator is a genre label in the title or subtitle of a work that refers to a fictional text type. Examples of such titles for Spanish-American narrative texts in the nineteenth century are: “novela”, “relato”, “narración”, “leyenda”, “romance”, “cuento”, or “drama”. There are other labels that are also common but less clear regarding the fictional status of the texts, for example: “historia”, “crónica”, “estudio”, “esbozo”, “cuadro”, “escenas”, “episodio”, “memorias”, “apuntamientos”, “anécdotas”. Sometimes labels refer to subgenres, such as “aventuras” or “costumbres”. To be able to decide whether a text is to be considered fictional or not in cases where labels are ambiguous, or where there are no explicit labels at all, other kinds of information were used. Where editions of a work were accessible, prefaces, introductions, and headings were consulted to see whether they clear up the issue of fictionality. Textual signals on the level of the story and on the level of the narration were also taken into account, but only in cases of doubt. A textual signal that is easy to recognize typographically and is typical for fictional narrative texts, though it is neither a necessary nor a sufficient criterion, is the reproduction of direct speech. Words or phrases that mark the end of a story or text can also be easily identified. Epitextual signals were not systematically researched. Especially for the bibliographical database, decisions were also based on information from existing bibliographies of fictional texts, literary histories, and other critical research literature.
175In the case of Spanish-American novels, there are several factual text types that share characteristics with certain subtypes of the novel in terms of content or narrative mode. These are historiographic works versus historical novels, (auto)biographies versus (auto)biographical novels, travelogues versus travel novels, philosophical treatises versus philosophical novels, political treatises versus political novels, etc. That the boundaries between some kinds of fictional and factual texts are not always clear is influenced by several factors. Many of the authors in the nineteenth century who wrote novels were also authors of historiographic, political, journalistic, or philosophical works because there were still very few professional literary writers. Furthermore, many Spanish-American countries reached their political independence in the early nineteenth century, and there was a need to justify it and to contribute to the creation of a national identity not only through historiography but also by means of literary works (Kohut 2016, 171–172Kohut, Karl. 2016. Kurze Einführung in Theorie und Geschichte der lateinamerikanischen Literatur (1492–1920). Berlin: Lit Verlag.; Lindstrom 2004, 76–77Lindstrom, Naomi. 2004. Early Spanish American Narrative. Austin: University of Texas Press.; Sommer 1993Sommer, Doris. 1993. Foundational Fictions. The National Romances of Latin America. Berkeley: University of California Press.). In his essay “Revistas literarias de México” from 1868, the Mexican author Ignacio Manuel Altamirano explains the ever more important role of the novel in this process:
La novela es indudablemente la producción literaria que se ve con más gusto por el público, y cuya lectura se hace hoy más popular. Pudiérase decir que es el género de literatura más cultivado en el siglo XIX y el artificio con que los hombres pensadores de nuestra época han logrado hacer descender a las masas doctrinas y opiniones que de otro modo habría sido difícil que aceptasen. [...] la novela hoy ocupa un rango superior, y aunque revestida con las galas y atractivos de la fantasía, es necesario no confundirla con la leyenda antigua, es necesario apartar sus disfrazes y buscar en el fondo de ella el hecho histórico, el estudio moral, la doctrina política, el estudio social, la predicación de un partido o de una secta religiosa: en fin, una intención profundamente filosófica y trascendental en las sociedades modernas (Altamirano 1868, 17–18Altamirano, Ignacio Manuel. 1868. Revistas literarias de México. México: T. F. Neve.)
176As long as they are either designated directly or indirectly as fictional in their paratexts or exhibit characteristics that are typical for fictional texts, these works were included in the bibliography and the corpus, even if they resemble factual texts because of their content or because of the way the narration is organized.
177For example, the Mexican author Ireneo Paz wrote several historical novels that he labeled as such, but also a series of “leyendas históricas”. They are all centered on historical figures, as their titles suggest: “El Lic. Verdad”, “La Corregidora”, “Hidalgo”, “Morelos”, “Mina”, “Guerrero”, “Antonio Rojas”, “Manuel Lozada”, “Su Alteza Serenísima”, “Maximiliano”, “¡Juárez!”, “Porfirio Díaz”, and “Madero” (Pi-Suñer Llorens 2005, 386Pi-Suñer Llorens, Antonia. 2005. “Entre la historia y la novela. Ireneo Paz.” In La república de las letras. Asomos a la cultura escrita del México decimonónico, edited by Belem Clark de Lara and Elisa Speckman Guerra, 379–392. Vol. 3: Galería de escritores. México: UNAM.). They could also be interpreted as historical biographies, but because they are labeled as “legends” and contain direct speech, detailed descriptions of situations (e.g., weather conditions) and characters (e.g., behavior and appearance in specific situations), they are considered fictional texts here.
178A work that is sometimes mentioned in critical works on the Spanish-American novel is “Vida de Juan Facundo Quiroga” (1845, AR) by Domingo Faustino Sarmiento.118 In the first part of the work, the country, its inhabitants and their customs are described, followed by a biography of the Argentine caudillo Juan Facundo Quiroga. The last part contains considerations about Argentina’s political and economic future (Lichtblau 1959, 39–40Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.). In a preface, the author refers to reactions by readers who missed certain details in the descriptions of historical events. Sarmiento defends himself by explaining how difficult the coordination of events that occurred in so many different places and at so many different points in time was challenging with the limited means he had (some reports of eyewitnesses, some simple manuscripts, some aspects recalled from his memory). He ends with the intention to improve his work in these aspects if time allows:
Quizá haya un momento en que, desembarazado de las preocupaciones que han precipitado la redacción de esta obrita, vuelva a refundirla en un plan nuevo, desnudándola de toda digresión accidental, y apoyándola en numerosos documentos oficiales, a que sólo hago ahora una ligera referencia. (Sarmiento [1845] 2000, sec. Advertencia del autorSarmiento, Domingo Faustino. (1845) 2000. Vida de Juan Facundo Quiroga (en formato HTML). Edited by Benito Varela Jácome. Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmc18359.)
179In this authorial statement, there cannot be recognized any intention to write a fictional text. Moreover, the different parts of the work are not unified, and there are very few passages where direct speech is reported. “Vida de Juan Facundo Quiroga” is therefore considered a non-fictional text and excluded from the bibliography and the corpus.
180Other borderline cases are descriptions of travels, for example, “La tierra natal” (1889, AR) by Juana Manuela Gorriti, “Mis montañas” (1893, AR) by Joaquín Víctor González, and “Una excursión a los indios ranqueles” (1870, AR) by Lucio Victorio Mansilla. All three texts also include autobiographical elements. For a factual travel narrative, three conceptual aspects are essential:
181When the three examples are examined, the following characteristics can be determined. In “La tierra natal”, the framing story is a railway trip from Buenos Aires to Salta. The text is structured into chapters that roughly correspond to stops of the journey. The traveler and first-person narrator gives an account of the journey and inserts conversations of fellow passengers, but also memories of her hometown. In a preface, Gorriti calls her work “páginas de lejanas memorias” (Gorriti [1889] 2001, 1Gorriti, Juana Manuela. (1889) 2001. La tierra natal (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmc222t4.). The end of the narration is marked with the word “Fin”.
182In “Mis montañas”, the first-person narrator gives a report of a trip to the Sierra de Velazco in the Argentine province of La Rioja. The text is divided into 21 chapters which consist of landscape descriptions and impressions, historical background information and the imagination of historical events, the portrayal of local customs, the evocation of local characters and episodes, and personal memories. The work is prefaced by the Argentine writer Rafael Obligado, who gives several intertextual references. For example, he compares “Mis montañas” to the epic poem “La cautiva” by Esteban Echeverría. However, he does so not to stress its fictionality but the literary treatment of the Argentine landscape: “La propiedad artística de la cordillera argentina pertenece a Vd. de hoy para siempre, como la de la llanura al poeta de La Cautiva” (González [1905] 2001, XGonzález, Joaquín Víctor. (1905) 2001. Mis montañas (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmcw37r4.).119
183“Una excursión a los indios ranqueles” begins with a letter written by the narrator, identified as “Lucio” and “coronel Mansilla”, just like the author, to his friend Santiago, in which he explains the circumstances of his expedition to the province of Córdoba where the indios ranqueles live. In 68 chapters, the narrator recounts his experiences in the form of letters to his friend. The work contains descriptive passages concerned with sociological, zoological, botanic, philological, and folkloristic facts, but also an intercalated novella and novelistic amatory and military scenes (García 1952, 132García, Germán. 1952. La novela argentina: Un itinerario. Buenos Aires: Editorial Sudamericana.; cited by Lichtblau 1997, 609Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.; Rössner 2007, 186–187Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.).
184In all three works, the discourse is organized around a
journey that actually took place. All the texts are narrated in the first
person, and the narrator can be identified with the author, either because
of an explicit mention in the text (“Una excursión a los indios ranqueles”)
or because of implicit formulations in the prefaces (“La tierra natal” and
“Mis montañas”). In the paratexts, there is no clear evidence that the three
travelogues were conceived or perceived as fictional. As to the third
defining aspect of a factual travel narrative, the nature of the three works
under consideration is less clear. All of them combine descriptive with
narrative passages and objective representations with subjective perceptions
to different degrees. One indicator for a narrative style, and hence a
fictional text, that can be evaluated quantitatively is the amount of direct
speech in the three texts. In figure
2, the travelogues are compared to other novels in the corpus
regarding the proportion of paragraphs containing direct speech.120 As can be seen, the amount
of direct speech in the three travelogues is less than in 75 % of the
novels, so even if there are novels with an equal proportion of paragraphs
containing direct speech, they do not represent the typical novel.
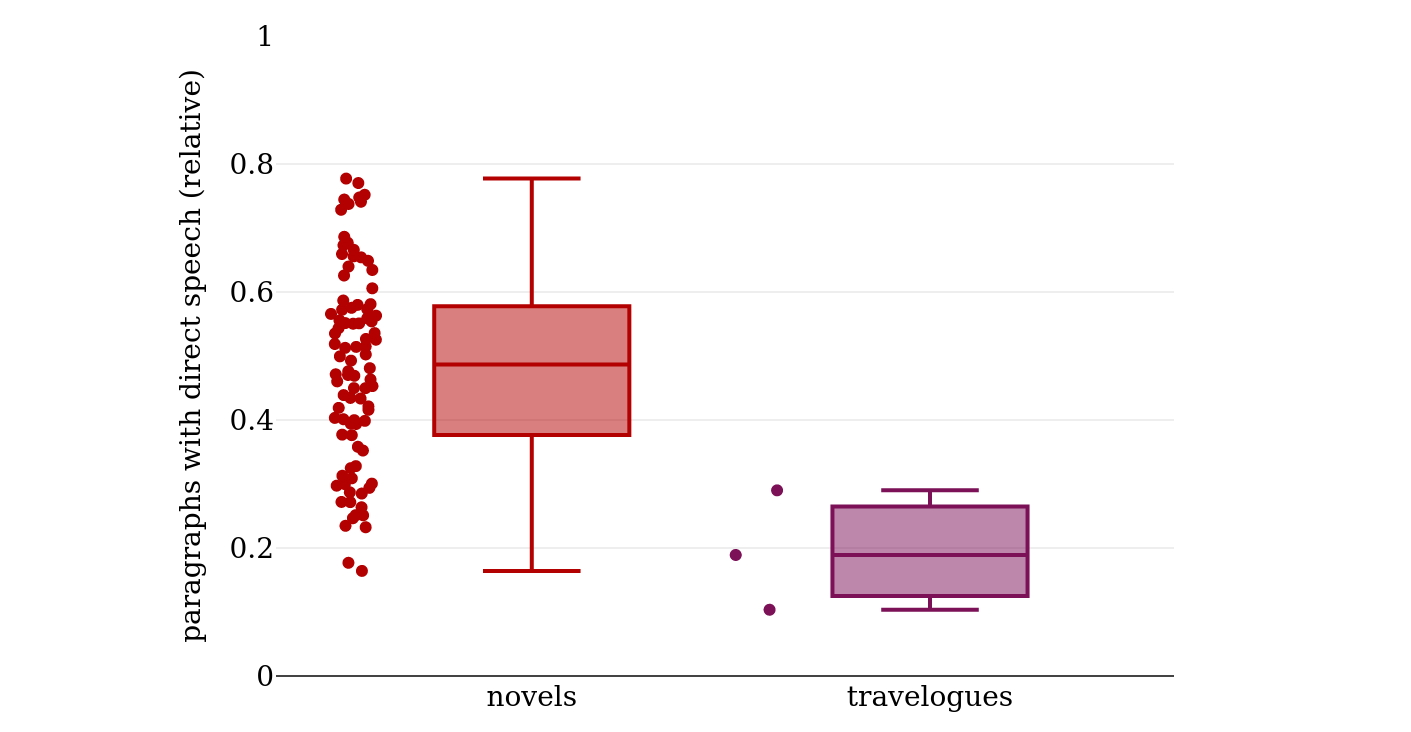
185To conclude, even though the three travelogues resemble novels in some aspects (narrative, subjective, and probably also fictional passages), they also share essential characteristics with factual travel narratives, and there are no indications that they were intended and read as fictional texts in their time. As a consequence, they were excluded from the bibliography and the corpus, even though they exhibit a certain generic ambiguity.121
186In contrast to the examples that were discussed in detail above, in the majority of cases, the fictional status of the texts that were candidates for the bibliography and the text corpus could be determined easily based on paratextual information, bibliographical and literary-historical sources. In the unclear cases, a reasoned decision was made, as exemplified above, whereby textual and paratextual information was preferred over critical discussions as far as possible.
187According to Weber, narration is “[1] adressierte, [2] serielle, [3] entfaltete berichtende Rede [4] mit zwei Orientierungszentren [5] über nicht-aktuelle (meist: vergangene), [2] zeitlich bestimmte Sachverhalte (besonders: Ereignisse in zeitlicher Folge) [6] von seiten eines Außenstehenden” (Weber 1998, 63Weber, Dietrich. 1998. Erzählliteratur. Schriftwerk, Kunstwerk, Erzählwerk. Göttingen: Vandenhoeck & Ruprecht.; cited by Zymner 2017, 365Zymner, Rüdiger. 2017. “Narrative Gattungen.” In Grundthemen der Literaturwissenschaft: Erzählen, edited by Martin Huber and Wolf Schmid, 365–383. Berlin: De Gruyter.).122 The various elements of this definition will be briefly explained here. While Weber’s definition also holds for oral narration, it will only be applied to written narration in this context.
188Although this definition was very useful for the decision to include texts into or exclude them from the corpus, provided that they were, in principle, available, its usefulness for the selection of entries for the bibliography was limited in the same way as for fictionality. Where editions of the texts could not be accessed, it was necessary to rely only on available metadata and on third-party information. In terms of metadata, mentions of narrative genres in book titles and subtitles or in titles of book series were especially helpful. Regarding third-party information, it had to be taken into account how narrativity was defined in each context (if it was defined at all). For example, Lichtblau discusses the selection criteria for his bibliography as follows:
The problem of identifying those works that clearly belong in the classification ‘novela argentina’ beset me at every stage in the preparation of this bibliography. But I have attempted, within a certain arbitraryness inherent in all literary categorization, to be consistent in the selection or omission of the works cited. [...] In addition, I have included a few celebrated works of Argentina literature that, although not novels, retain many of the characteristics of that genre and are associated with its development and artistic expression. We may thus say that Echeverría’s El matadero, Cané’s Juvenilia, and Mansilla’s Una excursión a los indios ranqueles have been recruited for this bibliography without having the proper credentials as ‘novel’. I did leave out, however, Sarmiento’s Facundo, not wishing to stretch the point too much. (Lichtblau 1997, XV–XVILichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.)
189He does not provide an explicit definition of the novel and does not refer to the concept of narrativity. His criteria could only be inferred from the examples that he mentions.123 Therefore, wherever full texts were available, the information obtained from other bibliographies was checked before a work was included in the current bibliography. An example of a text that is included in Lichtblau’s bibliography (Lichtblau 1997, 309Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.), but excluded here, is “La flor de las tumbas” (1866, AR), written by Santiago Estrada because the text has the form of a dramatic text instead of a narrative text. It starts with a cast list, is divided into acts and scenes, contains stage directions, and consists entirely of character speech. This does not fulfill the criteria established by Weber, especially that a narration should be addressed, reported by someone external, not be immediate, and have two centers of orientation. In the preface, the author explains how he conceived his work generically:
Este trabajo no es un drama en la acepción literaria de la palabra. Moriría en el teatro, para el cual no está dedicado. El artista puede revestir sus concepciones en la forma que mejor se avenga a su expresión espontánea.—Este trabajo es un romance. Dibujar los cuadros o pintarlos, eso queda al arbitrio del artista. ¿Quién me obligaría a prestarle el empaste de la narración?
¿Puedo esperar que una lágrima escapada del alma del lector, le de el colorido que yo le niego, dejándolo en la simplicidad elemental de sus líneas?... No lo sé.—Escribo para sentir, y nada más.
Su forma no carece de precedentes. Sin traer a recuerdo magistrales producciones literarias, que tomando la división y sencillez del drama, no han aspirado a la exhibición viva de la escena, citaré solamente los conocidos romances que un poeta francés ha llamado: comedias de sillón,—y las que el marqués de Varennes ha denominado: proverbios.
Esto por lo que respecta a la forma.
(Estrada 1866, 5Estrada, Santiago. 1866. La flor de las tumbas. Buenos Aires: Imprenta del Siglo.)
190Estrada thus says that his work is not a drama because it is not intended to be presented on stage. Instead, he calls it “romance”. However, he also clearly says that it does not have the form of a narration. It is kept “simple” and “rudimentary”, without coloring, drawn, but not painted, which a narration in the sense of a detailed, stylistically evolved report would be.
191In general, however, it was easier to determine the narrativity of the texts eligible for the bibliography and the text corpus than their fictionality. As to the borderline cases for fictionality, the historical biographies and the travelogues are, for the most part, narrative. Only Sarmiento’s “Vida de Juan Facundo Quiroga” is not predominantly narrative, but it would still have to be discussed how much narrativity a text needs in order to be interpreted as a narration. As Weber states, when he elaborates his definition further, normally, a narration does not consist entirely of narrative text. It can also contain other forms of presentation, for example, the report of direct speech, descriptions, argumentative passages, or comments (Weber 1998, 64–70Weber, Dietrich. 1998. Erzählliteratur. Schriftwerk, Kunstwerk, Erzählwerk. Göttingen: Vandenhoeck & Ruprecht.). An example of a text containing scenic presentation is the historical novel “La loca de la guardia” (1896, AR), written by Vicente Fidel López. In chapter 40, the conversation between a judge and an accused person in a trial has the form of dramatic speech. Nevertheless, this passage amounts only to about 5,300 words, and the entire novel has a length of approximately 97,500 words, so it can still be considered a narrative text.
192“Prose” can be defined as a form of text that is metrically not bound, as opposed to text in verse form (see, for instance, Kleinschmidt 2003, 168Kleinschmidt, Erich. 2003. “Prosa.” In Reallexikon der deutschen Literaturwissenschaft, edited by Klaus Weimar, Harald Fricke, and Jan-Dirk Müller, 168–172. Berlin, New York: De Gruyter.). This criterion concerns primarily the distinction between narrative prose and poetry. Many of the Spanish-American novels in the nineteenth century contain inserted poems. They may be quotations at the beginning of individual chapters or part of the narration, for example, if they are recited in public by a character or are part of a love letter that is represented in the text. In general, these insertions only make up a small part of the entire text and do not question that a work is written predominantly in prose. As for the selection of texts for the bibliography, caution is required when works carry the generic label “romance” or “leyenda” because they can either be novels written in prose (for example, “El romance de un médico” (1905, AR) by Cupertino del Campo and “Un santuario en el desierto. Leyenda original” (1890, MX) by José Francisco Sotomayor) or epic texts written in verse (e.g., “Perfiles de la conquista. Romance histórico. 1521–1887” (1887, MX) by Juan Antonio Mateos and “Un ángel desterrado del cielo. Leyenda religiosa” (1855, MX) by Niceto de Zamacois). The latter were excluded from both the bibliography and the corpus.124 There are also many texts without generic labels, which can be of any genre (novels, collections of short stories or poems, plays, other types of literary or non-literary texts) and be written in prose or verse. In these cases, the recourse to existing bibliographies of the novel and to library catalogs that include information about the genre was indispensable to finding the relevant texts.
193The length of the text is one of the criteria that serve to distinguish the novel from other forms of fictional narration in prose, especially shorter ones such as the novella and the short story. However, usually, these genres are also differentiated according to other criteria because there may be exceptions, for example, very short novels and very long novellas, so that a novella might be longer than a novel in individual cases. Moreover, there is no consensus on the exact or approximate lower boundary of the length of a novel. Traditionally, the length of a fictional narration is expressed in page numbers which can only be a rough indicator because of differences in book format, layout, and typography from one edition to another.125 It is more precise to measure the length of a text independently of the design of a print edition, for example, in the number of words or characters, but this is only feasible for texts which are available in electronic form and machine-readable.
194In “Aspects of the novel”, a collection of literary lectures about the English language novel held in 1927, Forster claims: “Any ficticious prose work over 50,000 words will be a novel for the purposes of these lectures” (Forster 1927, 17Forster, E. M. 1927. Aspects of the novel. New York: Harcourt, Brace & Company.), but without motivating the number. In the context of a German handbook on literary genres, Fludernik mentions the following page limits: She sets an upper limit of 40 to 50 pages for the short story and the novella and a lower limit of 80 pages for the novel, leaving a corridor of about 30 pages for unclear cases (Fludernik 2009, 632Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.). Unfortunately, she also does not explain how she arrives at these numbers. A more detailed discussion about the extension of the short story, novella, and novel can be found in “La novela corta mexicana en el siglo XIX” by Mata, who is looking for pragmatic criteria allowing him to define the scope of his object of study. He points out that every proposal of an exact number can, at best, apply to a specific historical context but not to the novel in general. As to Forster’s suggestion, Mata states that the number of 50,000 words seems appropriate for the typical, extensive novels of the nineteenth century but not for many of the paradigmatic novels of the twentieth century, which are shorter (Mata 1999, 16Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). It should be added that also the geographical and the cultural context determine the characteristics of a historical genre. In the nineteenth century, the novel had a longer tradition in Europe than in Spanish America and was more stabilized as a genre (Fludernik 2009, 638–645Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.),126 so it can be assumed that more works complied with the established model of the time. The range of the texts considered novels in the nineteenth century in Spanish America was broad. In the early century, many of the novelistic narrative texts in prose were quite short,127 while European models – extensive historical, realist, and naturalistic novels – gained more ground towards the middle and end of the century.128 Towards the turn of the century and in the twentieth century, many novels were shorter again, in correspondence, interrelation, confrontation, and also independence from European developments.129 Using the limit set by Forster, many texts that can be assigned to the genre novela would be excluded from analysis. The strategy followed by Mata is to consult calls for literary competitions to see which limits they pose for the length of texts belonging to different narrative genres. On that basis, he arrives at the following numbers: a maximum of 5,000 words for short stories, a minimum of 5,000 words and a maximum of 35,000 words for short novels, and more than 35,000 words for novels (Mata 1999, 16–17Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). Despite his remark on the historicity of genre lengths, Mata relies on modern literary competitions in order to establish the length of novellas or short novels in the nineteenth century, which he analyses. It can only be speculated why he did not use information about literary competitions in the nineteenth century – maybe because of the scarcity of sources?
195An important question is whether it would be more appropriate to distinguish the novel from other, shorter forms of narrative prose not on the basis of text length but using structural and content-related criteria. Usually, the novel is described as a complex form of narration, while the shorter text types are characterized as simpler, single-stranded forms. According to general definitions, the novella, for example, is said to present an exemplary story with one central event, with a closed structure and only a minor elaboration of the characters’ life. The short story is characterized by a relative unity of place, time, and plot. The latter is usually limited to the representation of single events and has an abrupt ending. The characters tend to be typified. In the novel, in contrast, several parallel storylines and subplots, changes of place and time, and fully elaborated characterizations are more common. These structural and content-related aspects are, of course, also induced by the extent of the form (Fludernik 2009, 632Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.; Strube 1993, 21Strube, Werner. 1993. Analytische Philosophie der Literaturwissenschaft. Untersuchungen zur literaturwissenschaftlichen Definition, Klassifikation, Interpretation und Textbewertung. Paderborn: Schöningh.; Zymner 2017, 371–380Zymner, Rüdiger. 2017. “Narrative Gattungen.” In Grundthemen der Literaturwissenschaft: Erzählen, edited by Martin Huber and Wolf Schmid, 365–383. Berlin: De Gruyter.). Ultimately, the complex interplay of the different factors would have to be taken into account to determine to which genre a narrative prose text belongs because none of the criteria is in itself sufficient. The use of general generic definitions is problematic, though, because they do not take into account the cultural and historical context.
196It is questionable whether the novella, for example, was a common genre in literary production in Spanish America in the nineteenth century at all, and even if it was, it is doubtful whether the above-mentioned characteristics would have applied. While novels and short stories can often be distinguished based on the works’ subtitles (“novela” versus “cuento”)130, there is no distinctive term for short novels in Spanish. They are often called “novela”, as well, and sometimes “novelita” or “novela corta” (Mata 1999, 32–33Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.).131 Many short novels were produced in Argentina, Mexico, and Cuba in the nineteenth century. Some were published independently in book form132, some as part of collections of several shorter narrative texts133 and the majority in journals (Mata 1999, 29Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.; Molina 2011, 58–59Molina, Hebe Beatriz. 2011. Como crecen los hongos. La novela argentina entre 1838 y 1872. Buenos Aires: Teseo.). In his account of the nineteenth-century short novel in Mexico, Mata states that short novels were among the first kind of narrative texts which were published a lot in journals shortly after the country’s independence. He characterizes them as generally not having much literary value and not having been designated with the term “novela corta”, which was practically unknown in the early nineteenth century. Many of the terms that were used in the titles of the texts point to the preliminary character of the works: “pequeña novela”, “esbozo de novela”, “proyecto de novela”, “esquema de novela”, “tentativa de novela”, “ensayo de novela”, “apuntes para una novela”, etc. (Mata 1999, 32–33Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). Mata relates these titles, as well as the fact that many shorter novels were simply called “novela”, to the problem of the missing term for the intermediate narrative genre, which on the other hand, already existed in other languages. According to him, the term “novela corta” only became common in the Iberian Peninsula and Mexico towards the end of the nineteenth and the beginning of the twentieth century, an observation which can be confirmed by analyzing the works consulted for the bibliographic database (Mata 1999, 33Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.).134 Towards the end of the century, short novels gained prestige, especially in the context of the Modernismo current (Mata 1999, 143Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). Mata argues that all these texts of intermediate length should be treated as “novelas cortas”, understood as a genre between the short story and the novel, which existed from the early nineteenth century on but has been neglected by literary critics and historians (Mata 1999, 139Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). When defining this short novel in the first chapter of his book, he refers to Walter Pabst’s study “Novellentheorie und Novellendichtung”, an account of the origins of the European novella in Romance languages (Mata 1999, 11–12Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.). From a taxonomic perspective, this may make sense, as all of these narrative texts are of intermediate length, but if genre is understood as an historico-cultural phenomenon, it would have to be analyzed if there is a direct relation between the early “novelitas” and the European novellas at all. Mata’s argument that the early short novels were the protagonist of the initial period of the Mexican (national) narrative (Mata 1999, 141Mata, Óscar. 1999. La novela corta mexicana en el siglo XIX. México: Universidad Nacional Autónoma de México.) – in their capacity as first attempts towards the genre “novela”, fostered and popularized by the press – seems more likely. Nevertheless, it would have to be examined in detail to what extent authors, readers, editors, and critics of the time understood the early short novels as representatives of the genre novella. For the later short novels, this link would equally have to be discussed, although there is certainly more awareness for the “novela corta” because the term is used more often. Even so, novels, in general, tended to be shorter again, making it difficult to differentiate between “novela” and “novela corta”.135
197To conclude, the short novel is not easily recognizable as an independent genre with a certain coherence in Argentina, Cuba, and Mexico in the nineteenth century. Furthermore, there are reasons to consider many of the shorter novels as novels, as well.136 Therefore, in this dissertation, neither the lower limits for the novel set by Forster (50,000 words) nor by Mata (35,000 words) are used. Instead, an own limit of words was deduced from bibliographic descriptions of novels, taking into account the extent of the texts in conjunction with historical subgenre labels in order to approximate the minimum and the typical length of a novel for contemporary authors and editors. Of course, not all the novels were labeled as such, but the majority were, which makes it possible to arrive at a better understanding of the extent of the texts belonging to the genre in their time. The term “novela” is understood as designating novels, not novellas, despite exceptional cases where it is clearly used in the latter sense.137 Works with the subtitle “novela corta” or “novelita” were excluded from the calculation.
198In principle, it would have been possible to also use structural and content-related criteria to select texts for the corpus, but this would not have been very efficient because an application of these criteria would have presupposed either access to detailed summaries of the texts or a close-reading of all the texts. To be able to decide upon the inclusion of texts into the bibliography, again, either detailed summaries or the full texts of all eligible works would have had to be accessible, which was not the case. Furthermore, the use of structural and content-related criteria would have presupposed established definitions of the various narrative genres, which, especially for the Spanish-American short novel, are not available. The extent of the text, in contrast, is usually part of bibliographic descriptions of the works and is a piece of information that is easy to access. It is therefore used as a proxy here to distinguish between novels and other shorter types of narrative prose texts.
199The unit chosen here to measure the extent of the texts is the
number of words. For each eligible text that is accessible in a full-text
format of good quality,138 this
number was accessed with a simple regular expression counting all the tokens
separated by non-word characters (such as white space or punctuation
marks).139 With this
approach, complex linguistic structures like compounds or words with clitics
are not assessed, but this is acceptable because the focus is on the
comparability of text length and not on the linguistic characteristics of
the texts. For the entries in the bibliography, the number of pages was used
and converted to an estimated number of words. One hundred pages were
selected randomly from 50 different nineteenth-century Spanish-American
novels to identify an average number of words per page and to balance out
differences in layout, typesetting, and font. The words on these pages were
then counted.140
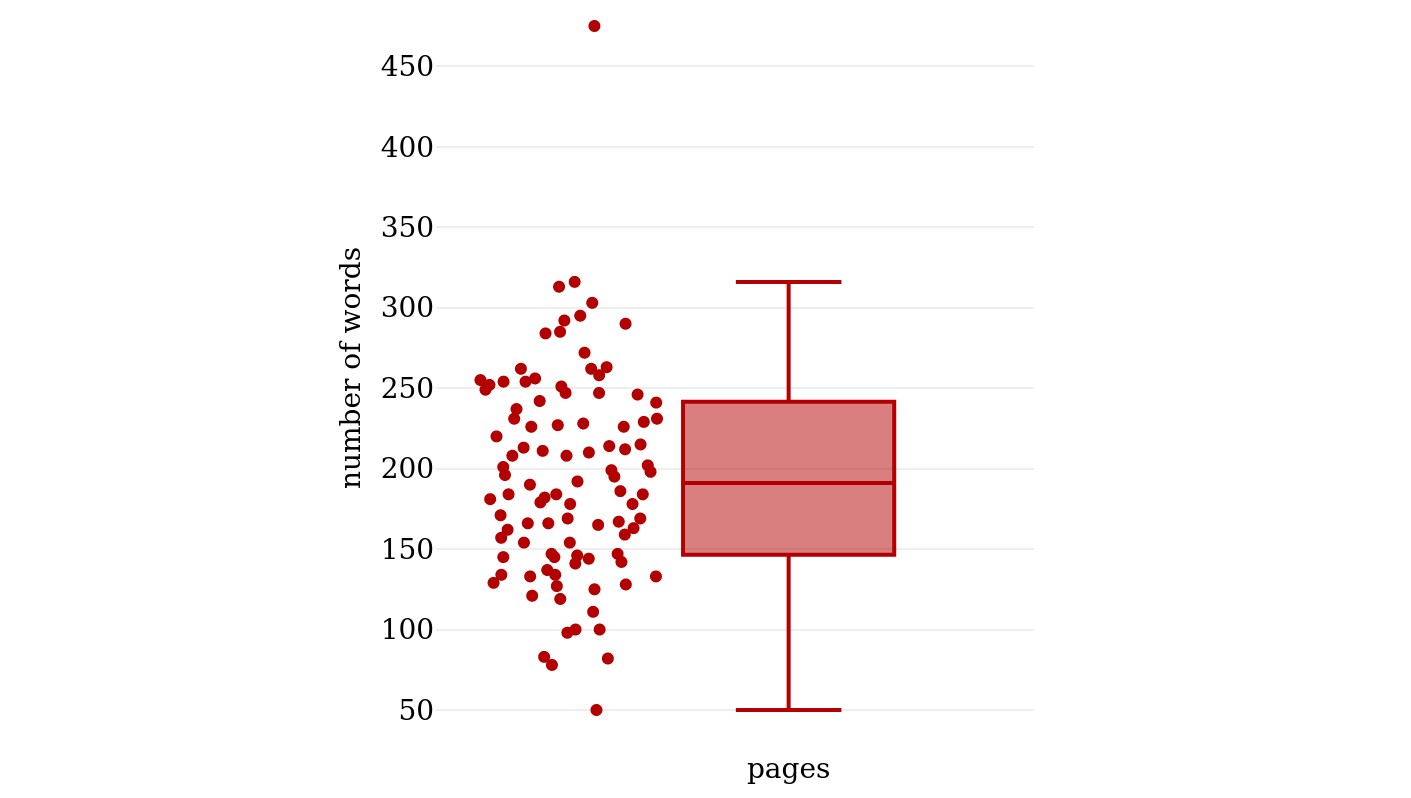
Figure 3 shows the distribution of
the number of words per page for the random sample.141 The number of words per page ranges
from 50 to 475, with a median of 191 words. In the following, this median is
used to estimate the number of words of a text with a known number of pages.
200To examine the range of lengths of nineteenth-century
Spanish-American novels, 129 full texts and 252 bibliographic entries of
works carrying the label “novela” either directly in the title or subtitle
or in the title or subtitle of a series to which the work belongs were
analyzed.142 In the case of the full texts, the words were counted. For
the bibliographic entries, the number of pages was converted to a number of
words using the median number of words per page.143 The results for the
full texts, the bibliographic entries, and both combined are displayed in
figures 4, 5, and 6,
respectively.144 All the distributions have a pyramidal
form which means that they are right-skewed: the higher the number of words,
the fewer works carrying the label “novela” there are, or, in other words,
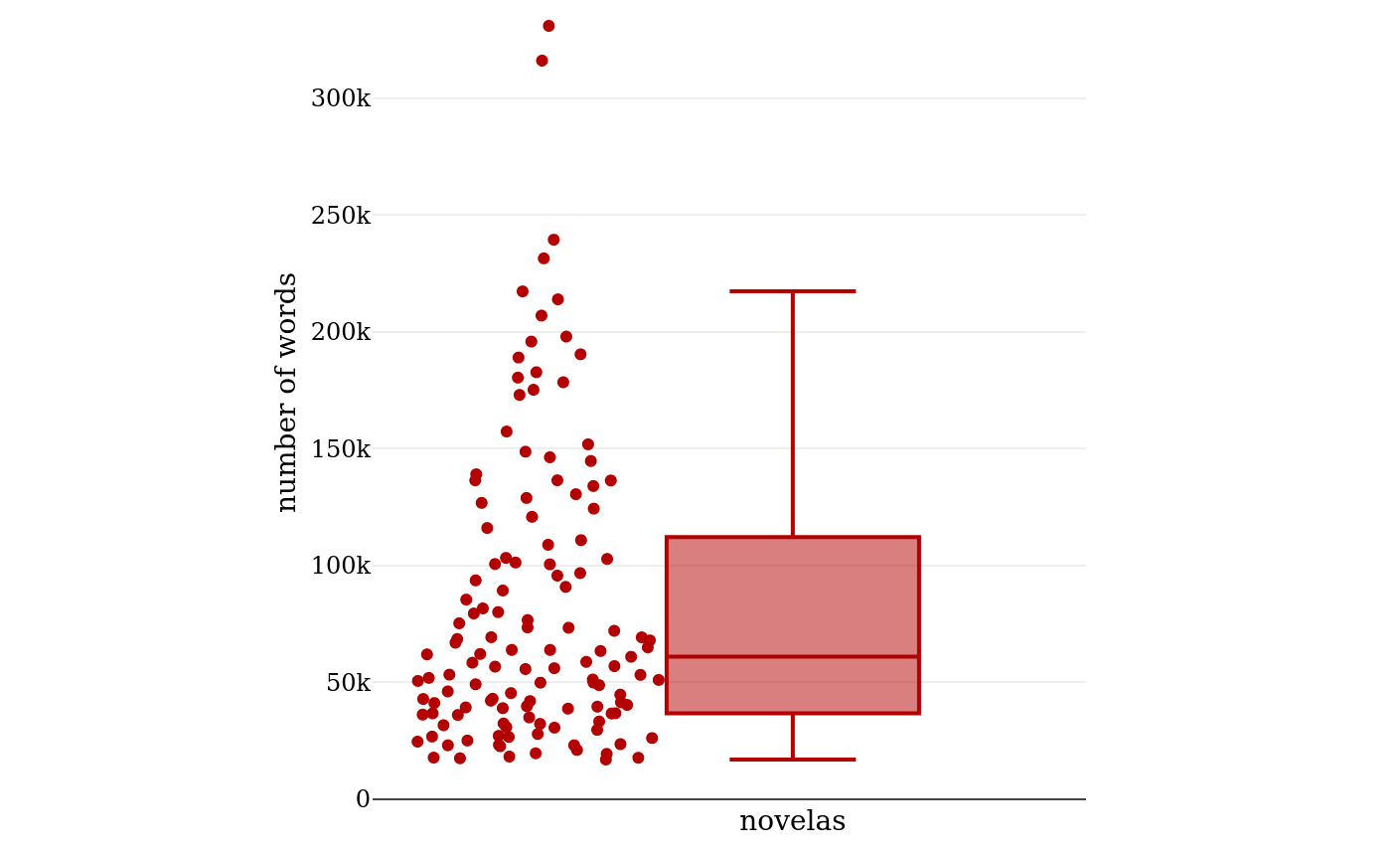
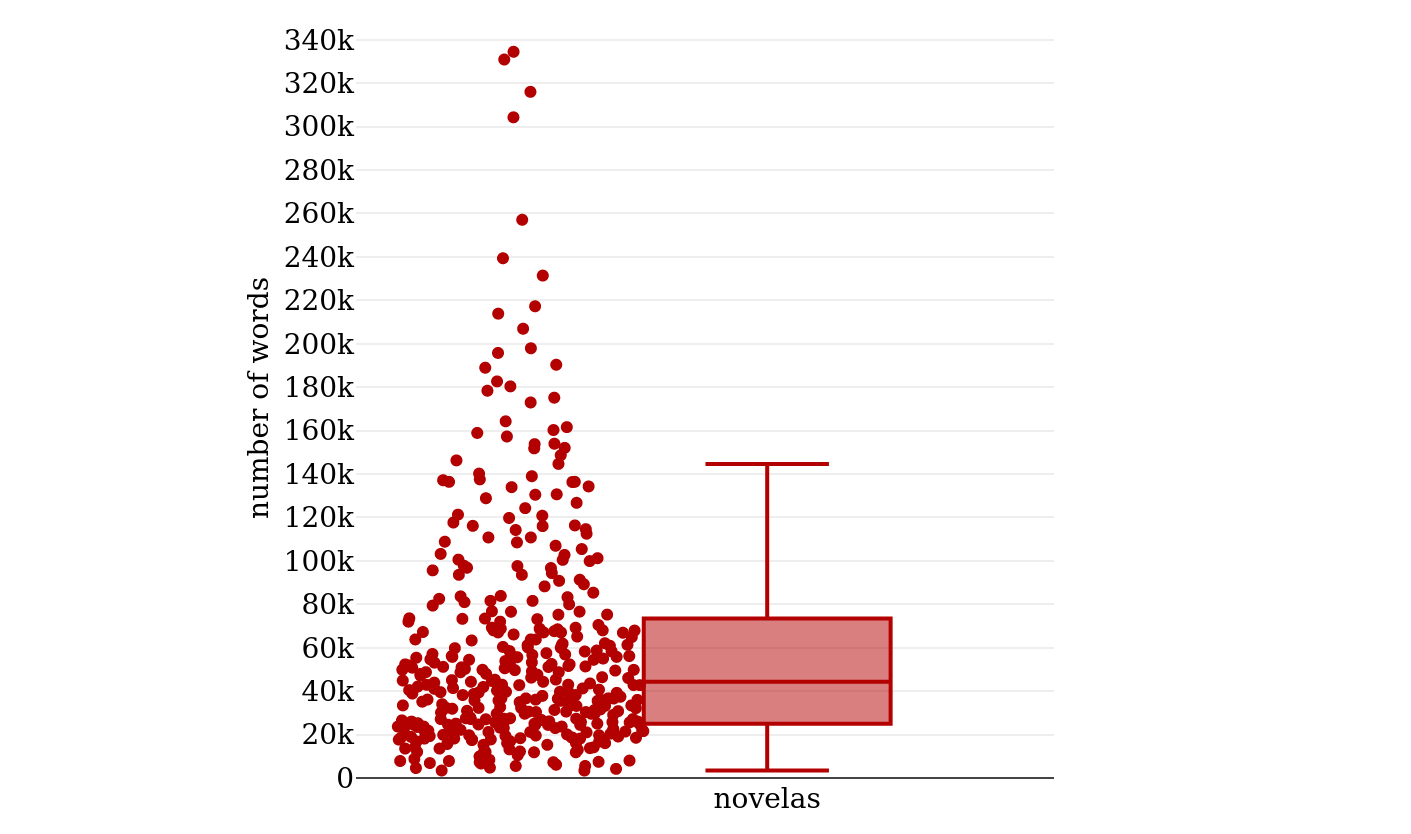
most of the “novelas” are rather short.145 Looking at the numbers, the
shortest novel in figure 5 has 3,438 words, and the longest one 334,441,
which is almost a hundred times as long, so the spectrum of lengths is very
large. The median is at 44,000 words, the first quartile at 25,000 words,
and the third quartile at 73,000 words.146 With a lower limit of 50,000 words as
proposed by Forster, more than half of the “novelas” would be left out, and
with Mata’s limit of 35,000, still more than one-fourth of them would be
considered short novels.
201Based on these results, the question remained where to make a
cut-off. It did not seem reasonable to include all the texts with the same
length as the shortest “novelas”, as these are only about 20 pages long, so
they clearly overlap with novellas and longer short stories.147 In these cases, a recourse to structural and content-related
criteria would have been indispensable to be able to differentiate between
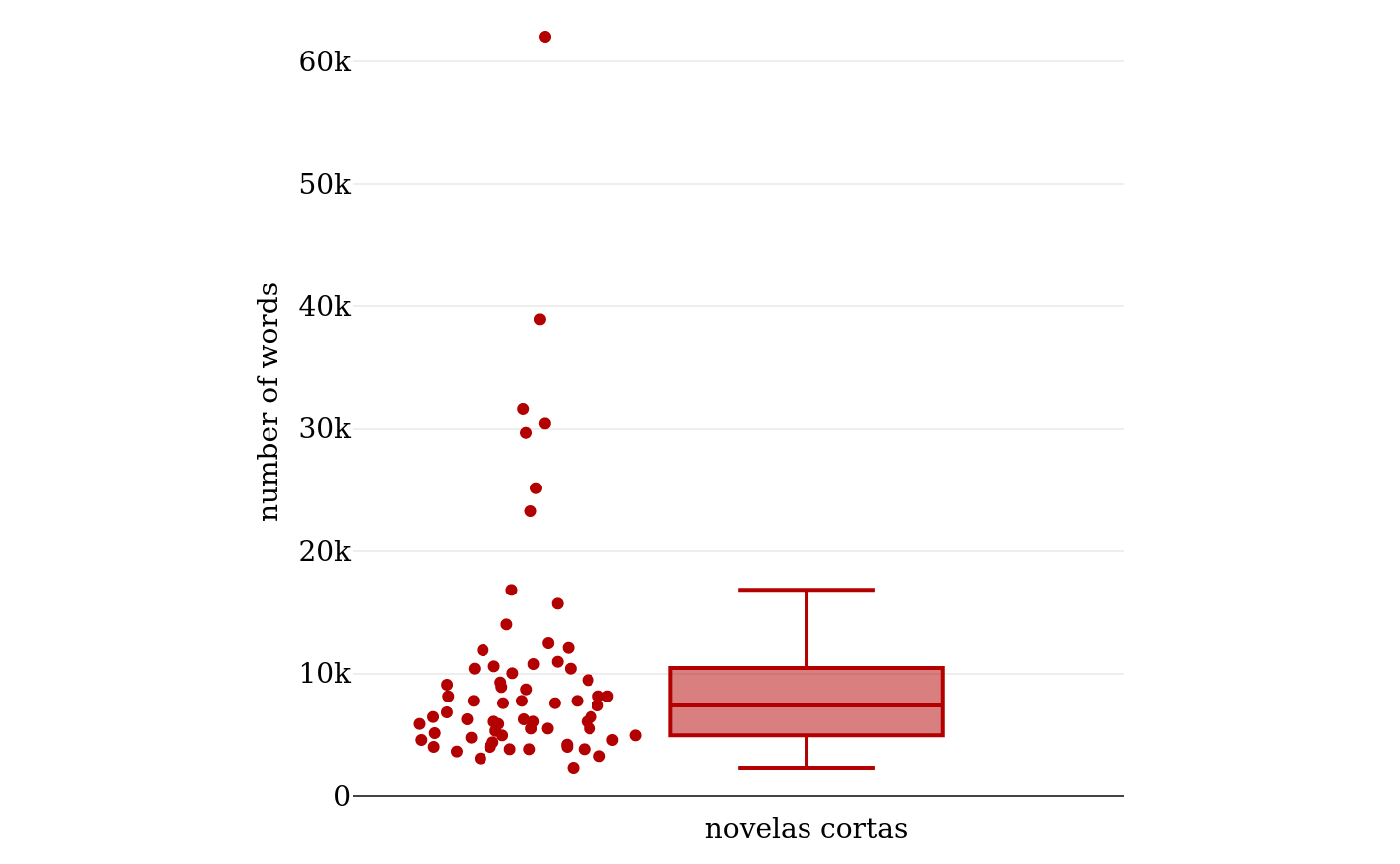
the genres. It was helpful to look at the length of texts explicitly labeled
as “novela corta” to define a lower word limit. Figure 7 shows the distribution of word lengths of
65 “novelas cortas”.148 Again, the shorter texts dominate, with a few
outliers of greater length. The median for the short novels is around 7,300
words, the first quartile at 4,900, the third quartile at 10,400, and the
upper fence at 16,800 words.149
202Cutting off the “novelas” at the first decile – meaning that the shortest 10 % are left out – leads to a value of 16,000 words as a minimum150, which is very close to the upper fence of the “novelas cortas”. That way, exceptionally long “novelas cortas” are included, while “novelas” of the same length as typical “novelas cortas” are excluded. Reformulated in page numbers, the limit amounts to 84 pages.151 In this dissertation, the word limit was used to select texts for the corpus, and the page limit for the selection of entries for the bibliographic database.152 To be independent of the naming conventions again, all fictional narrative texts in prose of this length were included.
203Of course, this cut-off is still arbitrary to a certain extent – why should a “novela” with 15,000 words or 79 pages be excluded, but a “novela corta” with 16,000 words or 84 pages be included? It is nevertheless a limit deduced on the basis of empirical data from the same cultural-historical context as the works to be analyzed, which makes it probable that it approximates the generic conventions of the time. Furthermore, no clear cut could be seen in the data, the transition from very short to longer novels being rather fluent so that every other limit would have led to a similar arbitrary split. In addition, a numeric criterion is directly usable in a quantitative study without the need for extensive close reading.
204In some definitions of the novel, an independent publication as one or sometimes several books is mentioned as one of the characteristic traits of the texts belonging to the genre (Fludernik 2009, 627Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.; Steinecke 2007, 317Steinecke, Hartmut. 2007. “Roman.” In Reallexikon der deutschen Literaturwissenschaft, edited by Klaus Weimar, Harald Fricke, and Jan-Dirk Müller, 317–323. Berlin, New York: De Gruyter.). However, an independent publication will not be required here in order to select texts for the bibliography and the corpus for several reasons. First, the publication of a work as one or several independent books depends to a certain extent on the length of the text. As discussed in the previous subchapter, many of the nineteenth-century Argentine, Cuban, and Mexican novels were quite short and were sometimes published in a volume together with other works, especially when the authors wrote a whole series of novels, for example, the “Entretenimientos literarios” (1843–1844, CU) by Virginia Felicia Auber de Noya or the “Episodios nacionales mexicanos” (1902–1903, MX) by Victoriano Salado Álvarez. Shorter novels were also published in collections of works of various narrative genres, such as the “Panoramas de la vida” (1876, AR) by Juana Manuela Gorriti. Second, the publication in book form corresponds to a particular model of distribution for literary works, which was not the only one in nineteenth-century Spanish America. A large part of the novels was published in journals and literary magazines, many of them in serial form.153 Not all of these novels were also published in book form afterward. Whether a contemporary or modern monographic publication exists also depends on the degree of canonization of a work. As the present study aims to include as many novels as possible so as to broaden the empirical basis for the description and analysis of subgenres of nineteenth-century Spanish-American novels, no restrictions are made regarding the form of publication of a work.154
205However, an independent publication in book form is also not just a practical matter related to text length and modes of distribution. Although the question of a novel’s unity and delimitation is not easily answered by requiring it to be published independently, this still emphasizes its autonomy as a work of art. As discussed in the section on length above, very short novels published in book form existed. On the other hand, there are also novelistic works which are so long that they do not fit into one physical volume. These are often published in several books called “tomos”, for example, the first book editions of “El fistol del diablo” (1859–1860, MX) by Manuel Payno with four or “Amalia” (1855, AR) by José Mármol with eight volumes. In the case of sequels and cycles published as several books, it is less obvious if each part should be considered its own novel or if they form one novel altogether. Often, the connection between the texts is indicated in titles and subtitles, as the following examples illustrate:
206In the first case, some aspects point to the unity of the work (that the first volume has the same title as the whole cycle, “Libro extraño”, and that the volumes are called “tomo” like different physical volumes of the same novel in other cases). In contrast, others emphasize the independence of the different parts (that the parts have their own title from the second volume on and that they were all published, and thus probably written and finished, in different years). In the second case, all the parts have a common “supertitle”, “Dramas militares”, they are all published in the same year, and each sequel refers to the previous part(s). Even so, all the parts also have their individual title. In the third case, the title of the first novel does not convey any information about a superordinate work, but the subtitle of the second novel indicates that it is a sequel to the first one. These two works were published in subsequent years. In the last case, all the books are numbered parts of the common superordinate title “Pepa Larrica”, and they were all published in the same year, suggesting a united work. A factor complicating the decision in all of these cases is that none of them includes the label “novela”.
207As a rule of thumb, a work is considered an independent novel here if it has its own title (and optionally a subtitle indicating the genre) that is not a subtitle of a part (such as “Primera parte: El prólogo de un gran libro”, “Segunda parte: La víspera de un gran día”, etc.), if it has its own structure starting with a first chapter and optionally ending with a trailer indicating the end of the work (e.g., “Fin”, “Fin de la obra”), and if it is optionally published in one or several independent books. These parameters are easy to determine not only for texts that are eligible for the corpus but also for bibliographic entries because viewing the table of contents is enough to decide, and no close reading of the full text is needed.158
208Following this rule, the parts of the first three cases above are all considered individual novels, while the fourth case as well as the different parts of a work published in several volumes but all carrying the same title, such as “El fistol del diablo” o “Amalia”, are considered one novel. Thereby, the decision of an author (or editor) to publish a novel with its own title in an independent book is, by and large, respected. The relationship between different parts of a novelistic cycle should, however, not be ignored because it can be expected that there are similarities in content and style that influence the results of an analysis of a whole corpus of novels: it is very probable that these works are closer to each other when compared to other independent works. It can also be assumed that the degree of similarity varies according to the closeness of the parts. The books of “Libro extraño” probably have a stronger stylistic relationship than the different parts of a more extensive and looser series such as the ten novels of “La linterna mágica. Colección de pequeñas novelas / Colección de novelas de costumbres mexicanas” (published between 1871 and 1892, MX) by José Tomás de Cuéllar or the thirteen “Leyendas históricas de la independencia” (published between 1886 and 1913, MX) by Ireneo Paz. The existence of cycles and series of novels with different degrees of connectivity is another factor contributing to the great variance of the genre novel in terms of extent which also a quantitative analysis has to deal with. With the decisions made here, a short novel of around 15,000 words is compared to a novel of several hundreds of thousands of words and both to individual parts of sequels of varying length. If text length is not taken into account in the calculations, several shorter parts of a sequel have more influence on the results than a very long novel considered as one. This must be remembered when analyzing the results of the stylistic analysis.
209Applied to texts not published independently, the rule of thumb leads to the following decisions: a novel published in a journal, possibly in serial form, is considered one work if it has its own title and structure. Such a work is considered finished if all the existent parts are included, and if there is no obvious interruption of the structure.159 Likewise, shorter novels included in collections are treated as individual works if they fulfill the above criteria.160 On the other hand, collections of short stories published independently are excluded because each work contained in them has its own title and, eventually, its own structure.161 Generally, only novels published for the first time between 1830 and 1910 are included.162
210So far, only the very general formal criteria of fictionality, narrativity, prose, length, and form of publication were discussed to select texts for the corpus of novels. Although it is intended not to restrict the definition of the novel much further so as not to exclude texts of certain novelistic subgenres from the beginning, two additional criteria going beyond the form are discussed here. The first one refers to the target readership of the novels. In the bibliography and corpus used in this dissertation, only novels written for adults are included. There are also some novels written especially for children which were published between 1830 and 1910 in the three countries of interest here.163 Although small in number, these are not considered because it is assumed that the target readership influences the writing style, and if they were included, children’s literature would be another influencing factor that would have to be taken into account.
211The second additional criterion is a realistic representation of characters and setting, which has been adduced as an important factor in the definition of the novel in order to distinguish it from epic narrative texts and romances. The latter are characterized by mythical heroes and vague and exotic mythical sceneries (Fludernik 2009, 628–629Fludernik, Monika. 2009. “Roman.” In Handbuch der literarischen Gattungen, edited by Dieter Lamping and Sandra Poppe, 627–645. Stuttgart: Kröner.). This criterion does not necessarily hold for all subtypes of the novel, for example, historical, fantastic, and science fiction novels. Nonetheless, it is helpful to exclude some texts which are very far away from the prototypical realistic novel. In this dissertation, texts with non-realistic elements are included as long as these do not dominate the text and as long as the other selection criteria for novels are fulfilled. Two texts that are sometimes included in bibliographies and representations of the nineteenth-century Spanish-American novel are excluded here: “Peregrinación de Luz del Día o Viaje y aventuras de la Verdad en el Nuevo Mundo” (1871, AR) by Juan Bautista Alberdi and “Los dioses de la Pampa” (1902, AR) by Godofredo Daireaux.164 The protagonist of “Peregrinación de Luz del Día” is the allegorical figure “Verdad” who travels to America to flee from the political and social conditions in Europe. This work has been characterized as a satire, a philosophical dialogue, a novelized allegory, or an allegorical novel (Lichtblau 1997, 16Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.; Molina 2011, 403Molina, Hebe Beatriz. 2011. Como crecen los hongos. La novela argentina entre 1838 y 1872. Buenos Aires: Teseo.). It is excluded here because the protagonist is not realistic. In “Los dioses de la Pampa”, Apollo and the Muses travel to Buenos Aires hoping to find the “new Athens”. Disappointed because the arts are disregarded in this big city, they return to Greece. Before leaving, they only catch a glimpse of the Pampa, whose unbeknown, natural gods are presented in the main part of the book and are affiliated with the birth of the Argentine Republic. Because also this text has allegorical traits and, furthermore, no coherent plot, it is excluded, as well.
212If one summarizes the selection criteria outlined in the previous sections, the following working definition of the novel can be set up for the present study:
213A text is considered a novel if:
214This definition of the novel is, on the one hand, general, because some of its elements (fictionality, narrativity, prose, realistic representation) correspond to characteristics mentioned in other general definitions of the novel, as well. On the other hand, it is context-specific because the length and publication criteria were derived from the pool of historical texts considered here. The adult readership criterion is one that is probably not critical in general definitions of the novel but that is included here to avoid stylistic outliers. However, as could be seen in the previous sections, even the general criteria need to be interpreted and broken down into specific paratextual and textual markers in order to be applicable to individual texts in a specific historical and cultural setting.
215This definition is conceived as classificatory, which means that all the conditions should be met by a text to be considered a novel. That way, clear decisions can be made to include texts into a general corpus of novels, which in turn sets the frame for the analysis of subgenres. Inside this classificatorily defined corpus, alternative definitory concepts of (sub)genre(s) are examined.
216This study aims to contribute to the research of subgenres of the novel in Spanish America beyond one specific regional and national context. Therefore, novels from three countries were chosen: Argentina, Cuba, and Mexico. There is a tradition of scholarship concerned with the literature of Latin America or Spanish America as a whole. Usually, “Latin America” includes the countries where the Spanish and Portuguese languages dominate165 while “Spanish America” concentrates on the predominantly Spanish-speaking countries. Several histories of literature and research on the novel exist for these regions.166 However, it can be discussed to what extent it makes sense to speak of “the Spanish-American novel” in the nineteenth century. In general, the literary histories and books on the subject present the nineteenth-century Spanish-American literature (and novel) as a comparison or juxtaposition of the developments in the different countries or regions of neighboring countries such as the Caribbean or Andean countries.167 The differentiated expositions indicate that the common denominator “Spanish-American” is, above all, a retrospective label summarizing individual histories of national or regional literatures and that it does not reflect a coeval self-conception and common literary system. Indeed, literature and especially the novel, had an important function in the consolidation of the nations (Brushwood 1966Brushwood, John S. 1966. Mexico in its Novel. A Nation’s Search for Identity. Austin: University of Texas Press.; Sommer 1993Sommer, Doris. 1993. Foundational Fictions. The National Romances of Latin America. Berkeley: University of California Press.). It was only towards the end of the nineteenth century, with the advent of the Modernismo current, that the awareness of a common literature evolved clearly:
Zu einem der entscheidenden Merkmale des hispanoamerikanischen Modernismo wird, daß er von Anbeginn ein kontinentales Selbstverständnis entwickelt. Seit den Jahren der Unabhängigkeitskämpfe zu Beginn des 19. Jhs., als Andrés Bello in seinem Londoner Exil mit dem nie vollendeten Gedicht América eine eigene hispanoamerikanische Literatur begründen wollte, hatte es ein solches Selbstverständnis nicht mehr gegeben. Nun trat in Hispanoamerika erneut eine Literatur auf, die beanspruchte, eine Literatur des ganzen Kontinents zu sein. Damit fügte sie sich in ein wachsendes Interesse für Iberoamerika bzw. Lateinamerika, wie es seit der Mitte des Jahrhunderts zunehmend genannt wurde, als Ganzes ein, das die kultur- und geschichtsphilosophische Diskussion des Kontinents bestimmte. (Rössner 2007, 207Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.)
217From a comparative perspective, it is nevertheless productive to analyze the subgenres of the novel in several nineteenth-century Spanish-American countries together. Even if there is no shared self-conception of literature throughout the whole century and even if there are no direct historical links in the literary communication and the formation and practice of the subgenres between all the countries and regions, there are still similar historical conditions and indirect connections triggering parallels. As Olea Franco, who examines a series of Spanish-American narrative texts from different countries from the early nineteenth up to the early twentieth century, states: “Creo que mi propia exposición, si bien discontinua, mostrará que en nuestra literatura se produce un diálogo cultural que propicia una unidad de sentido global, tanto en la generación de los textos como en su recepción crítica” (Olea Franco 2011, 25Olea Franco, Rafael. 2011. “Narrativa e identidad hispanoamericanas. De Fernández de Lizardi a Borges.” In La literatura hispanoamericana, edited by Julio Ortega, 23–134. La búsqueda perpetua: lo propio y lo universal de la cultura latinoamericana 3. México: Secretaría de Relaciones Exteriores, Dirección General del Acervo Histórico Diplomático.). For Olea Franco, a central aspect of the Spanish-American identity lies in the cultural and, in particular, the linguistic Spanish heritage. Through their language, narrative texts make aesthetic proposals that constitute an implicit or active reflection on cultural identity. In addition, by choosing a topic and a genre for their texts, authors propose in which cultural tradition they expect them to be read (25–26Olea Franco, Rafael. 2011. “Narrativa e identidad hispanoamericanas. De Fernández de Lizardi a Borges.” In La literatura hispanoamericana, edited by Julio Ortega, 23–134. La búsqueda perpetua: lo propio y lo universal de la cultura latinoamericana 3. México: Secretaría de Relaciones Exteriores, Dirección General del Acervo Histórico Diplomático.). In the context of the Spanish-American independence movements, the Creole elites had the common task of liberating themselves from the colonial heritage in their search for autonomy. A way to achieve an independent literature was to integrate modes of expression coming from the diverse American realities (28–29Olea Franco, Rafael. 2011. “Narrativa e identidad hispanoamericanas. De Fernández de Lizardi a Borges.” In La literatura hispanoamericana, edited by Julio Ortega, 23–134. La búsqueda perpetua: lo propio y lo universal de la cultura latinoamericana 3. México: Secretaría de Relaciones Exteriores, Dirección General del Acervo Histórico Diplomático.).168 The choice of topics and genres also contributed to this goal, for example, the description of regional settings, customs, and types and of local and national (contemporary) historical events in the novelas de costumbres and the novelas históricas, the two subgenres most frequently mentioned explicitly in the subtitles of the novels in the three countries considered here.169 On the other hand, the emerging Spanish-American national literatures all integrated European models (genres, topics, and also stylistic preferences) into their repertoire, so they had similar points of reference, for example, for the romantic sentimental novel, the realist, and naturalistic novels (Cárrega 1986, 49–69Cárrega, Hemilce. 1986. Las novelas argentinas de Carlos María Ocantos. Buenos Aires: Febra Editores.; Navarro 1955, 9–12Navarro, Joaquina. 1955. La novela realista mexicana. México: Compañía General de Ediciones.; Schlickers 2003, 27–51Schlickers, Sabine. 2003. El lado oscuro de la modernización: estudios sobre la novela naturalista hispanoamericana. Madrid, Frankfurt: Iberoamericana/Vervuert.; Varela Jácome [1982] 2000, 12Varela Jácome, Benito. (1982) 2000. Evolución de la novela hispanoamericana en el siglo XIX (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmct14z8.). So for most of the nineteenth century, the “Spanish-American novel” can be conceived as a frame of a common colonial historical background, similar strategies to develop national novels and related literary influences until a supranational Spanish-American literature begins to emerge. The interest in comparing subgenres of the novels from different countries and regions lies in the possibility to examine the structure of trans-regional similarities and local differences and to analyze it as a pre-phase to a continental literature.
218The countries Argentina, Cuba, and Mexico were chosen because, within the common frame of their colonial heritage, they represent different regions of Spanish America with different geographical and cultural backgrounds and economic, historical, and political developments, which are reflected in the novelistic production, including the different subgenres of the novel. A second reason for the choice of these countries is that their capitals already were or evolved into important cultural centers during the nineteenth century, leading to a great number of novels published there.170 In addition, there were also novels written by Argentine, Cuban, and Mexican writers and published elsewhere.171 In the following, the three countries are characterized briefly regarding historical and socio-economic aspects that had an effect on the number and kinds of novels written in them during the nineteenth century.
219Argentina belonged to the Viceroyalty of Peru until 1776 when the Viceroyalty of the Río de la Plata was founded, and Buenos Aires became its capital. At that time, Buenos Aires was still a small town but strategically important because of its position at the mouth of the Río de la Plata. However, because of the lack of precious metals, the region was rather neglected and only sparsely settled. The economy remained primarily agrarian during the colonial period. Moreover, the territory belonging to the Río de la Plata region was vast and included extensive rural and unexplored areas such as the Pampa and Patagonia (Lichtblau 1959, 13–21Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.). The contrast between the backcountry and Buenos Aires, which evolved into a big city and a political, economic, and cultural center in the course of the nineteenth century, influenced the types of novels written by Argentine writers. On the one hand, the economic and social life of the capital was a main topic in many realist and naturalistic novels written towards the end of the century. For example, the role of immigrants in the metropolitan society was discussed because, unlike in many other Spanish-American countries, Argentina’s population was predominantly of a European background. On the other hand, rural life was depicted in gaucho novels (136–184, 19, 121–135Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.). The nation’s political development was also taken up in the novels. Not long after Argentina’s declaration of independence in 1816 and successive disputes between unitarians and federalists about the organization of the country172, the federalist Juan Manuel de Rosas became the governor of the province of Buenos Aires and established a dictatorial system that persisted until 1852. The Rosas era was the topic in a whole series of novels that depicted its cruelties (Molina 2011, 285–312Molina, Hebe Beatriz. 2011. Como crecen los hongos. La novela argentina entre 1838 y 1872. Buenos Aires: Teseo.; Lichtblau 1959, 15–16 and 43–54Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.).
220Just like Mexico, during colonial times, Cuba belonged to the viceroyalty of New Spain, which was the first administrative region that Spain established in Latin America and which existed from 1535 to 1821. However, Cuba did not become independent with the end of the viceroyalty. It remained a Spanish colony until 1898 (Kahle 1993, 55, 84–85, 95–96Kahle, Günther. 1993. Lateinamerika Ploetz. Die Geschichte der lateinamerikanischen Länder zum Nachschlagen. 2nd ed. Freiburg/Würzburg: Ploetz.). This makes Cuba a special case because its literature is more closely related to the Spanish literature during the nineteenth century than that of the other independent countries. Depending on the point of view, Cuban-Spanish authors are sometimes claimed to be Spanish authors and sometimes Cuban.173 But even before the existence of a Cuban nation-state, there was a Cuban literature, and it contributed to the emergence of a national identity.174 The capital Havana played an important role in this process. The city was founded by the conquerors in the early sixteenth century and became an important trading post from early on. Important cultural institutions such as the colony’s first printing press and the university of Havana were founded there in the eighteenth century (Armas 1997, 235Armas, Emilio de. 1997. “Cuba. 19th- and 20th-Century Prose and Poetry.” In Encyclopedia of Latin American Literature, edited by Verity Smith, 235–242. London/Chicago: Fitzroy Dearborn Publishers.; Zeuske 2002, 20, 28Zeuske, Michael. 2002. Kleine Geschichte Kubas. 2nd ed. München: C. H. Beck.). For the formation of the novel, private literary gatherings that took place in the houses of habaneros from the early nineteenth century onwards were significant.175 In addition, the Cuban literature was also brought forward by emigrated intellectuals (Armas 1997, 235Armas, Emilio de. 1997. “Cuba. 19th- and 20th-Century Prose and Poetry.” In Encyclopedia of Latin American Literature, edited by Verity Smith, 235–242. London/Chicago: Fitzroy Dearborn Publishers.). Social topics and critique were important for the Cuban novel from the beginning onwards as a means for expressing on the cultural level what was not possible on the political one. The novela de costumbres, describing local customs and expressing civic concerns, was a subgenre suitable to this end. A specifically Cuban topic was the problem of slavery. The economy of the country, characterized above all by sugar mills, coffee plantations, and tobacco farming, depended heavily on it. In the novelas abolicionistas, the system of slavery was documented critically in all of its components.176
221When Mexico was conquered by the Spaniards, it was a region populated by many different indigenous people and dominated by the Aztecs, the mexica, whose capital Tenochtitlan was an urban center reflecting the power and cultural development of their civilization. Before, the Maya had had their flowering period in the southern areas of today’s Mexico. The colonial era was characterized by the establishment and maintenance of an administrative system guaranteeing the Spanish hegemony over the vast territory of the viceroyalty of New Spain. This involved missionary work aimed at christianising the indigenous population and also the economic exploitation of the land, especially the mining of silver and agricultural use (Ruhl and Ibarra García 2000, 22–28, 50–55, 66–97Ruhl, Klaus-Jörg, and Laura Ibarra García. 2000. Kleine Geschichte Mexikos. Von der Frühzeit bis zur Gegenwart. München: C. H. Beck.). After Mexico’s independence in 1821, the country struggled for its political consolidation, with alternating periods of opportunistic, liberal, and conservative government. Together with social and economic problems, the political difficulties culminated in the Mexican Revolution, which broke out in 1910 (Ruhl and Ibarra García 2000, 130–131Ruhl, Klaus-Jörg, and Laura Ibarra García. 2000. Kleine Geschichte Mexikos. Von der Frühzeit bis zur Gegenwart. München: C. H. Beck.). The process of political emancipation was closely related to the development of a literary self-conception, which was also reflected in the novels written in the nineteenth century, which took up the cultural, social, and political past and present. The novela indigenista contributed to a revaluation of Mexico’s indigenous past. The historical novels served to denounce abuses of the Spanish colonial power and to highlight the merits of heroes of the independence. Furthemore, contemporary history was thematized and judged with partiality. Types and customs of the middle and lower social strata were sketched in novelas de costumbres. Towards the end of the century, in particular, the currents of realism and naturalism influenced the novelistic production (Rössner 2007, 140–148Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.).
222As can be seen from the above overviews, the three countries chosen for the corpus and analyses of novels here represent different political, economic, and cultural systems with local historical developments. The kinds of novels written in Argentina, Cuba, and Mexico in the nineteenth century are a result of these varying circumstances, but at the same time, they are an expression of a common cultural-linguistic colonial heritage, emancipatory concerns, and similar literary influences. The analysis of the various subgenres of the novel intends to examine how these references are reflected stylistically in the texts.
223In order to select texts for the bibliography and the corpus, it is necessary to decide which novels are associated with which country. The strategy followed here is inclusive and based on two criteria: the first one is the place of publication of a novel, and the second one, the nationality of an author. If the first edition of a novel was published in one of the three selected countries, it is considered to belong to that country. That means that also novels written by authors of another nationality can be included. The place of publication of the first edition is interpreted as a sign that the author is somehow connected to that place. On the other hand, novels whose first edition is published in another country but whose author is Argentine, Cuban, or Mexican are also included. It is assumed that the birth of an author in a country entails that she or he identifies her- or himself with that country in some way. However, also authors who emigrated from another country and became Argentine, Cuban, or Mexican are considered. The content of the texts, in contrast, is not regarded as decisive.177 With this strategy, the Argentine, Cuban, and Mexican literatures are defined geographically as well as culturally. It has the advantage that many special cases are covered, for instance, authors living in exile178, or authors residing abroad for personal or professional reasons.179 In addition, if the first edition of a work is published in one of the countries, it is not necessary to have full biographical information about the authors, which makes it possible to extend the bibliography and the corpus beyond the well-known canon and also to select works written by anonymous authors. Applying the criterion of nationality to Cuban authors during the country’s colonial period requires an explanation. Here, authors are considered Cuban if they were born in the colony or if they spent a considerable lifetime on the island, were involved in its cultural life, and published their works there. In the latter case, the decision is made for each author individually. Finally, it was decided to only treat novels written in the Spanish language and also to omit translations. Works primarily written in another language would have been difficult to process and compare stylistically to the other works. Moreover, another primary language implies that the work is, in the first place, associated with another cultural context, at least linguistically.180
224The chronological limits of this study are set to 1830 and 1910, defining a long nineteenth century, which starts late. The lower limit marks the period of the upcoming national literatures after the wars of independence in the Argentine and Mexican cases and the beginning of the development of national conscience in the Cuban case. The 1820s were not considered because of the scarcity of novels published during that decade.181 1910 was chosen as the last year because it marked the beginning of the Mexican revolution, which gave rise to an own new type of novel. Furthermore, several new literary currents emerged around that date, such as the mundonovismo, involving a counter-movement to Modernism’s cosmopolitanism and avantgardistic movements oriented towards contemporary European art movements (Janik 2008, 109–134Janik, Dieter. 2008. Hispanoamerikanische Literaturen. Von der Unabhängigkeit bis zu den Avantgarden (1810–1930). Tübingen: Narr Francke Attempto.; Meyer-Minnemann 1979, 2–4Meyer-Minnemann, Klaus. 1979. Der spanischamerikanische Roman des Fin de siècle. Tübingen: Niemeyer.; Rössner 2007, 236–238, 263Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.). Most Spanish-American general literary histories and histories of the novel make a caesura around this date.182 Because the development of the novel in nineteenth-century Argentina, Cuba, and Mexico is closely related to contemporary historical events in that it was influenced by them and in that the events were, in turn, reflected in the novels, the political history between 1830 and 1910 is briefly sketched here for the three countries, following existing presentations in literary-historical works.183
225After the end of the River Plate viceroyalty in 1810, Argentina suffered a period of internal conflicts characterized by the dispute between federalists, who favored a system of equally entitled provinces, and unitarians, who sought to establish a hegemonic position of the capital Buenos Aires. The period between 1829 and 1852 was marked by the dictatorship of the federalist Juan Manuel de Rosas, who enforced a political and economic hegemony of the province of Buenos Aires, governed by him, over the other provinces. After the end of the Rosas regime, the country had to be politically reorganized in order to overcome the conflicts between the provinces and to make a unified nation possible. In 1852, Argentina became a federation under the unitarian Justo José de Urquiza, with a constitution adopted in 1853. Yet Buenos Aires joined the federation only in 1860. A civil war broke out, ending in the victory of the forces of Buenos Aires under the command of Bartolomé Mitre, who became the president of the united republic in 1862. This moment initiated a phase of political and social stabilization and economic growth (Lichtblau 1959, 15–21Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.). Between 1865 and 1870, Argentina was involved in the War of the Triple Alliance between Paraguay and the alliance of Argentina, Brazil, and Uruguay, which ended with the defeat of Paraguay. In a military campaign between 1878 and 1884 known as the “Conquista del Desierto”, indigenous people were fought in the Pampa, Patagonia, and the Chaco region with the objective of securing the Argentinian-European dominance in the remote regions. In 1880, Buenos Aires was officially declared the capital of the republic, and the liberal Julio Argentino Roca was elected as president (Kahle 1993, 113–114Kahle, Günther. 1993. Lateinamerika Ploetz. Die Geschichte der lateinamerikanischen Länder zum Nachschlagen. 2nd ed. Freiburg/Würzburg: Ploetz.). Liberal governments stayed in power until 1916, promoting immigration, foreign commerce, and a general economic upswing, interrupted by a severe financial crisis in 1889 and 1890 (Lichtblau 1959, 138–142Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.).
226After the wars of independence, Cuba became the most important Spanish colony. Havana was the most important city of the remaining Spanish empire, and Cuba’s plantation economy satisfied the European demand for sugar, coffee, and other colonial goods. In the first decades of the nineteenth century, the Spanish crown benefited the loyal oligarchy with a reform of restoration. On the other hand, a group of intellectuals and literates advocated for the development of a Cuban national identity and criticized the system of slavery supporting the plantation economy. Furthermore, because of unstable political conditions in the mother country, a new group of annexationists emerged who envisaged the attachment of Cuba to the United States. The fear of a slave revolt was another factor leading to an approximation to the US-American southern states. In the 1840s, different ideas between loyalty, autonomy, annexation, or separation existed for the future of the country (Zeuske 2002, 90–99Zeuske, Michael. 2002. Kleine Geschichte Kubas. 2nd ed. München: C. H. Beck.). In 1868, an attempt by the Cuban bourgeoisie to obtain more political and economic autonomy from Spain failed. This initiated a period of internal wars of independence, lasting until 1898 when the United States provoked the Spanish-American War and intervened in the Cuban struggle for autonomy. Cuba became independent from Spain but remained under the control of the USA. Even the Cuban constitution from 1902 did not bring about true sovereignty because it guaranteed the United States the right to intervene should their interests be at risk. In the following years, Cuba suffered several military interventions by its superior (124–162Zeuske, Michael. 2002. Kleine Geschichte Kubas. 2nd ed. München: C. H. Beck.).
227Like Argentina, also Mexico experienced a period of political agitation after its independence was declared in 1821. The first government was a constitutional monarchy led by Agustín de Iturbide, which was overthrown by the military under the leadership of General Antonio López de Santa Anna in 1823. In the same year, the provinces of Central America (present-day Costa Rica, El Salvador, Guatemala, Honduras, and Nicaragua) declared themselves independent from Mexico. In 1824, Mexico became a republic with a federal constitution, which was replaced by a centralistic organization introduced by conservative forces in 1835. Subsequently, several provinces strove for autonomy, among them the English-speaking colonists in Texas. After the Mexican-American war from 1846 to 1848, Mexico lost considerable territory to the United States of America. In 1855, an era of reform began when the liberals defeated the military strongman Santa Anna, who had dominated the political events since the 1820s. It was intended to lead to economic growth and political strength, but anticlerical and -military actions triggered the resistance of the conservatives. A civil war between 1858 and 1861, which was won by the liberals, led to further measures against the Church. Moreover, a planned moratorium on foreign debt provoked a French intervention at the end of 1861, which in turn resulted in the establishment of an empire governed by the Austrian archduke Maximilian von Habsburg. However, this monarchical system lasted only until 1867 when it was ended by the liberal troops under Benito Juárez. The presidency of Juárez marked the beginning of a period of modernization and reconstruction of the society and the economic system. It was continued by Porfirio Díaz, but his measures of domestic and foreign policy neglected the middle class and rural population, leading to social protest that culminated in the Mexican Revolution breaking out in 1910 (Rössner 2007, 137–140Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.; Ruhl and Ibarra García 2000, 130–166Ruhl, Klaus-Jörg, and Laura Ibarra García. 2000. Kleine Geschichte Mexikos. Von der Frühzeit bis zur Gegenwart. München: C. H. Beck.).
228The historical developments in the nineteenth century in Argentina, Cuba, and Mexico show that all three countries had to go through a longer period of political turbulences, economic stagnation, and social problems before a consolidation of the nations was reached. For Argentina and Mexico, relative stability was achieved from the middle of the century onwards, while a Cuban nation-state was not yet fulfilled. The respective historical circumstances affected the cultural life and, thereby, also the production of novels. When one looks at the numbers of novels included in the bibliography, connections to the historical developments in the countries can be assumed. In Argentina, the number of novels written increased moderately after 1851 and considerably after 1880, coinciding with the beginning of the liberal government of Roca. A slight decrease can be noted in the 1890s and 1900s. This might be related to the financial crisis of 1889 and 1890 but also to the prevalence of the Modernismo current that focused on other genres, especially poetry and short prose texts. In Mexico, the production of novels took off in the 1860s, increasing almost steadily until the 1900s. Apparently, the French intervention in the 1860s did not have a negative impact on the publication of novels, and the presidencies of Juárez and Díaz provided conditions that were favorable for it. The development of the number of Cuban novels is not that clear. Most novels were published in the 1850s. Beyond that, there are slight ups and downs, but no clear increase over time is visible, and the overall number of novels is lower than in Argentina and Mexico. This suggests that Cuba’s status as a colony and the struggle for independence breaking out openly in 1868 held back the development of the novel in that country.184 Besides influencing the number of novels published, the contemporary political-historical events and social, economic, and political issues of the time supplied thematic material for many novels and contributed to the formation and adaptation of some subgenres of the novel, for example, historical novels treating contemporary issues or the anti-slavery novel (Brushwood 1966Brushwood, John S. 1966. Mexico in its Novel. A Nation’s Search for Identity. Austin: University of Texas Press.; Lichtblau 1959, 43–54, 121–135, 138–143Lichtblau, Myron I. 1959. The Argentine Novel in the Nineteenth Century. New York: Hispanic Institute in the United States.; Molina 2011, 285–375Molina, Hebe Beatriz. 2011. Como crecen los hongos. La novela argentina entre 1838 y 1872. Buenos Aires: Teseo.; Rivas 1990Rivas, Mercedes. 1990. Literatura y esclavitud en la novela cubana del siglo XIX. Sevilla: Escuela de Estudios Hispano-Americanos.).
229After deciding upon the temporal limits of the investigation, it was necessary to develop criteria to be able to assign the novels to the chronological frame. In general, the publication date of the first known edition is decisive. Works that are listed in bibliographies of the Argentine, Cuban, and Mexican novel but for which no publication date could be verified are not considered. Novels published posthumously are taken into account as long as they were first published between 1830 and 1910. Works that are clearly unfinished are not included.185 Two of the Cuban novels were treated in an exceptional way. Both were published much later than they were written because of their political topicality. The novel “Francisco” (1839, CU) by Anselmo Suárez y Romero was written in 1839 but only published in 1880, and “Cecilia Valdés” (1839, CU) by Cirilo Villaverde was also written in 1939 but first published in its entirety in 1882 (Rössner 2007, 156–157Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.). It is assumed that the style of the texts is mainly characterized by their time of creation, and because they were written so much earlier than they were published, in these cases, the date of creation is taken and not the date of the first publication.
230Regarding the full-text corpus, another question to consider is which editions of the novels to select. There are novels that changed considerably over time when authors reworked them for subsequent editions. For example, the novel “El fistol del diablo” (1859–1860, MX) by Manuel Payno was published in book form in four volumes, the first time from 1859–1860, again in 1871, and then as two volumes in 1877 and in 1906. It was extended several times. The first edition, for example, contains 49 chapters, and the second 86 chapters. On the other hand, most of the novels were only published once between 1830 and 1910, so cases with divergent versions of novels are the exception rather than the norm.186 The strategy that would be most appropriate from a historical point of view would be to only include first editions, considering that also the dates of the novels are derived from their first editions. Unfortunately, the state of digitization did not allow for such a stringent methodology, and different types of editions had to be selected for the corpus.187
231Summing up the selection criteria used for the bibliography and the corpus, it can be noted that a general definition of the novel is followed that allows for including a broad range of subgenres. On the other hand, the general criteria are strictly applied because the size of the bibliography and the corpus make it difficult to make case-by-case decisions. As a consequence, some texts that are considered novels in other contexts are excluded here, while others that are neglected elsewhere, are included because the usual canon of texts is not taken as the general basis. Novels from three countries that represent different regions of Spanish America were chosen. On the one hand, the selection of novels was made based on the place of publication, capturing the local production of literature in the countries. On the other hand, the national and cultural identity of the authors was used as a criterion. That way, the literatures of the countries are defined broadly as cultural-geographical units. The subgenres of the Argentine, Cuban, and Mexican novels are meant to be analyzed comparatively from the phase of the struggle for and the achievement of political independence up to a political and economic stabilization throughout the nineteenth and early twentieth century, involving the literary currents of Romanticism, Realism, Naturalism, and Modernismo. In the next sections, the creation of the bibliographical database and the corpus are described based on the selection criteria outlined so far.
232The bibliographical database, which is also called Bib-ACMé (“Bibliografía digital de novelas argentinas, cubanas y mexicanas, 1830–1910”) in the following, was created with the goal of getting an overview of all the Argentine, Cuban, and Mexican novels published between 1830 and 1910.188 The main motivation for creating the database was to have a pool from which to select novels for the digital corpus and to get a sense of the dimension of the resulting corpus when compared to the overall novelistic production of the time. Unfortunately, the goal of creating a complete bibliography cannot be reached because not all the novels were documented bibliographically, and it is very probable that many texts are not preserved anywhere in libraries, archives, or private collections, especially those not published in book form but only in journals and magazines. Nevertheless, the size of a digital full-text corpus is limited by more factors than that of a bibliographical database, so that it is still worthwhile to undertake the effort to get a picture of the field which is as complete as possible. Furthermore, in comparison with printed and digitized bibliographical works, a truly digital bibliography has the advantage that the information contained in it is programmatically analyzable. How many novels were written by which authors, and how often, when, and where were they published? How long were the novels, and to which subgenres can they be assigned? In what follows, it is explained how the bibliographical database was prepared to be able to answer these questions. In chapter 3.2.1, the sources used to collect the bibliographical entries are accounted for, and it is set out how the selection criteria for novels defined in chapter 3.1 above were applied to choose entries from the sources. Usually, bibliographic entries of literary works include several levels of information: details about authors, editors, publishers, the work itself, the time and place of its publication, etc. To be able to analyze the various information levels contained in such entries, a special data model was developed for the database to which the entries were mapped. This model and its application in the form of text encoding are presented in chapter 3.2.2. In the last part of this chapter, in 3.2.3, the assignment of subgenre labels to the works contained in the bibliographical database is described.
233Three main sources were chosen for the creation of Bib-ACMé, one for each of the three countries covered: for Argentine novels, the work “The Argentine novel: an annotated bibliography” created by Myron Lichtblau was used, for Cuban novels the “Diccionario de la literatura cubana” (DLC) edited by the “Instituto de Literatura y Lingüística de la Academia de Ciencias de Cuba”, and for Mexican novels the “Bibliografía de la novela mejicana” by Arturo Torres-Rioseco (Lichtblau 1997Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.; Instituto de Literatura y Lingüística de la Academia de Ciencias de Cuba 1999Instituto de Literatura y Lingüística de la Academia de Ciencias de Cuba. 1999. Diccionario de la literatura cubana (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmckh0j1.; Torres-Rioseco 1933Torres-Rioseco, Arturo. 1933. Bibliografía de la novela mejicana. Cambridge, Massachusetts: Harvard University Press.). These sources were preferred over national bibliographies for several reasons. In the case of Argentina, to date, there is no national bibliography.189 On the website of the “Biblioteca Nacional de Cuba José Martí”, the work of several bibliographers over the centuries is presented as the national bibliography (Biblioteca Nacional de Cuba José Martí 2011Biblioteca Nacional de Cuba José Martí. 2011. “Bibliografía Nacional Cubana.” https://web.archive.org/web/20190702105833/http://bdigital.bnjm.cu/?secc=bibliografias.). Of these bibliographic endeavors, the “Bibliografía Cubana del Siglo XIX” by Carlos Manuel de Trelles, which is available for download as PDF files with images on the website of the Cuban National Library, is relevant here (Trelles 1911Trelles, Carlos Manuel de. 1911. Bibliografía Cubana del Siglo XIX. 8 vols. Matanzas: Imprenta de Quirós y Estrada.). However, in the eight volumes of this bibliography, works of all kinds are registered and presented by year of publication, so it would be necessary to go through all the years between 1830 and 1910 and look for novels. Although it would be desirable to evaluate Trelles’ bibliography in this regard, this could not be accomplished within this dissertation. In the “Diccionario de la literatura cubana”, on the other hand, primarily literary works are listed, making it much easier to find relevant novels. Furthermore, the dictionary is organized into articles about literary currents, genres, institutions, journals and magazines, and biographical entries, including bibliographic information. The biographical entries are helpful in deciding which authors can be considered Cuban writers because the authors’ relation to Cuba is described.190 For Mexico, the “Instituto de Investigaciones Bibliográficas” is responsible for the publication of the national bibliography “Bibliografía Mexicana”.191 Its digital products include the electronic catalog and search system “Bibliografía Mexicana del Siglo XIX” (Instituto de Investigaciones Bibliográficas n.d.Instituto de Investigaciones Bibliográficas. n.d. “Módulo de búsqueda.” Bibliografía Mexicana Siglo XIX. https://web.archive.org/web/20230603165352/http://bd.iib.unam.mx/iib/proyectos/sigloxix/modulo.html.). In order to find relevant novels, one would, for instance, have to know the authors’ names beforehand and search for the works published by them or look for entries including the term “novela” in the title, which would only yield part of the results. Another possibility would be to search year by year. In comparison, it is more expedient to use Torres-Rioseco’s work which focuses on the novel.192 Furthermore, the national bibliographies usually register works published in the respective countries, but as works written by Argentine, Cuban, and Mexican authors which were published elsewhere are also included here, specialized bibliographical works which consider them as well are advantageous.193
234Other sources were used to complement the information extracted from the main sources. Information about authors (names and life data) was gathered from the Virtual International Authority File (VIAF) (OCLC 2010–2021bOCLC. 2010–2021b. “VIAF. Virtual International Authority File.” https://web.archive.org/web/20230423111630/https://viaf.org/.). Further information about works and editions was added primarily from the following digital sources: “Biblioteca Digital Hispánica” (BDH), “Enciclopedia de la literatura en México” (elem.mx), “HathiTrust Digital Library”, “Internet Archive”, “Wikimedia Commons”, and the “WorldCat” (Biblioteca Nacional de España 2023Biblioteca Nacional de España. 2023. “Biblioteca Digital Hispánica.” https://web.archive.org/web/20230603173847/http://bdh.bne.es/bnesearch/Inicio.do.; Fundación para las Letras Mexicanas A.C. 2018Fundación para las Letras Mexicanas A.C. 2018. “Enciclopedia de la literatura en México.” https://web.archive.org/web/20230603174401/http://www.elem.mx/.; HathiTrust 2008–2023HathiTrust. 2008–2023. “HathiTrust Digital Library.” https://www.hathitrust.org/. Accessed March 28, 2023.; Internet Archive n.d.Internet Archive. n.d. “Internet Archive.” https://web.archive.org/web/20230603161417/https://archive.org/.; Wikimedia Commons 2023Wikimedia Foundation. 2023. “Wikimedia Commons.” https://web.archive.org/web/20230603175401/https://commons.wikimedia.org/wiki/Main_Page.; OCLC 2001–2023OCLC. 2001–2023. “WorldCat.” https://www.worldcat.org/de. Accessed March 28, 2023.).
235By using the different sources, 1,301 candidates for novels were
identified. The selection criteria defined in chapter 3.1 above were applied to the candidates,
resulting in 829 works that were included in BibACMé. Figure 8 shows from which sources the works were
compiled.194 The candidates are shown on the left side,
and the remaining entries of the right side. As can be seen, almost one-third
of the candidates were sorted out after the application of the selection
criteria. Of the three main sources, most novels come from the Mexican
bibliography, and the fewest from the Cuban dictionary.
236Several factors may have caused these varying amounts. First, it is probable that the number of novels published between 1830 and 1910 in Argentina, Cuba, and Mexico and by Argentine, Cuban, and Mexican writers differs per se. It may well be the case that most novels were Mexican as the country’s cultural institutions were more developed than Argentina’s in the early nineteenth century and that there were much lesser Cuban novels because of Cuba’s colonial status until the end of the century. Other political, economic, cultural, and demographic factors may also play a role.195 Nevertheless, it is also very likely that the kind of bibliographic sources that were used here influence this result because the DLC is a general dictionary of literature. It is not specialized in novels and does, therefore, probably not reach the same degree of comprehensiveness as the other two main sources.
237The numbers of the remaining entries are, of course, also influenced by the extent to which the selection criteria led to the omission of works from the different sources. In the DLC, many novels, especially those published in journals and magazines, are mentioned in the biographic articles but not listed in the corresponding bibliographical lists. These were only integrated into Bib-ACMé when the time and place of publication could be verified, and when the length of the text could be estimated. Likewise, Lichtblau includes many novels in his bibliography that were only published in journals, but because there is usually no indication of the extent of the text, these entries were neglected. On the other hand, in Torres-Rioseco, the works listed were almost exclusively published as independent books, balancing out the differences because of missing information to a certain degree.
238When deciding upon the inclusion of the bibliographic references into Bib-ACMé, the selection criteria for novels defined in chapter 3.1 above were applied as follows. It was generally assumed that the works mentioned in bibliographies of the novel are fictional, narrative texts in prose and that works carrying the label “novela” also meet these criteria. In cases of doubt, often triggered by the works’ titles, digital editions196 were checked whenever they were available. When no edition was accessible, doubtful cases were sorted out rather than included.197 The criteria of a publication with its own title and structure, an adult readership, and predominantly realistic characters and setting were checked in a similar manner. The titles of the works were interpreted with regard to the selection criteria, and, wherever possible, the works were checked by consulting editions. Doubtful cases that could not be cleared up in this way were left aside.198 In Lichtblau’s bibliography, the entries are made on the level of editions of the individual literary work, meaning that shorter works published in a collection are listed separately. In the DLC and Torres-Rioseco’s bibliography, in contrast, the entries correspond to publications and not necessarily individual works, so collections are listed as one entry.199 These were checked to extract novels contained in them. When insight into the table of content of a collection was not possible, it was disregarded.
239However, most of the entries from the sources that were dropped here were excluded because of the length criterion. Whereas Lichtblau explicitly includes short novels (Lichtblau 1997, xviLichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.), Torres-Rioseco does not explain his selection criteria regarding the extent of the texts. Although the bibliography is entitled “Bibliografía de la novela mejicana”, it is rather a bibliography of fictional narrative texts of all kinds and lengths or a bibliography following a definition of the novel that is broader than the one used here. Where digital full-texts were available, the number of words was checked. Otherwise, the number of pages was decisive. The extent of the text is not always indicated in the bibliographies, and in the DLC, no page numbers are given at all. In many of these cases, the page numbers could be added through the WorldCat, but not always. It was decided to exclude novels without page numbers that were exclusively published dependently (in journals, magazines, or books). There are, of course, novels only published in a journal that are longer than 84 pages, especially serial novels, but many of the novels that were not published in book form are short novels. On the other hand, novels published independently are usually longer than 84 pages.200 In order not to omit too many relevant works, it was decided to keep monographic works even if no page numbers were available.
240As for the assignment of the novels to the three countries, only
those works were excluded where the author could neither be associated with the
country201 nor the work was
first published there.202 For some
bibliographic entries in the sources, the publication date was not given. When
no edition of the work was found that could be dated to the period from 1830 to
1910, the work was not included in Bib-ACMé. Figure 9 summarizes how many of the candidates were
kept and why the others were excluded.203 The chart shows that only a few entries
did not comply with the criteria of fictionality, narrativity, prose, an adult
readership, and a realistic representation. Most had to be dropped because they
were too short or because the bibliographic information was not complete enough
to decide. For details about individual works, a tabular overview showing the
application of the selection criteria to the entries from the bibliographic
sources is available on GitHub.204
241To conclude the discussion of Bib-ACMé’s sources, it must be said that the contribution of this digital bibliography lies primarily in the compilation, restructuring, integration, and enrichment of existing bibliographies of nineteenth-century Argentine, Cuban, and Mexican novels. The selection criteria were applied in a way that favors a high precision, meaning that all the novels contained in the bibliography should meet the criteria of the working definition formulated in chapter 3.1.1.7 above. That way, the full-text corpus of novels can be compared to a relevant population. Other bibliographic works aim at a higher recall, including many candidates for their subject, so as to be as comprehensive as possible. Moreover, a definition of the novel different from the one advocated for here would obviously lead to a different bibliography. Furthermore, this bibliography could still be completed further using more sources.205 In any case, the modeling and preparation of the bibliographic information in digital format enhance the usability of the data, as outlined in the next section, and facilitate future reuse also in other contexts.
242The data model of Bib-ACMé is centered around the three notions of author, work, and edition. These three entities are defined in accordance with the Functional Requirements for Bibliographic Records (FRBR), a conceptual model developed by the International Federation of Library Associations and Institutions (IFLA) (2009International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.). In FRBR, four basic entities have been defined for the products of intellectual endeavors that are described in bibliographic records: work, expression, manifestation, and item. A second group comprises entities responsible for the intellectual content: person and corporate body (International Federation of Library Associations and Institutions (IFLA) 2009, 13International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.).206 Of these entities, “work”, “expression”, “manifestation”, and “person” are relevant to explain the data model of Bib-ACMé. According to the FRBR model, a “work”, as opposed to an expression of a work or a manifestation of an expression, is defined as “a distinct intellectual or artistic creation” and as an “abstract entity; there is no single material object one can point to as the work” (International Federation of Library Associations and Institutions (IFLA) 2009, 17International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.). A work is recognizable through its individual realizations, i.e., expressions, but they are not to be identified with the work. An “expression” is thus “the intellectual or artistic realization of a work”, and a “manifestation” is “the physical embodiment of an expression of a work” (International Federation of Library Associations and Institutions (IFLA) 2009, 13International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.).207 A “person” is responsible for the creation and the intellectual or artistic content of a work (International Federation of Library Associations and Institutions (IFLA) 2009, 25International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.).
243The idea of a work as an abstract entity is useful for this study because the goal is to analyze the novels as literary works and not as specific expressions of it. Ultimately, a full-text version of a work in the corpus is an individual expression, such as a particular edition. However, it functions as a representative which points to the work and does not stand for itself because the interest is not, for example, in the study and comparison of different expressions of the same work. Furthermore, the generic signals of the work that occur in titles and paratexts were interpreted across different editions. Genre assignments made by other literary historians are usually also not bound to a specific realization of a work.208 In the FRBR report, it is stated that the boundary between one work and another is not easily drawn and is also culturally determined, but that the “modification of a work involves a significant degree of independent intellectual or artistic effort” and that, inter alia, “adaptations of a work from one literary or art form to another (e.g., dramatizations, adaptions from one medium of the graphic arts to another, etc.) are considered to represent new works” (International Federation of Library Associations and Institutions (IFLA) 2009, 18International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.). It is assumed here that the generic identity is determined at the work level.209 A dramatized or versified version of a novel is considered a new work,210 whereas a new edition of a novel with some additional chapters or a new title is not.211 Regarding the treatment of bibliographical information, the abstract notion of a work serves to group various publications of the same work. A novel might be published in a journal, in several subsequent monographic editions, as part of an anthology, or as part of the complete works of an author. These are all different manifestations in FRBR terms. However, such a novel has only one work entry in Bib-ACMé. In the bibliography, the levels of expression and manifestation are combined in the notion of edition. That way, every new realization of a novel that is published, for example, a new version with changes in the text, is registered as a new edition, but every new reprint is also considered a new edition. Together, the number of new realizations and manifestations indicate how successful and popular a novel was. The level of single exemplars is not considered here, although the circulation (the number of printed items of a manifestation) would also convey information about the popularity of the novels. The FRBR concept of person is narrowed down to author in Bib-ACMé to designate the individuals responsible for the creation and content of the novels. In bibliographic descriptions of novels, an author may appear under different names. Whenever pseudonyms could be associated with the same person, these were grouped together in one author entry in Bib-ACMé.212
244The information in Bib-ACMé is encoded in XML, following the standard of the Text Encoding Initiative (TEI) in version P5.213 Compared to full text editions, bibliographic information is highly structured. Therefore, one could also opt for a relational database system to model bibliographic information. However, the use of XML and TEI has some advantages here. For the encoding of historical bibliographical entries, it is very useful to be able to indicate the degree of certainty of information anywhere in the data model because publication dates and places, life dates of authors, etc., are not always well evidenced. In addition, it is reasonable to document the sources of information on several levels, such as the mention of a work in general, the person responsible for a note on a particular edition, and so on. The TEI offers general attributes for this purpose (Text Encoding Initiative Consortium 2023aText Encoding Initiative Consortium. 2023a. “att.global.responsibility.” In: TEI P5: Guidelines for Electronic Text Encoding and Interchange, 839–840. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.), which can be added to many different elements. Furthermore, the level of detail is not the same for all pieces of information. For example, sometimes only the year of an author’s birth is known, and in other cases, also the month and day. The same applies to novels published serially in a journal: in some cases, the exact dates of the first and last published part are known, and in others, only a year is indicated. For this, it makes sense to have a flexible data model.
245Bib-ACMé consists of the following TEI files: “authors.xml”,
containing all the information about the authors of the novels; “works.xml”,
where the works are listed with their author, their main title, and additional
information such as the subgenre of the novel; and “editions.xml”, including
information about different editions of the works. The three main files are
complemented by “nationalities.xml”, “countries.xml”, and “sources.xml”, which
contain controlled values that are referenced from the main files.214
Example 1 shows one entry from
“authors.xml”:
<person xml:id="A367">
<persName>
<surname>Iglesia</surname>
<forename>Álvaro de la</forename>
<addName type="pseudonym">Pedro Madruga</addName>
<addName type="pseudonym">Eligio Aldao y Varela</addName>
<addName type="pseudonym">Artemio</addName>
<addName type="pseudonym">A. L. Baró</addName>
<addName type="pseudonym">Vetusto</addName>
</persName>
<birth>
<date when="1859-04-03">3 de abril de 1859</date>
<placeName>La Coruña</placeName>
<placeName>España</placeName>
</birth>
<death>
<date when="1940">1940</date>
<placeName>La Habana</placeName>
<placeName>Cuba</placeName>
</death>
<sex>masculino</sex>
<nationality>cubana/o</nationality>
<idno type="viaf">120788045</idno>
<note source="#DLC_1999">Llegó a Cuba en 1874. Se estableció en Matanzas.</note>
<note type="country">
<country>Cuba</country>
</note>
</person>
246Each author has a unique identifier used to reference her or him
from the works and editions. The author’s name is encoded, differentiating
between surname, forename, and eventually additional names. When an author's
real name is unknown, and the pseudonym does not have the form of forename plus
surname, only one name is given. Following the name, information about the
birth and death of the author is encoded. The dates are given either only as
years or as full dates, depending on the availability of the information.
Further information that is given is the sex of the author, the nationality, a
note about the country an author is associated with, and optionally a VIAF
identifier and a general note. It is important to note that the element <nationality> is used in a wide sense here because authors
born in Cuba or otherwise assigned to that country before its independence are
also listed as “cubana/o”.215 The note
indicating the country serves to clearly assign all the authors to one of the
three countries Argentina, Cuba, and Mexico. This assignment may correspond to
the nationality or country of birth of an author but is not necessarily bound
to either of them. For example, an author can have another nationality but be
associated with one of the three countries represented in the bibliography
because he or she first published his or her works there.
<bibl xml:id="W925">
<author key="A367">Iglesia, Álvaro de la</author>
<title>La alondra</title>
<term type="subgenre.title.explicit">novela original</term>
<term type="subgenre.title.explicit.norm" resp="#uhk">novela original</term>
<term type="subgenre.title.implicit" resp="#uhk">-</term>
<term type="subgenre.title.interp" resp="#uhk">novela general</term>
<term type="subgenre.summary" subtype="signal" resp="#uhk">novela realista</term>
<term type="subgenre.summary" subtype="theme" resp="#uhk">novela social</term>
<term type="subgenre.summary" subtype="current" resp="#uhk">novela realista</term>
<idno type="cligs">nh0221</idno>
<country>Cuba</country>
<note type="source">
<ptr target="#DLC_1999"/>
</note>
</bibl>
247Example 2 shows an
entry in “works.xml”. A work is encoded as a simple bibliographic citation with
a unique identifier. Only the author and main title of the work are given here
because information about the publication, i.e., the publication date,
publication place, concrete titles and subtitles of an edition, etc., does not
correspond to the abstract work level. The author’s name in the work entry is
connected to the person in “authors.xml” with a key corresponding to the author
ID. Further information given in a work entry are terms indicating the
subgenre,216, an optional
CLiGS identifier for works that are included in the corpus, the country the
work is associated with, and a note pointing to the bibliographic source of the
entry. Here, the country is not to be equated with the publication place
because a work is also included if an author belongs to the country, even if it
was never published there. On the other hand, there are works first published
in a country but written by foreign authors.217
The affiliation of a novel to a country is instead made on the work level. Example 3 below shows an entry from
“editions.xml” which corresponds to the above work entry.
<biblStruct corresp="works.xml#W925" xml:id="E1284">
<monogr>
<author key="A367">Iglesia, Álvaro de la</author>
<title level="m" type="main">La alondra</title>
<title level="m" type="sub">(El secreto de Estrovo)</title>
<title level="m" type="sub">Novela original</title>
<imprint>
<publisher>Biblioteca de Follas Novas</publisher>
<pubPlace corresp="countries.xml#CU">La Habana</pubPlace>
<date when="1897">1897</date>
</imprint>
<extent n="315">315 pp.</extent>
</monogr>
<ref>https://catalog.hathitrust.org/Record/100345975</ref>
<ref>https://archive.org/details/laalondraelsecr00iglegoog</ref>
</biblStruct>
248Editions are encoded with a structured bibliographic citation.
Each edition is connected to the work it realizes via the @corresp attribute, which points to the “works.xml” file and the work
ID. The edition itself also has a unique ID given in @xml:id. Depending on the type of publication, details are either
given in a combination of the elements <analytic> (for
dependent publications) and <monogr> (for independent
publications) or simply the latter. Information about a series a book belongs
to may also be given in a <series> element.218 As in “works.xml”, the author’s
name is associated with the person in “authors.xml” via the author key. Another
piece of information that is mapped to a controlled list of values is the
publication place. In the @corresp attribute of the
element <pubPlace>, the file “countries.xml” and a country
key are given. This was made to be able to analyze in which countries the works
were published without having to interpret the names of cities on the fly. Part
of the information included in an edition entry is also the extent of the
publication in page numbers. Finally, when digital versions of the edition were
found, links to them were referenced at the end of the entry.
249The different TEI files are each controlled by their own schemas.
It was decided to use different schemas and not one for all the files to be
able to keep the data model as strict as possible. The kinds of elements
allowed in a file and their order are regulated in RELAX NG schemas.219 In addition, Schematron files are used to
control the content of selected elements and attributes.220
Example 4 shows one of the rules
contained in the Schematron file for “works.xml”.
<sch:rule context="tei:listBibl/tei:bibl">
<sch:let name="work-id" value="@xml:id"/>
<sch:assert test="matches($work-id,'^W\d+$')">The id of a work should have
the form "W + number"</sch:assert>
<sch:assert test="doc('../data/editions.xml')//tei:biblStruct[@corresp =
concat('works.xml#',$work-id)]">There is no corresponding work-id
in editions.xml</sch:assert>
</sch:rule>
250The rule applies to the context of an individual bibliographic entry and tests two assertions. The first assertion checks the form of the work identifier, and the second assertion tests if there is an edition in “editions.xml” that corresponds to the work in question. The example shows that Schematron can be used to make validations across several XML documents, which is important for Bib-ACMé because it is organized in separate TEI files that contain references to each other. That way, it can be assured that the identifiers used for authors, works, and editions, are consistent throughout the database and that there are no superfluous or missing entries. In addition, checks that involve the comparison of values are not possible with the general schema language RELAX NG. Other aspects that are controlled with the Schematron files are the correspondence of author names between the different files, the structure of CLiGS identifiers, and that source and country codes are referenced correctly.
251The preparation of the entries from the bibliographic sources so that they conform to the data model of Bib-ACMé makes a wide range of analytical approaches possible. The data can be evaluated on the three main levels of authors, works, and editions and regarding more detailed information encoded in the TEI files. Overviews of the information contained in Bib-ACMé are given in chapter 4.1 below, where the bibliography of novels is compared to the corpus.
252Several kinds of subgenre labels were assigned to the works in Bib-ACMé to get an overview of the subgenres to which the novels in the bibliography belong. The labels fall into three principal groups: The first group is derived from main titles, subtitles and series titles of the novels (“subgenre.title”) and includes explicit as well as implicit genre signals, the second is taken from literary-historical sources (“subgenre.litHist”), and the third group summarizes and categorizes the subgenre values collected in the other two groups (“subgenre.summary”). In this chapter, first, an example is presented to illustrate how the subgenre labels were assigned to the bibliographic entries of the novels and how they were encoded in TEI. More general considerations regarding the assignment of subgenre labels to the novels are made when discussing the first example but also in the sections following it. Different levels of subgenre terms that are used in the encoding are presented in chapter 3.2.3.2. On the one hand, the subgenre labels are differentiated by the type of source from which they were collected. Labels can be explicit historical labels or be derived from implicit historical signals, or they can be collected from literary-historical sources. The differences between these kinds of labels are discussed in chapters 3.2.3.3 (“Explicit and Implicit Subgenre Signals”), 3.2.3.4 (“Interpretive Subgenre Labels”), and 3.2.3.5 (“Literary-Historical Subgenre Labels”). On the other hand, the subgenre labels are sorted according to discursive aspects. It is assumed that a literary work is a complex discursive and semiotic object to which generic terms refer on different levels. A model summarizing the discursive levels that are relevant for the bibliography and corpus of novels at hand is presented in chapter 3.2.3.6 (“A Discursive Model of Generic Terms”).
253Example 5 shows
the work entry of the novel “Los casamientos del diablo” (1889, AR) by
Enrique Ortega in the digital bibliography, which includes several subgenre
labels.
<bibl xml:id="W563">
<author key="A227">Ortega, Enrique</author>
<title>Los casamientos del diablo</title>
<term type="subgenre.title.explicit">novela histórica americana</term>
<term type="subgenre.title.explicit.norm" resp="#uhk">novela histórica</term>
<term type="subgenre.title.explicit.norm" resp="#uhk">novela americana</term>
<term type="subgenre.title.explicit.norm" resp="#uhk">novela</term>
<term type="subgenre.title.implicit" resp="#uhk">novela sentimental</term>
<term type="subgenre.title.implicit" resp="#uhk">novela romántica</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">novela histórica</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">novela americana</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">novela</term>
<term type="subgenre.summary.signal.implicit" resp="#uhk">novela sentimental</term>
<term type="subgenre.summary.signal.implicit" resp="#uhk">novela romántica</term>
<term type="subgenre.summary.theme.explicit" resp="#uhk"
cligs:importance="2">novela histórica</term>
<term type="subgenre.summary.theme.implicit" resp="#uhk">novela sentimental</term>
<term type="subgenre.summary.current.implicit" resp="#uhk">novela romántica</term>
<term type="subgenre.summary.identity.explicit" resp="#uhk">novela americana</term>
<term type="subgenre.summary.mode.reality.explicit"
resp="#uhk">novela histórica</term>
<term type="subgenre.summary.mode.representation.explicit" resp="#uhk">novela</term>
<country>Argentina</country>
<note type="source">
<ptr target="#Lichtblau_1997"/>
</note>
</bibl>
254The subgenre labels are encoded in <term>
elements that are characterized further by the attribute @type. First, explicit generic labels that occur in the main title,
subtitle, or series title, are marked as
"subgenre.title.explicit". In the above example, there is an
edition of the novel with the subtitle “novela histórica americana”. Because
the generic identity is determined on the work level, information about the
subgenre is taken from all the work’s editions. Therefore, if there are
several editions and only one carries the explicit subgenre label, it is
nonetheless included here. If there are several editions with differing
subgenre labels, all of them are considered. The second type of label is
called "subgenre.title.explicit.norm" and contains a normalized
version of the explicit subgenre label. The @resp
attribute indicates by whom the normalization was done. For the novel at
hand, the label “novela histórica americana” is normalized to several
individual subgenre labels: “novela histórica”, “novela americana”, and
“novela”. The primary purpose of the normalization step is to make the
explicit subgenre labels comparable in computational analysis. In the
current case, the first label “novela histórica” refers to a subgenre
predominantly determined by the theme of the novel. The second label “novela
americana” points to the cultural-geographical and linguistic origin and
identity of the novel. In the bibliography, there are also novels with the
subtitle “novela argentina”, “novela cubana”, “novela mexicana”, “novela
original”, etc. These kind of labels either refer to the continent
(“americana”), to the country (“argentina”, “cubana”, “mexicana”), or to the
fact that the novel was originally written in Spanish and not translated
(“original”).221 The third label extracted from the example, “novela”,
refers to the genre of the text. It is encoded as a subgenre label here, as
well, because in the bibliography, only about half of the works carry the
explicit label “novela”.222 Because
all the works that are included follow the selection criteria for novels
defined in chapter 3.1.1 above,
it is assumed that the explicit label “novela” points to a subtype of all
the texts that can be considered as novels formally. Other labels usually
designating genres, such as “cuento”, “drama”, “ensayo”, or “leyenda”, are
treated in the same way.
255After the explicit generic signals of the titles, implicit
signals are evaluated and captured in terms of the type
"subgenre.title.implicit". Here again, the attribute @resp serves to indicate who made the interpretation.
In this case, two implicit labels, “novela sentimental” and “novela
romántica”, are recorded. The word “casamientos” in the title is interpreted
as a reference to a sentimental plot, and the whole title “los casamientos
del diablo” is interpreted as a sign of a novel of the romantic
current.223
256The above example does not contain terms of the second group
("subgenre.litHist") because for the novel “Los casamientos
del diablo”, no statements about its subgenre were found that were made by
literary historians. Therefore, the terms of the third group
("subgenre.summary") only take up the values that were
inferred from the title. The summary at the end of the different subgenre
terms has the function of organizing the previous data into categories of
generic information in order to enhance the comparability of the terms
throughout the bibliography for further analysis. What kind of generic
information is given, is indicated in the part of the @type attribute after "subgenre.summary". The summary
values have five subtypes: "signal", "theme",
"current", "identity", and "mode". Terms
of the type "subgenre.summary.signal" contain all the subgenre
labels that were signaled by the work title either explicitly (marked as
"subgenre.summary.signal.explicit") or implicitly
(subgenre.summary.signal.implicit). In the above example, all
the subgenre labels are derived from signals of the text. However, in other
cases, there are further subgenre labels that were assigned to the work by
critics, but that cannot be deduced from the work’s title. The second
subtype of the summary values is "theme". Terms of this type
contain all the labels that refer to subgenres defined primarily or in part
by the theme of the text. In the current example, there are two thematic
labels: “novela histórica” and “novela sentimental”. The first one was given
explicitly and is therefore encoded as a term of the type
"subgenre.summary.theme.explicit" whereas the second one was
deduced from the title and is marked as
"subgenre.summary.theme.implicit".
257The first of the “theme” terms carries the attribute @cligs:importance with the value "2". With
this attribute, an order of priority is given for cases with several
subgenre terms of the same type. It was decided to use this attribute only
for “theme” and “current”, i.e., for subgenre labels belonging to these two
categories. These are the types of subgenre labels that are at the center of
interest of this dissertation. Furthermore, most literary histories and
critical studies refer to novelistic subgenres of this kind. As to the
priorities, in general, only one high priority ("2") is assigned,
while the other terms without this attribute are interpreted as low-priority
terms. Just as the normalization of explicit titles serves to enhance
comparability, this prioritization has the pragmatic function of being able
to select one value for each subgenre term of the types “theme” and
“current” for cases where unique values are needed in an analysis. However,
it is a simplification because it is ultimately not possible to map
different subgenre assignments to a discrete numerical system as they
usually represent different perspectives on the literary work.224 As rules of thumb, terms deduced from explicit signals
are rated higher than those going back to implicit ones. Furthermore,
signals that are stronger are valued higher, for example, if there are
several signals pointing to a certain subgenre and only one signal points to
another. In addition, terms that are mentioned by literary critics are
valued higher than those that are not.
258After the thematic terms, those referring to literary currents
are listed ("subgenre.summary.current"). In the above example,
there is only one term of this kind, the “novela romántica”. The term
“novela americana” is encoded as a term of the type
"subgenre.summary.identity". Finally, there are two subgenre
labels grouped into the “mode” category: “novela histórica” belongs to the
category "subgenre.summary.mode.reality" and “novela” to
"subgenre.summary.mode.representation". The “mode” group
contains labels that are not thematic and do not refer to literary currents
or the cultural or linguistic identity of the works. Instead, these are
labels indicating how the works relate to extratextual circumstances or to
the way the text is organized and presented. In the example,
"mode.reality" designates labels that involve the relationship
of the text to reality. Usually, a historical novel intends to present
settings and events of the past, but not the present reality.
"mode.representation" includes labels that indicate how the
novel is organized and presented linguistically. The term “novela” means
that the text is presented in the narrative mode and not, for example, as a
dramatic text. As can be seen in the example, some subgenre labels are
repeated in the summary, in this case, “novela histórica”, which falls into
the two categories "subgenre.summary.theme" and
"subgenre.summary.mode.reality". On the other hand, each novel
can have several subgenre labels of the same kind, as the two thematic
labels “novela histórica” and “novela sentimental” of this example show.
Finally, because all the values in the summaries are normalized, the summary
terms also carry a @resp attribute that shows who
entered the values.
259The system of the summary values needs to be explained further. Which categories were chosen, for which reasons, and which values can they take? The subgenre categories chosen (“theme”, “current”, “identity”, and “mode” with further subtypes) are not generally exhaustive from a genre theoretical perspective and not congruent to one specific theoretical model of genre. Instead, they reflect the generic signals that occur in the collection of novels represented in the bibliography and the corpus, as well as the terms with which the subgenres of these novels are described by literary historians. There are general models for describing the different levels to which generic labels might refer. Some of these models include more categories than the ones chosen here, and others have fewer or different categories. The categories chosen here are, for the most part, derived from a model developed by Wolfgang Raible (Raible 1980Raible, Wolfgang. 1980. “Was sind Gattungen? Eine Antwort aus semiotischer und textlinguistischer Sicht.” Poetica 12: 320–349.). In table 2, the different subgenre categories used in the present model are listed, exemplified, and commented on, and the levels of Raible’s model that correspond to the ones here or are similar to them are given.
| Kind of subgenre label | Value of @type |
Examples | Explanation | Level in Raible’s model |
|---|---|---|---|---|
| signal | subgenre.summary.signal | novela histórica,
novela naturalista, novela original, memorias |
subgenre labels that are derived from explicit or implicit signals of the novel | - |
| theme | subgenre.summary.theme | novela gauchesca,
novela histórica, novela sentimental |
subgenre labels that refer to a main theme of the novel | Objektbereich |
| current | subgenre.summary.current | novela romántica,
novela realista, novela naturalista |
subgenre labels that refer to the literary current of the novel | - |
| identity | subgenre.summary.identity | novela americana,
novela mexicana, novela original |
subgenre labels that refer to the cultural-geographical and linguistic identity of the novel | - |
| mode | subgenre.summary.mode | novela epistolar,
novela fantástica, novela humorística, cuadros, drama, memorias |
subgenre labels that refer to the mode the novel is narrated in / the form it is presented in | Kommunikationssituation, Verhältnis zwischen Text und Wirklichkeit, Medium, sprachliche Darstellungsweise |
| intention | subgenre.summary.mode.intention | novela cómica,
novela moralista, novela de propaganda |
subgenre labels that refer to the aim the author/narrator pursues with the novel | Kommunikationssituation |
| attitude | subgenre.summary.mode.attitude | novela política,
novela satírica |
subgenre labels that refer to the attitude the author/narrator has towards what is represented in the novel | Kommunikationssituation |
| reality | subgenre.summary.mode.reality | novela científica,
novela fantástica, novela histórica, leyenda |
subgenre labels that refer to the relationship between the novel and reality | Verhältnis zwischen Text und Wirklichkeit |
| medium | subgenre.summary.mode.medium | novela epistolar,
croquis, cuadros, páginas, panorama |
subgenre labels that refer to the medium that the novel uses (also in a figurative sense) | Medium |
| representation | subgenre.summary.mode.representation | cuento,
drama, ensayo, episodios, novela |
subgenre labels that refer to the mode the novel is represented in linguistically (or narratively) | sprachliche Darstellungsweise |
260Different types of subgenre labels were already introduced with the example “Los casamientos del diablo” above. In what follows, some more general considerations regarding the system of subgenre labels developed here are made, beginning with the category “signal”. It comprises subgenre labels that are derived from explicit or implicit signals of the novel, either in paratextual elements (in a title, subtitle, series title, preface, epigraph, etc.) or in the opening of the texts. These labels can be of any of the following kinds of labels (thematic labels, labels referring to literary currents, or other types of labels). For the bibliography, they were only derived from the titles because this is the only paratextual information directly available in the bibliographic records. For the corpus, other signals were evaluated as well. Apart from that, the approach to assigning the subgenres is the same for the bibliography and the corpus. Therefore, the general points are explained in this section, while only the additional corpus-specific aspects are explained below in chapter 3.3.4.
261It is important to note that signals can be explicit subgenre labels, for example, the subtitle “novela histórica americana” above. Besides that, they can also be aspects of the title (and other paratextual and textual elements) that can be interpreted in terms of subgenre labels, for example, “casamiento” as pointing to a sentimental novel and “diablo” to a romantic novel. The evaluation of the signals thus involves a significant interpretive step, and it presupposes knowledge about possible subgenres. The knowledge is, on the one hand, derived from the bibliography and the corpus itself (which subgenres occur frequently and what are their characteristics?) and, on the other hand, from representations of the subgenres in literary-historical works. By encoding many steps of this interpretation process (starting from explicit labels, going on to normalized values, mentioning implicit signals, summarizing all in the categorized labels, and keeping their origin as “explicit” or “implicit”), it should be possible to follow the decisions made here closely for each of the novels in the bibliography. Nevertheless, another encoder might have reached other results. The position adopted here is that the genre or subgenre of a text cannot be determined unequivocally without presuppositions. To avoid the influence of the own previous knowledge or the necessity of previous definitions, one could opt for only referring to explicit generic labels. However, in the case of the bibliography and corpus at hand, this would have led to a very reduced setup because only some kinds of explicit subgenre labels are very frequent. Table 3 lists the top most frequent explicit labels, ordered by the frequencies of the normalized versions.225
| Subgenre label | Frequency explicit | Frequency explicit normalized | ||
|---|---|---|---|---|
| novela | 398 | 48 % | 403 | 49 % |
| novela histórica | 73 | 9 % | 133 | 16 % |
| novela original | 97 | 12 % | 113 | 14 % |
| novela mexicana | 6 | 1 % | 67 | 8 % |
| novela de costumbres | 25 | 3 % | 57 | 7 % |
| episodios | 64 | 8 % | 54 | 7 % |
| memorias | 49 | 6 % | 54 | 7 % |
| leyenda | 42 | 5 % | 44 | 5 % |
| novela cubana | 18 | 2 % | 35 | 4 % |
| drama | 25 | 3 % | 28 | 3 % |
| novela nacional | 0 | 0 % | 26 | 3 % |
| historia | 22 | 3 % | 25 | 3 % |
| cuento | 15 | 2 % | 15 | 2 % |
| novela argentina | 5 | 1 % | 15 | 2 % |
| novela social | 2 | 0 % | 13 | 2 % |
| novela americana | 4 | 0 % | 12 | 1 % |
| escenas | 11 | 1 % | 12 | 1 % |
| novela policial | 0 | 0 % | 11 | 1 % |
| novels without any explicit label | 207 | 25 % | - | - |
262As can be seen, only a few of the top most frequent explicit labels refer to subgenres of the novel in common sense, i.e., labels related to the themes of the novels: 16 % of the works carry the label “novela histórica”, 7 % the label “novela de costumbres”, 2 % the label “novela social”, and 1 % the label “novela policial”. The other frequent labels are either of a very general nature (“novela”, “leyenda”, “drama”, “historia”, “cuento”) or they refer to aspects of the novels that are usually not focused on in subgenre studies, such as the identity of the texts (“novela original”, “novela mexicana”, “novela cubana”, “novela nacional”, “novela argentina”, “novela americana”) or the way the text is structured and presented linguistically (“episodios”, “memorias”, “escenas”). Furthermore, it can be noted that even the topmost frequencies decrease sharply. Finally, not all the novels have explicit labels: 25 % of the novels in the bibliography do not convey any generic information explicitly.
263For some of the subgenre labels that entered the top list, an
author and series bias can be noted.226 Most of the occurrences of the terms “drama” and “novela
policial”, for example, stem from the numerous novels written by the
Argentine author Eduardo Gutiérrez, which are organized in series and carry
subtitles of the form “dramas policiales”, “dramas militares”, “dramas
cómicos”, etc. The many “episodios”, “memorias”, “leyendas”, “novelas
nacionales”, and “historias” are connected to series of historical novels,
some of which are called “episodios nacionales” or “leyendas históricas”. It
was decided not to keep the combined labels in the normalized form, though,
because even if some of the combinations occur several times and lead to
correlations in the frequencies of the labels, their components are also
part of other kinds of subtitles. Furthermore, the combinations of
individual subgenre labels in the subtitles are so varied and often
individual that it would be impossible to compare them without any
normalization step. The original combinations can still be reproduced
because they are encoded in terms of the type
"subgenre.title.explicit".
264If only the thematically oriented explicit subgenre labels would be regarded, most of the 829 novels in the bibliography would have had to be considered general fiction because only 36 % of the novels have such labels.227 However, many of the novels have been interpreted as belonging to certain subgenres, and many signal their subgenre(s) implicitly. Some well-known and also relatively frequent subgenres of the novel are rarely indicated explicitly, for example, sentimental novels. In the whole bibliography, there is only one novel with the explicit subtitle “novela sentimental”, but many more novels can be assigned to this subgenre. When also implicit signals and literary-historical assignments are included, the picture of the top most frequent subgenres changes, as table 4 shows.228
| Subgenre label | Frequency absolute | Frequency relative |
|---|---|---|
| novela | 404 | 49 % |
| novela romántica | 269 | 32 % |
| novela sentimental | 252 | 30 % |
| novela histórica | 244 | 29 % |
| novela social | 177 | 21 % |
| novela de costumbres | 133 | 16 % |
| novela realista | 122 | 15 % |
| novela original | 113 | 14 % |
| novela naturalista | 81 | 14 % |
| novela mexicana | 67 | 8 % |
| novels withouth any subgenre assignment | 51 | 6 % |
265Many more novels in the bibliography are covered with this approach. So for the reasons given, it was decided to include interpretive subgenre labels, as well. Both implicit signals evaluated by the author of this dissertation and assignments made by other literary historians are considered as such. The difference between both is that for the other literary-historical labels, it is not known in detail on what bases they were assigned.229 Literary-historical labels are discussed in more detail below. The interpretive labels worked out here are derived from specific textual signals: the titles (in the case of the bibliography) and additional paratextual elements (in the case of the corpus). The decisions rest on a certain set of subgenres taken as the basis for interpreting the implicit signals. This set does not comprise all of the existing explicit labels, though. Instead, the focus is on subgenres related to themes and literary currents, as these are the kinds of subgenres most often referred to in literary histories and also because there are known concepts of these subgenres that can be used.230 In addition, the set contains some subgenres that repeatedly occur as explicit labels in the bibliography, and that can be inferred from textual signals in other cases, even if they are not part of the critical subgenre canon, for example, the “novela contemporánea”. Table 5 contains the set of subgenres used to interpret implicit signals. Like the list of kinds of subgenres, this set is also not exhaustive from a general perspective on the subgenres of the novel. Instead, it is based on the relevance of the subgenres for the bibliography and the corpus.
| Kind of subgenre | Subgenre labels |
|---|---|
| theme | Künstlerroman, novela abolicionista, novela biográfica, novela científica, novela contemporánea, novela criminal, novela de aventuras, novela de costumbres, novela de familia, novela de la ciudad, novela de misterio, novela de viajes, novela didáctica, novela doméstica, novela filosófica, novela gauchesca, novela histórica, novela humorística, novela indigenista, novela militar, novela moralista, novela picaresca, novela política, novela psicológica, novela regional, novela sentimental, novela social |
| current | novela romántica, novela realista, novela naturalista |
| identity | novela regional |
| mode.intention | novela didáctica, novela humorística, novela moralista |
| mode.attitude | novela abolicionista |
| mode.reality | novela científica, novela contemporánea, novela de misterio, novela histórica |
| mode.representation | novela filosófica, novela psicológica |
266Some of the subgenres of this set that are included in the thematic group also belong to other levels of the model defined above.231 They are listed again in the lower part of the table for the sake of completeness. Nevertheless, when this set of subgenres was applied to interpret implicit signals, the focus was on the thematic aspects. Furthermore, the thematic subgenres are placed on different levels of generality. The types novela de familia, novela de la ciudad, and novela doméstica are more specific than, for example, novela social, and they could also be subsumed under the latter term. That terms of different levels of generality occur in the list is because there are signals in the bibliography and the corpus that can best be interpreted with these labels. For example, the novel “La familia de Sconner” (1858, AR) by Miguel Cané (father) is interpreted as a novela de familia and a novela social and the novel “La sociedad y sus víctimas. Escenas bonaerenses” (1902, AR) by Matías Calandrelli both as a novela de la ciudad and a novela social.232
267Following up on the question of how many novels are covered when also interpretive subgenre labels are included, tables 6 and 7 show the most frequent subgenre labels related to themes and literary currents, including explicit as well as implicit signals and literary-historical assignments.233
| Subgenre label | Frequency absolute | Frequency relative |
|---|---|---|
| novela sentimental | 252 | 30 % |
| novela histórica | 244 | 29 % |
| novela social | 177 | 21 % |
| novela de costumbres | 133 | 16 % |
| novela política | 51 | 6 % |
| leyenda | 44 | 5 % |
| novela criminal | 37 | 4 % |
| novela de la ciudad | 27 | 3 % |
| novela indigenista | 27 | 3 % |
| novela gauchesca | 21 | 3 % |
| novels withouth thematic label | 134 | 16 % |
| Subgenre label | Frequency absolute | Frequency relative |
|---|---|---|
| novela romántica | 269 | 32 % |
| novela realista | 122 | 15 % |
| novela naturalista | 81 | 10 % |
| novela modernista | 8 | 1 % |
| novela verista | 5 | 1 % |
| novela clasicista | 3 | 0 % |
| novels without label of literary current | 424 | 51 % |
268The four biggest thematic groups are sentimental, historical, social novels, and novels of manners (novela de costumbres). For 16 % of the novels, no thematic label could be assigned. The literary current most frequently assigned are romantic novels, followed by realist and naturalist novels. In the case of the literary currents, more than half of the novels in the bibliography do not have any label of this kind (51 %). One reason for this is that the literary current is usually not given explicitly: there are only five novels in the whole bibliography with explicit signals for the “novela naturalista” and six for the “novela realista”. The term “novela romántica” does not occur at all. The second reason is that literary currents are mainly a concern of literary historians, and for 48 % of the novels in the bibliography, no assignments made by literary historians could be found. An important point to consider when looking at the numbers is that they do not mean that the novels that do not have a certain subgenre label do not possibly belong to that subgenre. The distribution of subgenre labels only indicates that these are the cases where information (explicit, implicit, literary-historical) is available.
269Going on to the discussion of literary-historical labels, example 6 shows the entry of the
work “Santa” (1903, MX) by Federico Gamboa. For this work, there are no
labels from the first group (explicit or implicit labels inferred from the
title) but many from the second (labels taken from literary-historical
sources).
<bibl xml:id="W838">
<author key="A326">Gamboa, Federico</author>
<title>Santa</title>
<term type="subgenre.litHist" resp="#Schlickers_2003">novela naturalista</term>
<term type="subgenre.litHist" resp="#Dill_1999">naturalistischer Roman</term>
<term type="subgenre.litHist" resp="#Dill_1999">Großstadtroman</term>
<term type="subgenre.litHist" resp="#Varela-Jacome_1982">novela naturalista</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela de tendencia
objetiva</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela naturalista</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela de tendencia mixta</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela social</term>
<term type="subgenre.litHist" resp="#Galvez_1990">novela de tendencia
naturalista</term>
<term type="subgenre.litHist" resp="#Galvez_1990">novela del período realista</term>
<term type="subgenre.litHist" resp="#Lichtblau_1959">Naturalism</term>
<term type="subgenre.litHist" resp="#Roessner_2007">Naturalismus</term>
<term type="subgenre.litHist"
resp="#FernandezAriasCampoamor_1952">Naturalismo</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela naturalista</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela social</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela realista</term>
<term type="subgenre.summary.signal.implicit" resp="#uhk">novela naturalista</term>
<term type="subgenre.summary.theme.litHist" resp="#uhk">novela social</term>
<term type="subgenre.summary.current.implicit" resp="#uhk"
cligs:importance="2">novela naturalista</term>
<term type="subgenre.summary.current.litHist" resp="#uhk">novela naturalista</term>
<term type="subgenre.summary.current.litHist" resp="#uhk">novela realista</term>
<idno type="cligs">nh0080</idno>
<country>México</country>
<note type="source">
<ptr target="#Torres-Rioseco_1933"/>
</note>
</bibl>
270In various literary-historical works, “Santa” is classified as
a naturalistic novel. The literary-historical labels are collected in terms
of the type "subgenre.litHist", and the respective source is
given in the attribute @resp. All the different
literary-historical assignments are summarized in terms of the type
"subgenre.listHist.interp". In the case of “Santa”, the
subgenre assignments made by critics are quite unanimous. Besides being
classified as a naturalistic novel, “Santa” is also described as a realist
and a social novel. Like explicit and implicit signals, literary-historical
labels are also summarized and categorized further in terms of the type
"subgenre.summary", following the procedures explained with
the first example above. For “Santa”, the literary-historical labels result
in three summary terms: “novela social” is encoded as a thematic label
("subgenre.summary.theme.litHist"), and “novela naturalista”
and “novela realista” are grouped as labels referring to literary currents
("subgenre.summary.current.litHist"). The label “novela
naturalista” is weighted higher than “novela realista” because it is
mentioned more often by literary critics
(@cligs:importance="2") and also because it occurs as an
implicit signal in the paratext of the novel, as indicated with the terms
"subgenre.summary.signal.implicit" and
"subgenre.summary.current.implicit". This implicit signal is
not derived from the title of the novel, though, but from other paratextual
elements. In the case of “Santa”, this is possible because the novel is part
of the corpus and was analyzed in more detail.234
271In the same way that the explicit generic information
occurring in the titles and other paratexts is normalized, also the subgenre
labels collected from literary-historical works are interpreted and
standardized because not all literary historians use the same terminology.
Table 8 lists the different
interpretive values contained in terms of the type
"subgenre.litHist.interp" as well as the kinds of subgenres
with which these values can be associated.
| Kind of subgenre | Subgenre labels |
|---|---|
| theme | Bildungsroman, crónica, Künstlerroman, memorias, novela abolicionista, novela científica, novela criminal, novela de aventuras, novela de costumbres, novela de familia, novela de la ciudad, novela didáctica, novela documentaria, novela de misterio, novela de viajes, novela fantástica, novela gauchesca, novela histórica, novela indigenista, novela moralista, novela picaresca, novela política, novela psicológica, novela regional, novela sentimental, novela social |
| current | novela clasicista, novela modernista, novela naturalista, novela realista, novela romántica, novela verista |
| identity | novela regional |
| mode.intention | novela didáctica, novela moralista |
| mode.attitude | novela abolicionista, novela política, novela satírica |
| mode.reality | novela científica, novela de misterio, novela fantástica, novela histórica |
| mode.medium | novela epistolar |
| mode.representation | crónica, memorias, novela documentaria, novela epistolar, novela psicológica |
272As for the set of subgenre labels used to interpret titles and other paratexts of the novels, the set of labels interpreted from literary-historical subgenre labels also focuses on thematic labels and labels referring to literary currents. The other kinds of subgenre labels are only of secondary importance in the interpretation process. A subgenre that is often mentioned in literary-historical works is the novela costumbrista (Gálvez 1990, 100–101Gálvez, Marina. 1990. La novela hispanoamericana (hasta 1940). Madrid: Taurus.; Remos y Rubio 1935, 57–109Remos y Rubio, Juan J. 1935. Tendencias de la narración imaginativa en Cuba. La Habana: Casa Montalvo-Cárdenas. https://dloc.com/UF00078289/00001/images.; Sánchez 1953, 227–256Sánchez, Luis Alberto. 1953. Proceso y contenido de la novela hispano-americana. Madrid: Editorial Gredos.). It was decided to interpret this label as novela de costumbres because, historically, the novels carried the latter label. Costumbrismo is also often described as a literary current (Dill 1999, 155–157Dill, Hans-Otto. 1999. Geschichte der lateinamerikanischen Literatur im Überblick. Stuttgart: Reclam.; Rössner 2007, 146–147Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.), but this aspect is not highlighted here because the novelas de costumbres were written and published throughout the whole the nineteenth century. Some of them can be attributed to the romantic current, others to the realist current, and even some naturalistic novels carry labels including the word “costumbres”.235 Other standardizations were made. For example, novels related to gauchos were all normalized to novela gauchesca, novels related to cities to novela de la ciudad, novels about indigenous people to novela indigenista, novels about the system of slavery in Cuba to novela abolicionista, and novels related to crimes to novela criminal.236
273In Bib-ACMé, only a selection of literary-historical sources was used for the assignment of subgenre labels. The critical literature on Spanish-American novels is vast, so a choice had to be made. Works of different scopes were selected, preferably those where the assignment of a novel to a subgenre is explicit. The sources used are listed in table 9.
| Scope | Title | Editor / Author | Year |
|---|---|---|---|
| Spanish-American literature | Geschichte der lateinamerikanischen Literatur im Überblick | Dill, Hans-Otto | 1999 |
| Spanish-American novel | La novela hispanoamericana (hasta 1940) | Gálvez, Marina | 1990 |
| Spanish-American novel | Proceso y contenido de la novela hispano-americana | Sánchez, Luis Alberto | 1953 |
| Nineteenth-century Spanish-American novel | Evolución de la novela hispanoamericana en el siglo XIX | Varela Jácome, Benito | 2000 |
| Spanish-American romantic novel | La novela romántica en Hispanoamérica | Suárez-Murias, Marguerite C. | 1963 |
| Nineteenth-century Argentine novel | The Argentine novel in the nineteenth century | Lichtblau, Myron I. | 1959 |
| Argentine novel (1838–1872) | Como crecen los hongos. La novela argentina entre 1838 y 1872 | Molina, Hebe Beatriz | 2011 |
| Cuban novel | Tendencias de la narración imaginativa en Cuba | Remos y Rubio, Juan J. | 1935 |
| Mexican novel | Novelistas de Mejico. Esquema de la historia de la novela mejicana (De Lizardi a 1950) | Fernández-Arias, Campoamor, José | 1952 |
| Nineteenth-century Mexican historical novel | The Mexican historical novel. 1826–1910 | Read, John Lloyd | 1939 |
| Spanish-American naturalistic novel | El lado oscuro de la modernización: estudios sobre la novela naturalista hispanoamericana | Schlickers, Sabine | 2003 |
| Cuban naturalistic novel | El Naturalismo en la novela cubana | Molina, Sintia | 2001 |
274In literary-historical works, assignments to subgenres sometimes occur in the text and also often through the structure and organization of a literary history if a novel is mentioned in a section carrying the title of a subgenre.237 However, clear assignments are not always made because many novels are rather described in their relationship to a certain subgenre and are also evaluated as mixtures or deviations.238 Regarding the discussion of novelistic subgenres, many literary-historical works tend to focus on the individuality of the works. Subgenres provide a frame for the description of groups of works. However, they are rarely understood as strict classes and more often as anchor points that help to analyze and represent a complex overall novelistic production in an ordered way.239
275The subgenre labels assigned to the novels by literary historians have a different status than those occurring explicitly in the titles and other paratexts of the novels and those that are or signaled implicitly in the texts. Literary historical labels do not represent a contemporary perspective, and the agents who decided on the labels are different. They are scholars of the twentieth and twenty-first centuries aiming to provide systematic perspectives on the novelistic production of the nineteenth century and not authors, editors, or contemporary critics. Nevertheless, the labels do not behave differently as a whole. Like every author, editor, or contemporary might use the labels in a slightly different manner, also the approaches of scholars can differ. Definitions of subgenres and criteria for the composition of the corpus are more often given in studies that concentrate on one subgenre of the novel.240 In general literary histories that are dedicated to a whole range of genres and subgenres, it is usually not explicitly discussed how the works were assigned to the subgenres. Comparative studies concerned with several types of subgenres are rare.241 When no definitions of the subgenres are given, it can only be hypothesized how the assignments come about: they might be based on explicit historical labels, on previous assignments made by other literary historians, or on background knowledge and reading experience. As a result, the focus here is not on how the subgenre terms are defined in each case but the fact that they are signaled by literary historians. Together with the explicit and implicit signals found in the texts of the novels themselves, the subgenres emerge as categories that are collectively defined, and this includes a certain fuzziness.
276Returning to the levels into which the subgenre labels – explicit, implicit, and literary-historical ones – are sorted in the summary, some more remarks are to be made. Regarding the relationship to the model proposed by Raible, it is evident that his model is a semiotic one in the linguistic sense of the term. Raible’s model, designed for literary and also non-literary genres, covers general aspects of the communication situation, the content and structure of the message, the medium, and the linguistic representation. With the level concerning the relationship between the text and reality, he addresses a point specifically relevant for literary texts. However, the aspects of the literary currents and cultural and linguistic identities of the texts are not covered by him.242 A model similar to Raible’s is the one developed by Jean-Marie Schaeffer, who also starts from the assumption that a literary work is a complex semiotic object and that generic terms can refer to different levels of this object. Broadly, Schaeffer distinguishes between the communicative act (“L’acte communicationnel”) and the realized discursive act (“L’acte discursif réalisé”). Raible’s level “Kommunikationssituation” overlaps with Schaeffer’s “L’acte communicationnel” and the “Objektbereich” with the “L’acte discursif réalisé”. The other levels defined by Raible can also be associated with Schaeffer’s two main levels. That is, also in Schaeffer’s semiotic approach, the levels that are named “identity” and “current” here are not included in the core model. Nevertheless, Schaeffer discusses these aspects as an aside:
Parmi les noms de genres que j’ai collectés, certains se réfèrent cependant à des déterminations qui sont irréductibles aux cinq niveaux de l’acte verbal que je viens de distinguer. J’ai indiqué plus haut que le modèle de la communication dont je me servais ne tenait pas compte du contexte, du lieu et du temps. Or, il existe de nombreux noms de genres qui sont composés à l’aide de déterminants de lieu ou de temps. Ainsi des termes comme tragédie élisabéthaine, tragédie classique, roman antique, sonnet baroque, etc., délimitent des traditions dans le temps, c’est-à-dire se réfèrent à des genres historiques au sense le plut fort du terme. [...]
La modification selon le lieu se rencontre sous deux formes. La première est celle de la spécification d’un genre selon les communautés linguistiques, mais à l’intérieur d’une sphère culturelle historiquement plus ou moins solidaire. Le phénomène est trés répandu en Occident: nous parlons ainsi de l’épopée grecque et de l’épopée romaine, du roman français et du roman anglais [...].
(Schaeffer 1983, 117–118Schaeffer, Jean-Marie. 1983. Qu’est-ce qu’un genre littéraire? Paris: Seuil.)
277Following Schaeffer’s explanations, generic terms referring to literary currents could be subsumed under the temporal context, and terms related to the linguistic and cultural identity under the spatial context. Schaeffer is aware that these aspects are not covered by his model, but also that most of the generic terms are not reducible to a single discursive level, neither regarding aspects of the verbal message (“the text”) nor contextual factors:
L’existence de se modifications temporelles et spatiales des noms de genres pose la question de la contextualization historiques des déterminations génériques, question que le schéma communicationnel que j’ai retenu occulte [...] elle ne peut évidemment que renforcer la conclusion qu’imposait déjà la prise en compte de la multidimensionnalité du message verbal, à savoir que les noms de genres, loin de déterminer tous un même objet qui serait « le texte » ou même un ou plusieurs niveaux invariants de ce texte, sont liés, selon les noms, aux aspects les plus divers des faits discursifs. (Schaeffer 1983, 119Schaeffer, Jean-Marie. 1983. Qu’est-ce qu’un genre littéraire? Paris: Seuil.)
278This is not only true for the terms associated with the levels
of theme and mode here, as could be seen in table 5 above, but also for the
groups of current and identity. Generic terms
referring to literary currents do not only localize the subgenre temporally
and historically. They also entail preferences regarding the themes of the
novels as well as stylistic properties. Similarly, the terms subsumed under
identity do not only relate to the cultural, geographical,
and linguistic localization of the novel as a discursive object but can also
point to thematic aspects of its content when American, Cuban, Argentinian,
or Mexican matters are treated. The assignment of terms to the levels thus
sets focuses for their analysis but is not to be understood as exhaustive or
exclusive. This is also the reason for the reduced modal level here compared
to the models of Raible and Schaeffer. With the modal subtypes of
intention, attitude, reality,
medium, and representation, the model used here
contains aspects of the communicative situation and the textual message that
revealed themselves to be relevant for the nineteenth-century
Spanish-American novels analyzed here because they are implied by explicit
subgenre labels. Figure
10 situates the categories of subgenre labels used in the encoding
model of the bibliography here in a more general communicative model mainly
based on the one proposed by Schaeffer.
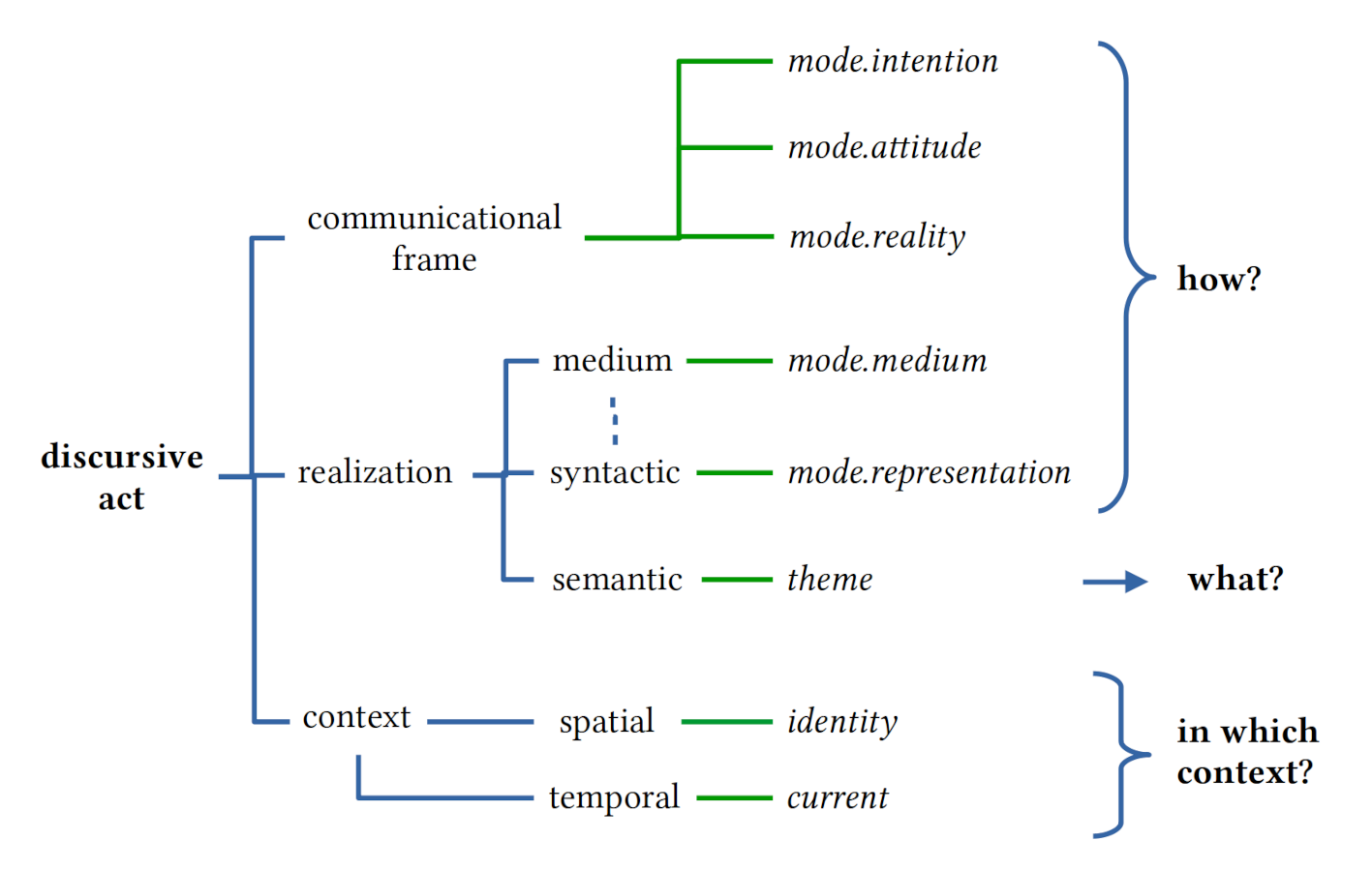
279The figure shows that the subtypes of intention, attitude, reality, medium, and representation can be grouped under the aspect of how the literary text is communicated and presented (mode). The category of theme stands for what is communicated, and the catetories of identity and current point to the context in which something is communicated.243 On the one hand, the model used for the bibliography and the corpus here has to be understood as an application, adaptation, and selection of the general semiotic models of (literary) genres. On the other hand, it is a bottom-up approach. Only those aspects of the general models that occur in the generic signals and literary-historical assignments of genres to the works in the bibliography and corpus of nineteenth-century Cuban, Argentine, and Mexican novels were selected. It is thus an empirically driven discursive model for generic terms of the novel in a specific cultural-geographical and historical context. It would be interesting to see which levels of the general models are activated for other corpora of the novel in order to find out which kinds of subgenre labels are typical for the novel in general and which ones are determined by contextual factors. When one looks at the relevance of the different levels for the whole set of novels, it can be observed that the levels of theme and current are the two main levels used in literary-historical approaches. Themes are also frequently involved in explicit historical subgenre labels, but regarding the quantitative relevance, only the novela histórica and the novela de costumbres stick out. The level of identity is very present among the top most frequent explicit labels but is only indirectly discussed in the critical literature.244 The level of mode.representation gains quantitative relevance because of the distinction between novels explicitly labeled as “novela” and those that are not. More specifically, there are also many “episodios” and “memorias”. The level of mode.reality plays an important role because many of the terms that are thematic also point to the relationship between text and reality (“novela histórica” and “leyenda”, for instance). The other modal categories (mode.intention, mode.attitude, mode.medium) are less important in terms of numbers but are also present. Intention and attitude play a role in terms that are also thematic, for example, in political novels. Terms related to the medium are creatively used by the authors in a range of different generic labels for the novels.245 Table 10 contains an alphabetically ordered list of all the different subgenre labels found for the novels in the bibliography and the corpus. In the table, it is indicated to which levels of the model the subgenre labels were assigned.246
| Subgenre label | Kind(s) | Supplement | Explicit occurrence |
|---|---|---|---|
| apuntamientos | mode.medium,
mode.representation |
- | yes |
| apuntes | mode.medium,
mode.representation |
- | yes |
| auto-novela | mode.reality | - | yes |
| Bildungsroman | theme | - | no |
| boceto | mode.medium,
mode.representation |
- | yes |
| bosquejo | mode.medium,
mode.representation |
- | yes |
| capricho | mode.representation | - | yes |
| cinematógrafo | mode.medium,
mode.representation |
- | yes |
| comedia de carácter | theme, mode.intention |
comedia | yes |
| confesiones | theme,
mode.representation |
- | yes |
| contornos | mode.representation | - | yes |
| croquis | mode.medium,
mode.representation |
- | yes |
| crónica | theme,
mode.representation |
novela histórica | yes |
| cuadros | mode.medium,
mode.representation |
novela de costumbres | yes |
| cuento | mode.representation | - | yes |
| drama | mode.representation | novela romántica | yes |
| elegía | theme, mode.medium, mode.attitude |
- | yes |
| ensayo | mode.representation | - | yes |
| entretenimientos | mode.intention | - | yes |
| episodios | mode.representation | novela histórica | yes |
| epopeya | theme,
mode.representation |
novela histórica | yes |
| esbozos | mode.representation,
mode.medium |
- | yes |
| escenas | mode.medium,
mode.representation |
- | yes |
| estudio | mode.representation,
mode.intention |
novela social, novela realista, novela naturalista |
yes |
| fragmentos | mode.representation | - | yes |
| historia | mode.representation | - | yes |
| impresiones | mode.representation | - | yes |
| juguete | mode.intention | - | yes |
| Künstlerroman | theme | - | no |
| lecturas | mode.intention | novela didáctica | yes |
| leyenda | theme, mode.reality |
novela histórica, novela romántica |
yes |
| medallones | mode.representation | - | yes |
| memorias | mode.representation (theme) | - | yes |
| narración | mode.representation | - | yes |
| notas | mode.medium,
mode.representation |
- | yes |
| novela | mode.representation | - | yes |
| novela abolicionista | theme (mode.attitude) | novela social | yes |
| novela americana | identity (theme) | - | yes |
| novela analítica | mode.representation (mode.intention) | - | yes |
| novela andaluza | identity (theme) | - | yes |
| novela anecdótica | mode.representation | - | yes |
| novela argentina | identity (theme) | - | yes |
| novela azteca | identity (theme) | (novela mexicana) | yes |
| novela biográfica | theme | - | no |
| novela bonaerense | identity (theme) | (novela argentina) | yes |
| novela camagüeyana | identity (theme) | (novela cubana) | yes |
| novela científica | theme, mode.reality |
- | (yes) |
| novela clasicista | current (theme) | - | no |
| novela cómica | mode.intention (mode.attitude) | novela humorística | (yes) |
| novela contemporánea | theme, mode.reality |
novela social and/or novela política | yes |
| novela corta | mode.representation | - | yes |
| novela criminal | theme | - | (yes) |
| novela criolla | identity (theme) | (novela americana) | yes |
| novela cubana | identity (theme) | - | yes |
| novela curiosa | mode.intention | - | yes |
| novela de actualidad | theme, mode.reality | novela contemporánea, novela social and/or novela política |
yes |
| novela de aventuras | theme | - | (yes) |
| novela de costumbres | theme (current) | (novela social) | yes |
| novela de crímenes | theme | novela criminal | yes |
| novela de familia | theme | novela social | no |
| novela habanera | identity (theme) | (novela cubana) | yes |
| novela de horrores | mode.intention | - | yes |
| novela de la ciudad | theme | novela social | no |
| novela de misterio | theme, mode.reality |
- | no |
| novela de propaganda | theme, mode.intention |
novela política and/or novela social | yes |
| novela de Tabasco | identity (theme) | (novela mexicana) | yes |
| novela de viajes | theme | - | (yes) |
| novela didáctica | theme, mode.intention |
novela social | yes |
| novela documentaria | theme,
mode.representation |
novela social and/or novela política | no |
| novela doméstica | theme | novela social | yes |
| novela en acción | theme | novela de aventuras | yes |
| novela enciclopédica | theme, mode.intention |
novela didáctica | yes |
| novela epistolar | mode.medium,
mode.representation |
- | yes |
| novela espiritista | theme, mode.reality |
novela científica | yes |
| novela fantástica | theme, mode.reality |
- | yes |
| novela festiva | mode.attitude | - | yes |
| novela filosófica | theme,
mode.representation |
- | yes |
| novela franco-argentina | identity (theme) | (novela argentina) | yes |
| novela gauchesca | theme | - | no |
| novela histórica | theme, mode.reality |
- | yes |
| novela humorística | mode.intention (mode.attitude) | - | yes |
| novela india | identity (theme) | - | yes |
| novela indigenista | theme | - | no |
| novela jurídica | theme | novela criminal | yes |
| novela kantabro-americana | identity (theme) | (novela americana) | yes |
| novela mexicana | identity (theme) | - | yes |
| novela militar | theme | novela histórica | yes |
| novela mixteca | identity (theme) | (novela mexicana) | yes |
| novela modernista | current (theme) | - | no |
| novela moralista | theme, mode.intention |
novela social | no |
| novela nacional | identity (theme) | - | yes |
| novela naturalista | current (theme) | novela realista, novela social | yes |
| novela original | identity | - | yes |
| novela patriótica | theme, identity |
- | yes |
| novela picaresca | theme | - | no |
| novela policial | theme | novela criminal | yes |
| novela política | theme, mode.attitude |
- | yes |
| novela popular | theme | novela social | yes |
| novela porteña | identity (theme) | (novela argentina) | yes |
| novela psicológica | theme,
mode.representation |
- | no |
| novela realista | current (theme) | novela social | yes |
| novela regional | theme, identity |
- | yes |
| novela romana | identity (theme) | - | yes |
| novela romántica | current (theme) | - | no |
| novela satírica | mode.attitude | - | yes |
| novela sentimental | theme | - | yes |
| novela siciliana | identity (theme) | - | yes |
| novela social | theme (mode.intention) | - | yes |
| novela suriana | identity (theme) | - | yes |
| novela tapatía | identity (theme) | (novela mexicana) | yes |
| novela verista | current (theme) | novela realista, novela social | no |
| novela yucateca | identity (theme) | (novela mexicana) | yes |
| panorama | mode.medium,
mode.representation |
- | yes |
| perfiles | mode.representation | - | yes |
| páginas | mode.medium,
mode.representation |
- | yes |
| recuerdos | mode.representation,
theme |
- | yes |
| reflexiones | mode.representation | novela filosófica | yes |
| relación | mode.representation | - | yes |
| relato | mode.representation | - | yes |
| reseña | mode.attitude,
mode.representation |
- | yes |
| romance | theme,
mode.representation |
novela sentimental, novela histórica | yes |
| silueta | mode.representation | - | yes |
| tradición | theme, mode.reality |
- | yes |
| tragedia | theme,
mode.representation |
- | yes |
280The generic terms consist of nouns (“Bildungsroman”, “croquis”, “episodios”) or nouns that are characterized further by attributes (“novela argentina”, “novela de costumbres”, “novela histórica”). One or several kinds of subgenre labels that are considered the most important are given for each term. Kinds in parentheses mean that these are also possible assignments but that they were not encoded in the bibliography because they were not considered crucial and in order not to mix the categories too much. In general, it is assumed here that generic terms are complex signs and that many of the terms refer to different levels of discourse. For example, the term “novela naturalista” refers to the literary current of Naturalism, but also to the themes preferred by that current, i.e., social topics, including the account of the situation of outsiders and lower classes, and tabooed subjects such as adultery or prostitution. Furthermore, it refers to certain representational techniques used in naturalist novels and so on. The generic terms are loaded semantically through the characteristics of the works that carry the terms over time. However, it is also assumed here that there are differences in how relevant the different levels are for the terms and that it is possible to determine primary levels. For example, the term “memorias” is assigned to the level of mode.representation here and only secondary to the level of theme. Even though memories can imply certain themes (a life story, for example), the themes are not very specific and the presentation of the text in the form of memories, looking back on what was experienced and is remembered, is more important. Other examples are the terms referring to literary currents, for instance, “novela realista” or “novela romántica”. Although they are also connected to certain themes, this aspect is considered subordinate here. The same was decided for terms referring to a certain city, region, nation, or people, such as “novela habanera”, “novela de Tabasco”, “novela mexicana”, or “novela azteca”, for which the level of identity is taken as the primary level and thematic aspects as secondary. That way these subgenres are differentiated from the ones that are primarily thematic, for example, “novela sentimental”, “novela histórica”, or “novela de costumbres”.
281The third column in the table indicates subgenres that are implied by the term in the first column. For example, the term “crónica” often includes a historical theme, and the terms “novela naturalista” and “novela realista” often include social themes. The supplements can serve to normalize terms, to generalize them, and to make other levels that are implied by such terms explicit. The supplements are not automatically assigned, though. They are assigned depending on whether they make sense in the individual case. Some of the possible supplements are given in parentheses in the table. These are not assigned in the bibliography and the corpus to make the subgenres more distinguishable. The “novela de costumbre”, for example, could also be understood as a form of social novel but would then have the same thematic label as naturalistic and realist novels because the term “social” has so many facets.
282The last column of the table indicates whether the generic term occurs explicitly in the bibliography or not. A “yes” in parentheses means that the term occurs, but only in a normalized explicit form and not verbatim. Examples of terms that never occur explicitly in the bibliography but are often used by critics to characterize the novels are “novela gauchesca”, “novela indigenista”, and “novela romántica”. Others that occur primarily in the explicit form are, for example, “novela jurídica” or “novela contemporánea”.
283The goal of the systematization of subgenre labels by normalizing terms and assigning them to different levels of discourse is to put the whole range of generic terms associated with the novels through explicit or implicit paratextual elements and critical assignments in a certain order to be able to analyze groups of the novels quantitatively. Effectively, the set of generic terms with which novels are designated is open and endless, full of variants and nuances, as already the terms in the table show. If one would take the terms as they are, in many cases, it would be difficult to form groups. For instance, there are “novelas jurídicas”, “novelas policiales”, and “novelas de crímenes”, which are subsumed under the term “novela criminal” here because it is assumed that these terms can be interpreted as referring to the same subgenre. On the other hand, it would be challenging to analyze subgenres that are defined on entirely different levels of discourse together, for example, a “novela romántica” compared to a “novela mexicana” or a “novela fantástica”. The whole structure of subgenres is not organized hierarchically and it does not consider historical change.
284To summarize, the assignment of subgenres to the novels discussed in this section follows a strategy that is, for one thing, historically oriented, because all the explicit labels occurring in the titles of the novels in the bibliography (and also in other paratexts for the novels in the corpus) are collected, and furthermore, also implicit signals are evaluated. Explicit signals are normalized in order to make them comparable, and the interpretation of implicit signals requires prior knowledge about the subgenres, but all the steps are documented to make the process transparent. In general, historically adequate terms are preferred over ahistorical critical ones. Then again, the information available from historical signals is complemented by subgenre assignments made by literary critics in order to also open up those novels to an analysis of subgenres that would otherwise have to be considered general fiction because there are no clear signals available from the paratexts. However, because the sources of the generic information are encoded in detail for each entry in the bibliography (and corpus), it is possible to conduct analyses only on one or the other kind of information or to backtrack the statements about subgenres when the results of a combined analysis are interpreted.
285No previous selection of certain types of subgenres was made. Instead, within the frame of the general, formal working definition of the novel provided in chapter 3.1.1.7 above, all kinds of generic information were collected. The information was then systematized in summarizing terms, following a discursive model based on other general, semiotic models of generic names. That way, it was captured which (types of) subgenre labels are the most frequent in the bibliography. Regarding explicit labels, the distinction between works carrying the label “novela” and those that do not is quantitatively relevant. Regarding thematic aspects, “novelas históricas” and “novelas de costumbres” are frequent. Furthermore, there is a considerable group of novels that have a label related to the cultural and linguistic identity of the text (“novela original”, “novela mexicana”, etc.) as opposed to a bigger group of novels that does not have such a generic signal. When also implicit signals and literary-historical labels are considered, the most frequent kinds of subgenre labels are thematic or refer to the literary current(s) of the texts. Even if other kinds of subgenre labels are not so frequent, for example, labels concerning the representational mode of the text (other than the general term “novela”) or labels pertaining to the groups of intention, attitude, reality, or medium, this generic information is still valuable as background information when other subgenres are analyzed, and when the results need to be interpreted. The great variety of subgenre labels found for the works in the bibliography shows how open the genre novela is in general and how extensive the network of generic references is. Even labels referring to other major genres (e.g., “drama”, “tragedia”, “comedia”, “epopeya”, etc.) are used to mark novels. On the other hand, only a few subgenres were very frequent in the period and countries examined in this study.
286Based on the general information about the Argentine, Cuban, and Mexican novels published between 1830 and 1910 that was collected for the digital bibliography Bib-ACMé, a corpus of digital full texts called Conha19 (“Corpus de novelas hispanoamericanas del siglo XIX”) was prepared. The resulting text collection is aimed to be used for digital, quantitative literary analysis. While there is a long tradition of preparing and using digital corpora for linguistics,247 the development of best practices for creating digital literary corpora is still underway. Of course, the use of corpora for literary scholarship also has its history. However, it is traditionally more closely related to scholarly textual editing and the preparation of smaller datasets as a basis for qualitative interpretation.248 Recently, also the creation of bigger corpora of digital literary texts suitable for quantitative analyses has been reflected.249 Hoover, Culpeper, and O’Halloran (2014Hoover, David L., Jonathan Culpeper, and Kieran O’Halloran. 2014. Digital Literary Studies: Corpus Approaches to Poetry, Prose and Drama. New York, London: Routledge.), for example, emphasize how valuable the methods developed in corpus linguistics are for the digital study of literary texts, as well. They build and analyze corpora of character speech from dramatic texts, novels, and lyric poems. In the project CLiGS, the context in which this dissertation is elaborated, we have developed small prototypical digital collections of literary texts in Romance languages (French, Spanish, Italian, and Portuguese). We concentrated on practical aspects, including the compilation of texts, the collection of metadata, text encoding, publishing, archiving, and how to encourage reuse (Schöch et al. 2019Schöch, Christof, José Calvo Tello, Ulrike Henny-Krahmer, and Stefanie Popp. 2019. “The CLiGS Textbox: Building and Using Collections of Literary Texts in Romance Languages Encoded in TEI XML.” Journal of the Text Encoding Initiative. Rolling Issue. https://doi.org/10.4000/jtei.2085.). Another example of a project practicing and reflecting the creation of corpora for digital literary analysis was the COST Action “Distant Reading for European Literary History”, which involved creating a diachronic, multilingual corpus of novels from 1840–1919 called “The European Literary Text Collection” (ELTeC) (Odebrecht et al. 2021Odebrecht, Carolin, Lou Burnard, and Christof Schöch, eds. 2021. “European Literary Text Collection (ELTeC).” Version 1.1.0. COST Action Distant Reading for European Literary History (CA16204). https://doi.org/10.5281/zenodo.4662444.).
287In this chapter, these developments are taken into account. The chapter serves to clarify questions of text selection, text treatment, metadata, and text encoding, the assignment of subgenre labels, the creation of derivative corpus formats, and its publication. The chapter is organized as follows: How the novels were selected for the corpus and which sources were used is described in chapter 3.3.1 below. In chapter 3.3.2, it is explained how the full texts were obtained from digitized images and how the quality of the resulting texts was checked. This step is also important for full texts that were directly included from other sources. Just as for the bibliography, it was decided to encode the texts in XML, according to the standard of the Text Encoding Initiative (TEI). That way, structural information such as chapter divisions or headings could be added to the texts, and the metadata for the novels could be included in each file. The kind of metadata that was collected and the model of text encoding that was applied are presented in chapter 3.3.3. A special focus is given to the assignment of the subgenre labels, which is discussed in chapter 3.3.4. Chapter 3.3.5 serves to present two derivative corpus formats (plain text and a linguistically annotated version) and to explain the publication strategy for the corpus. The contents of the corpus are presented in chapter 4.1 on “Metadata Analysis”, where they are related to those of the whole bibliography of novels.
288A special challenge in creating a corpus for genre analysis is the so-called chicken-and-egg problem: a genre can only be analyzed in the form of individual texts attributed to it, but a previous definition of the genre is needed for selecting these texts. From a genre theoretical perspective, two approaches are proposed to handle the problem: following the inductive approach, a corpus is built without a previous working definition of the genre, and texts are, for example, chosen because of historical labels, with the drawback that not all of the relevant texts necessarily carry the same label and that the meaning of the labels is subject to change. Another possibility is a deductive approach starting from a general definition of the genre, which serves to organize the historical material. It has the advantage that the definition is clear, but the disadvantage is that it is not necessarily historically adequate. According to Zymner, both procedures lead to contradictions, and in practice, mixed approaches are more common (Zymner 2010, 23–24Zymner, Rüdiger, ed. 2010. Handbuch Gattungstheorie. Stuttgart: J.B. Metzler.). The strategy for creating the corpus at hand can also be characterized as a mixed one. It starts from a general, formal working definition of the novel (see chapter 3.1.1.7 above) which is the deductive aspect, but the subgenres of the novel are not previously defined formally. Rather, they are established based on explicit historical labels and implicit signals as well as a range of literary-historical assignments. For a large digital corpus, this strategy has the advantage that the elements of a general definition of the novel are easier to check than aspects of specific definitions of subgenres of the novel. In addition, that way, the analysis of subgenres is not predetermined theoretically.
289Based on the data collected for Bib-ACMé, a corpus of 256 novels was created. The novels that are included in the bibliography were, in principle, all eligible for the text corpus, as well, because the selection criteria as outlined in chapter 3.1 above were applied to the bibliographic entries. Nevertheless, the novels were checked again before they were taken over from a source because insight into the full texts allowed for a stricter application of the selection criteria. For example, the extent of the text could be measured in the number of words instead of pages. Furthermore, the text and not just the work title could be checked for signals of fictionality.
290Two main factors determined which texts from the bibliography were selected to be included in the text corpus: first, characteristics of the texts influencing the balance of subgroups in the corpus, and second, practical matters regarding the availability of the texts. As to the first factor, the corpus seeks to assemble several large groups of novels belonging to certain subgenres to be able to analyze these quantitatively. Therefore, texts pertaining to subgenres that were common in the nineteenth century, namely the thematically oriented subgenres of novelas históricas, novelas de costumbres, and novelas sentimentales, and subgenres related to different literary currents, i.e., novelas románticas, novelas realistas, and novelas naturalistas were preferred. On the other hand, the aim was to create a corpus reasonably balanced by country, publication date, and author. In this context, balanced does not mean achieving an equal number of texts from all the authors, the three countries, and the years between 1840 and 1910. Such a corpus would be an artificial construct and hardly possible to realize because the bibliographic data shows that the number of novels published in Argentina, Cuba, and Mexico in the different phases of the nineteenth century differs significantly. The number of novels published by individual authors also varies greatly. Rather, the aim was to build a corpus that is balanced under the conditions of the population. For example, when having the choice to include either three novels written by the same author in the same decade or three novels written by different authors and published in different decades, the second option was preferred.250 The second factor influencing the shape of the corpus – the availability of the texts – also affected the first one. The overall availability and the state of digitization of the texts varies for the three countries, the different points in time, and for the individual authors. In general, older texts are rarer, Cuban novels harder to obtain than Argentine and Mexican ones, and works of less canonized authors more difficult to procure. Moreover, the novels that were already available in a digital full-text format belong to a broad range of subgenres. They were all included so that the corpus does not exclusively contain novels of the subgenres that are analyzed in more detail. The selection of texts was prioritized according to the following practical availabilities to keep the creation of the corpus feasible:
291The majority of the novels in the corpus (81.3 % or 208 texts)
was collected from digital sources and only about one fifth (18.8 % or 48
texts) from print sources.252 The print sources were mainly used to
complement the corpus in terms of subgenres. Regarding the file formats of the
sources for the texts in the corpus, one sees that only about one-third of the
novels (32 % or 82 texts) was available in a full-text format whereas more than
three-thirds (68 % or 174 texts) were obtained from image files. Obviously, all
the print sources were converted to digital images, but also the majority of
the digital sources were only accessible as image files. All the novels that
were available in a full-text format were included, so the proportions of file
types underline the need for more full-text digitization. Without the work of
extracting text from digital images, this dissertation would not have been
possible because the corpus would have been too small and unbalanced.
292Figure 11 gives an
overview of the different institutional sources used to obtain the text of the
novels. More than 30 different sources were used. In the chart, the sources are
ordered by the number of texts taken from them. Some of the sources were
grouped: individual websites, for example, about single authors, and university
libraries from which printed books were loaned are not listed separately.
Around 65 % of the novels were obtained from six main sources:253 the “Biblioteca Virtual Miguel
de Cervantes” (15.2 % or 39 texts), university libraries (14.5 % or 37 texts),
the “Internet Archive” (10.2 % or 26 texts), the “HathiTrust Digital Library”
(9.38 % or 24 texts), the “Ibero-Amerikanisches Institut” (8.59 % or 22 texts),
and “Wikimedia Commons” (7.42 % or 19 texts).254 Already the main sources show
that the corpus was gathered from a broad range of sources because there is no
general, comprehensive digital repository for Spanish-American
nineteenth-century novels yet. The “Biblioteca Virtual Miguel de Cervantes” is
a very important source because it contains many texts in HTML format and
novels from many Spanish-American countries.255 University
libraries constitute the most important kind of source for printed editions of
novels that were scanned and OCRed for this corpus.256 Two of the other main sources are
general repositories of multimedia content: the “Internet Archive” and
“Wikimedia Commons”. The “HathiTrust Digital Library”, a collaborative platform
of academic and research libraries based in the USA, and the
“Ibero-Amerikanisches Institut”, a German library specialized on Ibero American
literature, were also significant sources.257 Of course, several
novels are available in more than one repository or library, so the overview
given here is also the result of the text collection strategy pursued for this
dissertation.258 Because the “Biblioteca Virtual Miguel de Cervantes” was
consulted first to obtain the digital full-texts, it is the most prominent
source. However, it is also important to note that some of the other sources
have great potential: the “Internet Archive” and the “HathiTrust Digital
Library” contain many more Spanish-American nineteenth-century novels than the
ones included in this corpus.259 With more resources, the
full text of these novels could be extracted, as well, to build a more
extensive corpus for future research in the area. The digital library of the
“Ibero-Amerikanisches Institut” is also constantly expanding, so it can be
expected that this institution will play a major role as a source of
Spanish-American literature in digital format in the future.
293Figure 12 demonstrates which file types were obtained from which sources. The upper chart shows the institutions from which image files were obtained (68 % of the novels in the corpus), and the lower chart the ones for text files (32 % of the novels). It becomes clear that the “Biblioteca Virtual Miguel de Cervantes” is the only major source offering digital full texts and that more than half of the full texts were collected from minor sources. On the other hand, many of the institutions that offer Argentine, Cuban, and Mexican nineteenth-century novels only publish digital images.260 The number and variety of sources used for this corpus shows that there is still much work to be done to facilitate future research on digital text analysis of nineteenth-century Spanish-American novels. For example, a supra-institutional portal gathering and pointing to different sources would be very helpful. Some of the above sources are designed as such portals, but they are still quite specialized or selective regarding the kind of information they provide. Furthermore, much more full-text digitization is needed to free future research projects from the necessity to invest considerable time and effort in full-text digitization before being able to analyze their corpus.
294Because of the number and kind of different sources, it was indispensable for this corpus to control the quality of the incoming texts.261 One question is how many novels were obtained from scholarly sources and how many from general ones.262 Only two-thirds of the texts (64.1 %) come from repositories that can be associated with scholarly undertakings. Having in mind that the text analysis done for this dissertation aims to be scholarly, the share of general sources is large. Usually, the scholarly sources are more reliable regarding the provision of metadata about the texts and in terms of long-term stability, but not principally. The stability and accuracy are also connected to the general scope, relevance, and functioning of the (digital) institutions. The platforms of the Wikimedia Foundation (“Wikisource” and “Wikimedia Commons”), for example, are stable, or rather, changes and enhancements are well documented. At the same time, minor institutional websites are more prone to be altered or to disappear.263
295Another relevant question about the corpus sources is which kind of editions underlie the digital or print sources of the novels. The kinds of editions were grouped into four categories:
296In view of the above, it becomes clear that the selection of novels for the corpus was guided by criteria related to the genre and other factors influencing the style of the texts but that the possibilities to compile a representative and balanced corpus were also limited by practical aspects concerning the availability of the texts from different sources and in different formats. One-third of the texts were already available in a full-text format, one-fifth was digitized, and the rest was extracted from image files. In total, more than 30 different sources were used, and different types of editions (first editions, other historical editions and modern ones) had to be employed. In light of the non-uniform composition of the corpus regarding its sources, the text of the novels had to be treated in different ways and to be checked to homogenize the collection, which is described in the following chapter.
297Depending on the type of source, the text of the novels for the corpus had to be prepared differently. The further away a source text was from a high-quality digital full text, the more steps were necessary. Table 11 lists the different processing steps that were followed. In the case of a printed book, all the steps had to be undertaken. If, in contrast, the source was an HTML file containing the full text of a novel, only the last two steps were carried out. The other types of sources required a number of processing steps between the two extremes. The preparation of the full text also included the addition of basic structural information in the form of markup, because adding this kind of information was intended anyway, and the goal was not to lose existing relevant information.
| Step | Type of source | |
|---|---|---|
| 1 | Scanning | Printed books |
| 2 | OCR | Image files and image-based PDF files |
| 3 | Correction of OCR results | OCR-output |
| 4 | Conversion and/or addition of structural information | Corrected OCR-output, HTML-Files, plain text files |
| 5 | Spell check | Full text |
298The first step, scanning, was necessary for novels that were only accessible as printed books. A selection of books was scanned by the “Ibero-Amerikanisches Institut“ (IAI) in Berlin and added to their digital library. The books can be viewed online and downloaded as a PDF file. In the digital library of the IAI, the books are enriched with general, administrative, and structural metadata, including the assignment of persistent identifiers.266 The library also holds high-quality images of the scans. The remainder of the books that needed to be scanned were treated by the author of this dissertation. The scans were done at the University of Würzburg with ordinary scanners in the library. They were done in an ad-hoc manner with the goal of being able to extract the text of the novels and not of keeping the image files. The scans were mainly done of modern editions, and the development of a professional digitization workflow like the one that the IAI established was not part of the CLiGS project. The bibliographical metadata added to the resulting files can still be inspected to check which editions were used as a basis for the texts.
299The second step involved the conversion of the digital images of printed text into machine-readable text with the help of optical character recognition (OCR). This applied to scans of printed books and also to novels already available in the form of image files or image-based PDF files. The software used to perform the OCR was ABBYY Finereader 12 Professional because it proved to achieve good results for nineteenth-century texts in the Spanish language.267 All the novels processed with ABBYY Finereader were checked page by page to correct the results of the OCR. General mistakes were corrected with the help of the Find/Replace routines of the software, and individual mistakes were corrected on the pages themselves.
300Because the source editions were historical as well as modern ones,268 it was decided to unify the orthography to a modern one as far as possible. There are several reasons for this decision. First, the aim of this study is not detailed historical linguistic analyses of the texts but stylistic analyses focusing on general linguistic and semantic aspects of the novels.269 Second, it would not have been possible to only use source editions from a certain historical point, so a unifying strategy was necessary anyway, and modern editions can hardly be converted back to a historical spelling. Third, most natural language processing (NLP) tools that support Spanish as a language expect a modern spelling, so historical spellings would have led to additional problems in the analyses of the texts. Fourth, with the standard setting for the Spanish language, ABBYY Finereader automatically corrects many words to a modern spelling. Instead of considering this a drawback, it was taken advantage of. The most frequent words that were corrected were conjunctions and prepositions (á/é/ó/ú → a/e/o/u), the adverb “mas” (→ “más”), and verb forms in the preterite imperfect (e.g., “hacia” → “hacía”, “sabia” → “sabía”, “venia” → “venía”). A problem that persisted were verb forms that included enclitic pronouns such as “decíale” (instead of “le decía”), “olvidábasenos” (instead of “se nos olvidaba”), “viose” (instead of “se vio”), and so on because they cannot easily be changed automatically. As a result, in some of the texts in the corpus, the old verb forms are included, whereas others only have modern forms. It has to be kept in mind that stylistic analyses involving, for example, the examination of the usage of archaic forms as a typical sign of certain subgenres, for instance, historical novels, are not possible here because of the different types of source editions. Furthermore, the composite verb forms might cause problems for some NLP tools.
301Corrections in the text (neither corrections of obvious errors in the OCR results nor orthographic modernizations) were not encoded in detail. This decision was made because the focus of the CLiGS project was not on the creation of scholarly historical editions but on large-scale stylistic analyses of digital text. Of course, the basic full texts produced in this project could be used as a starting point for the creation of critical editions, but to undertake these encoding steps for hundreds of novels would not have been neither plausible nor manageable here.270
302The next processing step was adding structural information, or, if such information was already present in the source files, its conversion. This step was applied to the corrected OCR output, but also if the sources were HTML or plain text files. The goal was to create a basic structural markup for the novels, including the encoding of headings, paragraphs, chapters, and parts of the novels. The target format chosen is the encoding standard of the Text Encoding Initiative (TEI). As this is the general data format used for the corpus of novels, it is described in more detail in the following chapter 3.3.3 on metadata and text encoding. In the case of plain text files, blank lines indicating paragraph boundaries were exploited with regular expressions. From HTML files, all relevant structures were extracted either with the help of XSLT scripts or with Python scripts using regular expressions, depending on whether the HTML files could be processed as well-formed XML files (a requirement for the XSLT processor) or not. Depending on the kind of web source, in some cases, the download of the HTML files also involved the scraping of individual pages (e.g., chapters) that belonged to the same novel before the files could be processed further.271 Because there is an option to export the OCR output from ABBYY Finereader as HTML, the files processed with this software could also be transformed to basic TEI with the help of an XSLT script.272 Most of the scripts used for crawling web pages and for converting or adding structural information were written in an ad-hoc manner and changed from source to source. In some cases, the HTML structure was inconsistent from novel to novel, even within the same source repository. All the resulting basic structures (parts, chapters, headings, and paragraphs) were checked manually.273 Some contents and structures were not taken over: In the case of modern editions, prefaces, introductions, and appendices written by the editors were left aside, primarily to prevent copyright issues when publishing the corpus. On the other hand, historical title pages, dedications, and prefaces were kept because they were checked for generic signals.274 Some novels contain pictures illustrating selected scenes of the plot. These were dropped because the analysis of illustrations is not intended here. Notes by authors as well as editors were not kept. Even though authorial notes tend to be more frequent in some subgenres of the novel (historical novels and science fiction novels, for instance) it was not possible to distinguish between authorial and editorial notes in all cases. Even though the goal of this project was not to create critical editions of the texts, one phenomenon was nevertheless documented: gaps in the text. Reasons for gaps are:
303The last step in the pipeline of text treatment was a spell
check, which was applied to the full texts resulting from the previous
processing steps. With the final spell check, it was intended to find errors
remaining after the OCR correction of texts that were obtained from digital
images. Texts obtained from existing plain text and HTML files were also
checked because of the great variety of sources. A Python module was written to
perform the spell check with the library PyEnchant.277 One of the backends used by the underlying Enchant
library is MySpell, a project also used in OpenOffice (or LibreOffice) to
perform spell checks. Via MySpell, dictionaries for several languages are
available, including Spanish. The spell check can be performed for individual
files or a whole collection of text files. It is possible to indicate files
with exception words containing, for example, proper names of people and places
or words from foreign languages. For the corpus of Spanish-American novels, the
spell check was performed for each file individually. The lists were then
checked for genuine errors, including errors resulting from the OCR process,
orthographic errors contained in full-text files from external sources, or
errors resulting from historical spellings. All the genuine errors that
occurred more than once in a file were corrected. That way, the most frequent
and typical errors were solved. However, for reasons of time, it was not
possible to also correct all the errors occurring only once because of their
sheer number in some cases. Even if the resulting full texts are not perfect,
the spell check helped to get an impression of the orthographic quality of all
the texts in the collection, and it was helpful to align the level of
correctness of the files obtained from different sources. In general, the full
text extracted from modern editions or obtained from portals that themselves
checked the texts has a higher quality than text extracted from historical
editions or collected from sites without their own quality control. It is
important to note, though, that the quality was checked against a dictionary of
modern Spanish here.278 In
figures 14 and 15, the distribution of the spelling errors that
remained after the correction of the individual texts is displayed. No lists of
exception words were included.279
304The figures show that the frequency of the errors drops quite
sharply, but also that many different errors remain. The total number of
different errors is 66,399, which is 33,6 % of the whole vocabulary of the
collection,280 which is quite a lot. Nevertheless, 62.5 %
(i.e., 21 % of the vocabulary) of the different errors occur only once, and
only 7.6 % (2.5 % of the vocabulary) occur more than ten times. Consequently,
regarding not the types but the tokens, the proportions are different: The
total number of errors is 543,693, which is 3.2 % of all the tokens in the
collection.281 41,481 (0.2 %) of the
tokens are errors that occur only once, and 430,284 (2.5 %) are mistakes with
more than ten occurrences. What follows from these numbers regarding the
analysis of the texts? First, measures of statistical similarity will probably
not be influenced too much by the errors because most of them are so
infrequent. On the other hand, an analysis of the hapax legomena282 in the corpus is not advisable.283
However, the above numbers represent all of the words that were not recognized
by the spell checker, but many of them and especially the frequent errors that
were not corrected in the individual files during the preparation of the texts,
are not genuine errors. The most frequent error in the whole collection, for
example, is the word “vd”, an abbreviation for the personal pronoun “usted”,
with 11,145 occurrences. Figure
16 shows the top 30 most frequent spelling errors in the corpus.284
305Among the most frequent errors, there are, for example, forms of address (“vd”, “v”, “ud” → “Vd.”, “V.”, “Ud.” → “usted”; “V. A. → “Vuestra Alteza”; “V. E.” → “Vuestra Excelencia”; “V. R.” → “Vuestra Reverencia”; “V. S.” → “Vuestra Señoría; “d” → “D.”, “D.ª”, → “Don”, “Doña”; “s” → “S. M.” → “Su Majestad”, etc.). The individual letters “v” and “s” can also stand for other words, for example, the number five (“V”) or the word “San” (as in “S. Fernando”, “S. Juan de Dios”, etc.). Apart from that, most of the top errors are proper names (“María”, “Juan”, “Pedro”, etc.) and place names (“México”, “España”). A possibility to exclude these errors from the results of the spell check is to create lists with exception words.
306Several strategies were followed to generate exception lists for the spell check of the corpus. First, free lists of exception words available on the web were used to see which of the items contained in them also occur in the error list resulting from the previous spell check round. The matching items were then stored in corpus-specific exception lists, which can be further adapted manually. This strategy was followed for proper names, surnames, names of countries, and capitals.285 Table 12 summarizes how many supposed error words could be mapped that way.286
| Noun type | Word number in list | Number of error types covered | Number of error tokens covered | ||
|---|---|---|---|---|---|
| proper names | 455 | 282 | 0.42 % | 125,906 | 23.2 % |
| surnames | 103 | 42 | 0.06 % | 12,772 | 2.3 % |
| countries | 193 | 60 | 0.09 % | 9,274 | 1.7 % |
| capitals | 182 | 33 | 0.05 % | 2,315 | 0.4 % |
| Sum: | 933 | 417 | 0.62 % | 150,267 | 27.6 % |
307The table shows that from the four external word lists, the one with proper names was most useful because more than half of the names it contains occur in the spell check results, and the total amount of error tokens could be reduced by more than one-fifth using this list. The other three lists with surnames, countries, and capitals did only have a minor effect.
308The second strategy that was pursued to generate exception lists
was the usage of word patterns expressed as regular expressions. Looking at the
spell check results, many false errors from specific word classes stood out,
among them words with diminutive suffixes (e.g., “abuelito”), superlatives
(e.g., “interesantísimo”), adverbs ending in “mente” (e.g., “aceptablemente”),
and verb forms with pronoun suffixes, of which many are archaic (e.g.,
“diósele”). In all these cases, the range of possible words is so extensive
that it is hardly possible to match them individually. Even with the use of a
dictionary, productive word formations would not be covered. However, it is
possible to match these kinds of words fairly accurately with patterns. The
regular expression “.*i(t|ll)(a|o)s?\b”, for example,
matches all the diminutive words ending in “-ito”, “-itos”, “-ita”, “-itas”,
“-illo”, “-illos”, “-illa”, and “-illas”, such as, for instance, “abuelita”,
“caminillo”, or “milloncitos”. Compared to word lists, patterns have the
advantage that many more forms can be matched without the need to anticipate
their exact construction. A slight disadvantage of the patterns is that they
can also cover false positives. In the case of the diminutives, for example,
also proper names and misspelled general nouns were matched: “Antillas”,
“álito” (which should be “hálito”), “exito” (which should be “éxito”), and
“estrepito” (which should be “estreṕito”). Furthermore, the use of patterns is
only reasonable if the morphology of the language allows it to match specific
word classes quite unambiguously. Fortunately, this is possible for Spanish
diminutives, superlatives, adverbs, and verb forms with pronoun suffixes.
309The patterns were used in the same way as the word lists. They were applied to the error list resulting from the spell check to generate a corpus-specific list of exception words, which can then be used in the next spell check round. To have such corpus-specific lists is not only useful for the spell check process. It can also be interesting to analyze them from a stylistic point of view, to find out which texts or groups of texts contain many non-standard words of a certain kind. For example, they could be used to see how frequent the diminutives are in novels of a particular genre, from certain countries, or authors. Furthermore, the exception lists can help to improve the results of natural language processing tools that do not recognize certain non-standard word forms, for example, if they are not based on a model of historical Spanish.287
310It is more complex to map the verb forms with pronoun suffixes than the diminutives, superlatives, and adverbs because many more combinations of forms are possible. These are verb forms to which reflexive, passive, and personal pronouns are directly suffixed, for example, “ofrecióselas” instead of “se las ofreció”, “oíasele” instead of “se le oía”, or “urgíame” instead of “me urgía”. In table 13, regular expressions to map such forms are displayed.
| Pattern | Kind of verb forms matched | Examples from the corpus |
|---|---|---|
.*[aei]rse\b |
infinitivo with a reflexive pronoun | celebrarse, apetecerse, percibirse |
.*[aeiáéí]r(se)?l[eao]s?\b |
infinitivo with a reflexive pronoun and with a personal pronoun in third person singular or plural in dative or accusative | estarle, caerle, irle, oírlo, serles, mostrarselo, torcérselas |
.*[áéíóú]r[ae]n?se\b |
presente, pretérito indefindo in third person singular or plural with a reflexive or passive pronoun | hubiérase, érase, ignórase, asegúrase, refiérese, palpáranse |
.*[éóo][mts]e\b |
presente, gerundio, futuro simple, pretérito indefinido, pretérito (pluscuam)perfecto in first or third person singular, with a reflexive or passive pronoun, or with a personal pronoun in 1st or second person singular | encaminéme, miréte, parecióme, ruégote, levantóse, detúvose, irguiéndose, decorádose, hubiése, diréte |
.*[éó]l[eao]s?\b |
pretérito indefinido in first or third person singular with a pronoun in third person singular or plural in dative or accusative | contéle, alarguéla, preguntóle, tomóla, parecióles, chingólos |
.*[áé]ndol[eao]s?\b |
gerundio with a personal pronoun in third person singular or plural in dative or accusative | temblándole, siéndole, reflexionándolo, faltándoles |
.*[éóo][mts]el[eao]s?\b |
presente, gerundio, pretérito indefinido in first or third person singular, with a reflexive pronoun or a personal pronoun in first, second or third person singular in dative or accusative | entreguéselo, diómela, avisándotelo, acercándosele, ocurriósele, pelándoselas, hubiésele |
.*[éóo]n?os\b |
presente, imperativo, gerundio, pretérito indefinido in first or second person singular or plural, or third person singular, with a personal pronoun in first and second person plural in dative or accusative | detenéos, noticiándoos, suplicoos, sucediéndonos, vímonos, proporcionóos |
.*[óo]n?osl[eao]s?\b |
presente, gerundio, pretérito indefinido in first person singular or plural, or third person singular, with personal pronouns in first and second person plural in dative or accusative, and in third person singular or plural in dative or accusative | conociéndonosla |
.*[mt]el[eao]s?\b |
infinitivo, imperativo in singular or plural, with personal pronouns in first or second person singular, and in third person singular or plural in dative or accusative | conquistármelo, amarrartela, consagrártelos, créanmelo |
.*[mn]?osl[eao]s?\b |
infinitivo, imperativo, presente, futuro simple, pretérito indefinido, pretérito imperfecto in first or second person plural, with a personal pronoun in third person singular or plural in dative or accusative | bebémosla, hicímoslo, recordábamosle, llamarémosla, enderezémosle, atajárnosla, arrojarnoslos, anunciároslo |
.*[áé]isme\b |
presente, imperativo in second person plural with a personal pronoun in first person singular in dative or accusative | prometéisme, ordenáisme |
.*[áé]isl[eao]s?\b |
presente, futuro simple in second person plural with a personal pronoun in third person singular or plural in dative or accusative | veréisle, habéislo, conocéisla |
.*é(se)?l[eao]s\b |
presente, imperativo, pretérito indefinido in first, second or third person singular, with a reflexive pronoun and with a personal pronoun in third person singular or plural in dative or accusative | firmélos, quitélas, hélos, délas, fuéselos, véseles |
.*í[jz]ol[eao]s?\b |
presente, pretérito indefinido of certain irregular verbs in first or third person singular with a pronoun in third person singular or plural in dative or accusative | hízole, exíjoles, díjola, díjoles, bendíjolas |
.*(á|é)ron[mts]e\b |
pretérito indefinido in third person plural with a reflexive pronoun or a personal pronoun in first or second person singular in dative or accusative | dijéronme, hospedáronme, guardáronse, humedeciéronse |
.*(á|é)ronn?os\b |
pretérito indefinido in third person plural with a personal pronoun in first or second person plural in dative or accusative | hiciéronnos, mejoráronos |
.*(á|é)ronse[mt]e\b |
pretérito indefinido in third person plural with a reflexive pronoun and a personal pronoun in first or second person singular in dative or accusative | antojáronseme |
.*(á|é)ron([mts]e)?l[eao]s?\b |
pretérito indefinido in third person plural with a reflexive pronoun or personal pronouns in first or second person singular and third person singular or plural in dative or accusative | trajéronle, justificáronlos, encendiéronle, erizáronsele, reveláronmele |
.*(ába|ía)n?[mts]e\b |
condicional, pretérito indefinido in third person singular or plural with a reflexive pronoun or a pronoun in first or second person singular in dative or accusative | congratulábame, habríate, reuniríase, citábase, concedíanse |
.*(ába|ía)n?n?os\b |
condicional, pretérito indefinido in third person singular or plural with a personal pronoun in first or second person plural in dative or accusative | llamábannos, hallábaos, habíanos, habríaos |
.*(ába|ía)n?se[mt]e\b |
condicional, pretérito indefinido in third person singular or plural with a reflexive pronoun and a personal pronoun in first or second person singular in dative or accusative | habíaseme, olvidábaseme |
.*(ába|ía)n?([mts]e)?l[eao]s?\b |
condicional, pretérito indefinido in third person singular or plural with a reflexive pronoun or a personal pronoun in first or second person singular and a personal pronoun in third person singular or plural in dative or accusative | impedíamelo, anudábansele anuncíale, acogeríanlo, acogíalos |
311The regular expressions illustrate the complexity of the Spanish verbal and pronominal system. The verb form patterns are determined by the verb class (verbs ending in “-ar”, “-er”, or “-ir”, regular and irregular verbs), tense, person, and number of the verbs, as well as by the person, number, gender, case (dative or accusative), and mode (passive, reflexive, indicative, subjunctive) of the attached pronouns, and finally by spelling variants (e.g., “dárselos” versus “darselos”). The regular expressions displayed here aim to cover most of the usual cases, and they are quite compact in that they cover several types of verb forms at once. It would also be possible to create individual regular expressions for each theoretically possible type of verb form with pronoun suffixes, but this would result in several hundred different expressions because all the verb forms would have to be combined with one or more pronouns in all possible forms.288 Here, a mix of systematic and heuristic approaches was preferred to match many cases occurring in the corpus. Many of the verb forms with pronoun suffixes are historical, e.g., the forms in the past tense (for example, “diómela” or “decorádose”). On the other hand, infinitive, gerund, and imperative forms with attached pronouns (e.g., “conquistármelo”, “pelándoselas”, or “créanmelo”) are still in use in modern Spanish, but they were not recognized by the spell checker, either. Table 14 contains the results of the diminutive, superlative, adverb, and verb form mappings.289
| Pattern type | Number of error types covered | Number of error tokens covered | ||
|---|---|---|---|---|
| verb form endings | 10,591 | 16 % | 39,217 | 7.2 % |
| diminutive endings | 4,582 | 7 % | 34,927 | 6.4 % |
| superlative endings | 1,286 | 2 % | 6,739 | 1.2 % |
| adverbs | 698 | 1 % | 2,134 | 0.4 % |
| Sum: | 17,157 | 26 % | 83,017 | 15.2 % |
312When compared to the false errors matched with the word lists, the results for the word ending patterns show that many more error types are covered this way – more than one-fourth of all the error types – but not necessarily more error tokens. Especially for the verb forms with suffixed pronouns, the generation of patterns is quite laborious and is only worthwhile because it also helps to improve NLP results.
313The third part of the strategy to generate exception lists is manual editing. As could be seen in figure 16 above, some forms of address are among the most top frequent errors. These can best be covered with a simple list created as needed when looking at the top errors in the spell-check results. Other types of words for which it is not easily possible to obtain ready lists or generate them on the basis of patterns are, for example, foreign words, specialized vocabulary, or forms of oral speech. Manual editing is also a good strategy to adapt lists obtained elsewhere to the needs of the corpus, such as the lists of proper and place names. When creating exception lists, it is advisable to proceed with caution and also look into the texts in some cases because there are words that can both be an exception word or a real error (e.g., the entry “nina”, which in the corpus referred to the proper name “Nina” but also was a misspelled version of “niña”). Moreover, words can belong to several kinds of exception words at once. This is often the case for surnames and place names (e.g., “villaclara” or “villanueve”). Table 15 summarizes how many false errors could be detected with the help of manually created and manually enhanced lists.290
| Type of list | Number of error types covered | Number of error tokens covered | ||
|---|---|---|---|---|
| proper names (enhanced) | 574 | 0.86 % | 178,610 | 32.9 % |
| surnames (enhanced) | 378 | 0.57 % | 60,418 | 11.1 % |
| other (containing e.g. individual forms of address) | 26 | 0.04 % | 34,275 | 6.3 % |
| places291 | 108 | 0.16 % | 13,885 | 2.6 % |
| countries (enhanced) | 62 | 0.09 % | 9,993 | 1.8 % |
| foreign words | 47 | 0.07 % | 4,334 | 0.8 % |
| specialized vocabulary | 34 | 0.05 % | 2,911 | 0.5 % |
| oral speech | 9 | 0.01 % | 1,666 | 0.3 % |
| archaic vocabulary | 105 | 0.16 % | 561 | 0.1 % |
| Sum: | 1,343 | 2.01 % | 306,653 | 56.4 % |
314As can be seen, manual lists can be very effective if they cover
high-frequency errors, as is the case of the “other” list, and if frequent
corpus-specific exception words are added to external lists, for example,
special proper names such as “Moctezuma” or “Chacho”. Although the exception
lists in themselves do not help to improve the quality of the texts, they allow
us to evaluate the amount of real errors in a better way. However, the process
of creating and refining exception lists, as well as correcting remaining
errors, can be carried forward infinitely – or rather, until everything is
cleaned up – but there is a point when this is not effective anymore. For the
corpus, all the errors that occurred more than 50 times in the whole collection
were checked, and the words were either added to exception lists or corrected.
All the remaining entries in the spell check result list were left as they are.
So the texts are not entirely free of errors but corrected as far as possible.
Having a look at the remaining errors, at the top of the list, there are still
predominantly exception words, while there are more real errors with decreasing
frequency. Figures 17 to 23 summarize the effect of all the
exception word lists and show how many and what kind of errors remain after
their application and after further correcting errors that were frequent in the
whole collection.292
315Looking at the results for all the exception lists together displayed in figure 17, it becomes clear that proper names are by far the most frequent false error tokens, but that also certain morphological constructions, in particular the verb forms with pronoun suffixes and diminutives, play an important role. On the other hand, some types of words that one could have expected to be more significant are stylistically marked words such as foreign words, specialized or archaic vocabulary, and words representing oral speech. As the figure shows, at least among the most frequent errors, they are not decisive. In sum, the exception lists cover 344,339 tokens (63 % of all the error tokens) and 18,197 types (27 % of all the error types), so they helped to clean the spell check results considerably.
316The number of errors that remain is 121,442 tokens, which is
0.7 % of all the tokens in the corpus, and 43,955 types, which is 22 % of the
whole corpus vocabulary. Of these, 29,266 (15 % of the vocabulary and 0.2 % of
the tokens) occur only once, and 2,212 types and 47,670 tokens occur more than
ten times (i.e., 1 % of the vocabulary and 0.3 % of the tokens). Figure 18 shows the distribution of
the remaining errors.
317Compared to the previous error distribution, the curve is not so
steep anymore, but still, relatively few errors are frequent. To clean up the
remaining individual errors would be far too time-consuming, but also the other
residual errors comprise several thousand entries. A final aspect worth
considering is how many misspelled words there are per novel in the corpus.
This is summarized in figure 19.
318Both for error tokens and types, the mean (474 and 181) is higher
than the median (351 and 204, respectively), meaning that there are several
outliers with many errors. Indeed, the ranges go from 19 to 2,437 error tokens
and from 18 to 1,664 error types. As the novels are of different lengths, and
it is probable that this influences the number of errors, the same distribution
is shown again in relative numbers in figure 20.
319Now the mean error rate for tokens is at 0.7 % and for types at
2.4 %, and the medians are at 0.6 % and 2.2 %, respectively. That the number
for types is higher follows from the above observation that most of the
remaining errors are individual ones. The figure shows that the spread is much
smaller for tokens than for types, meaning that the correction of the most
frequent errors contained in the texts that were included in the corpus from
various sources helped to level the token error rate. Nevertheless, because
individual errors were not corrected systematically, the range of the error
type rate is more extensive, going from 0.4 % to 12.5 %. A way to look for
factors that might have influenced the text quality is to combine the
information about errors with the metadata about the sources of the texts. In
figures 21 to 23, the
distributions of error tokens and types are charted distinguished by the type
of edition used (first, historical, modern, or unknown), by the source file
type (image versus text), and by the different source institutions.293
320A look at the type of source editions also confirms that the
token error rates could be reduced to a similar level by the text treatment
procedure, independently of the type of edition used. In contrast, the type
error rates differ slightly. Their median is highest for texts where the kind
of source edition is unknown (2.5 %) and lowest for modern editions (2.0 %),
while first and historical source editions lie in between. There is a notable
outlier of a modern edition with 12.5 % of error types. This is the science
fiction novel “En busca del eslabón. Historia de monos” (1888, CU) by Francisco
Calcagno. It contains 1,664 different errors, but most of them are exception
words: proper names, foreign words, scientific and other special, also invented
vocabulary that was not covered by the exception lists created above, e.g.,
“Blumenbach”, “Goethe”, “link”, “chimp”, “gibones”, “hisquiáticas”,
“niamsniams”, “Ibizapitanga”, or “Sinonimolandia”.294 This example shows to what extent checks of
the text quality can be obstructed by special vocabulary.
321In figure 22, the
error rate distributions are distinguished by the source file type. Here the
median of the type rates is a bit higher for texts that were extracted from
image files (2.3 %) than those that were collected from text files (2.0 %),
showing on the one hand that the OCR process entails that a certain amount of
spelling errors is introduced into the texts, but also that existing full-text
files are usually not free from errors.
322Finally, the distribution of error rates is differentiated by the source institutions in figure 23. Again, as a result of the text treatment process, the medians of the token error rates are quite similar throughout the different institutions. Regarding the type error rates, there is a bit more variation from institution to institution. Sources with very good rates are, for example, the “Biblioteca Digital Argentina” (BDA) and the digital library “La novela corta” with a median of 1.5 % each. There are higher rates, for example, for the iBooks Store (4.4 %) and Conaculta (4.1 %). Interestingly, the files from the BDA and the iBooks Store were processed as text, while the ones from “La novela corta” and Conaculta went through the OCR process.
323Summing up, the process of text treatment that was necessary for the creation of the corpus at hand involved different steps ranging from rather simple structural conversions of marked-up files to a whole pipeline of digitization in other cases, because many different sources had to be used in order to gather a corpus of Argentine, Cuban, and Mexican novels of considerable size. When so many different types of sources are used, it is especially important to check the quality of the incoming texts to make sure that errors in the texts do not skew the results of later analyses too much. For this corpus, a spell check was performed using a standard dictionary for modern Spanish, and the results were refined through the creation of corpus-specific exception lists. That way, a certain quality of the texts could be assured and achieved. Furthermore, the spell check revealed some peculiarities of the corpus vocabulary, such as the existence of many verb forms with pronoun suffixes. Knowledge about them is helpful when the texts are further processed. However, the analysis of the “false” and real spelling errors also revealed that it is hardly possible to create a corpus of perfect text quality, at least when the range of source edition types, file types, and institutions is broad. It also became clear that spelling exceptions and errors are influenced by a lot of factors: the mentioned kinds of sources, but also the kinds of novels.
324Starting from the basic structured full texts that were prepared according to the processing steps described in the previous section, each novel in the corpus was enriched with metadata and further structural markup. In CLiGS, we decided to use a common data model for all the text collections produced in the context of the project based on the text encoding standard of the TEI in version P5. It is not so common for large-scale text analysis projects to use XML-based markup, though. In most cases, large corpora consisting of simple plain text files are used together with metadata indicated directly in the file names or stored in tabular format.295 The decision for the TEI standard was made here because the analysis of genres and subgenres rests on detailed metadata about the texts that cannot easily be represented in simple tables. As is the case for the digital bibliography presented above, also the metadata for the full-text corpus of novels (the corpus at hand, but also the other corpora of narrated and dramatic texts produced in the CLiGS project) is best recorded in a model that allows indicating responsibilities (who entered the information?) and degrees of certainty (how sure was the person who entered the information that it is correct?). Furthermore, it is important that the metadata can be structured further (e.g., through the addition of markup in bibliographic information or the indication of levels of metadata). The main text also profits from the possibilities of markup. It would also be possible to infer paragraph or chapter boundaries from plain text files (for example, via the use of blank lines), but a structure of hierarchical markup allows to differentiate between main parts, chapters, subchapters, headings, and paragraphs, and inserted texts, such as letters, verse lines, or dramatic speech. All this kind of structural information can then be used in the analyses of the texts. Moreover, because the TEI is an encoding standard widely used in the digital humanities, the reuse of the files produced in the CLiGS project in other contexts is facilitated, so the usage of this standard can be considered a sustainable solution.296 In this chapter, the TEI-based data model developed for the corpus is presented, starting with the elements and attributes used to encode the metadata collected for the novels (in chapter 3.3.3.1) and going on with how the structures of the textual body were encoded (in chapter 3.3.3.2). XML snippets, mainly from one novel, are included as examples. Where aspects of the text encoding need to be clarified further for the whole corpus, they are discussed in connection with the individual examples, e.g., the declaration of rights for the TEI files.
325In the corpus, each text was stored as an individual TEI file. The file names consist of a shortcut for the corpus, in this case, “nh” (“novelas hispanoamericanas”) plus four digits for a serial number, so the first file in the corpus has the file name “nh0001.xml” and the last one “nh0256.xml”.297 Because the file names are unique, they are, at the same time, the identifiers of the novels in the corpus (the so-called “CLiGS identifiers”). That way, they can be referenced elsewhere, for example, in the digital bibliography, and they can also used to identify the texts in analyses.
326In general, in TEI, the metadata is encoded in the TEI header, which contains descriptive and declarative metadata associated with the digital resource. Of the five principal components that are available for the TEI header, four were used in the TEI model here:
327The file description is primarily used for the encoding of
bibliographic information about the digital file itself, but also about
its sources. Example
7 shows the first part of this section of the TEI header, the title
statement.
<titleStmt>
<title type="main">Adoración</title>
<title type="short">Adoracion</title>
<title type="sub">Novela original</title>
<title type="idno">
<idno type="viaf">-</idno>
<idno type="bibacme">W923</idno>
</title>
<author>
<name type="full">Iglesia, Álvaro de la</name>
<name type="short">IglesiaA</name>
<idno type="viaf">120788045</idno>
<idno type="bibacme">A367</idno>
</author>
<principal xml:id="uhk">Ulrike Henny-Krahmer</principal>
</titleStmt>
328It contains the different parts of the work’s title. In the
example, there are a main title (“Adoración”) and a subtitle (“Novela
original”). In addition, a short title without blank spaces and accents
is given that can be used as a shortcut, for example, in the
visualization of results (“Adoracion”). The shortcut is especially useful
if the title of the novel is longer than the one in this example. Other
possible elements of the title, which are not present in this example,
are the title of a series the novel belongs to (<title
type="series">), an alternative title (<title
type="alt">), and title parts (<title
type="part">).299 Where a novel is registered
as a work in the “Virtual International Authority File” (VIAF), this
number is given in a title element of the type “idno” (<idno type="viaf">). In the present example, no such identifier
is available. Another identifier is added to connect the corpus with the
digital bibliography: for each novel, its work ID in Bib-ACMé is encoded
(<idno type="bibacme">). That way, additional
information can be retrieved both ways, from the bibliography to the
corpus and vice versa. The second part of the title statement consists of
information about the author. Like the work’s title, also the author’s
name is given in a full version (<name
type="full">) and a short version (<name
type="short">). For some authors, also pseudonyms are given (<name type="pseudonym">) if they published novels
under that name. If available, the authors are identified with a VIAF
number, as well (<idno type="viaf">), and also
their ID in Bib-ACMé is indicated (<idno
type="bibacme">).300 Finally, the
responsibilities of the people involved in the creation of the TEI file
of a novel are indicated as part of the title statement. In the case at
hand, the file was created and edited just by one principal investigator.
In other cases, further responsibility statements are included.
<extent>
<measure unit="words">44670</measure>
</extent>
<publicationStmt>
<publisher>
<ref target="http://cligs.hypotheses.org/">CLiGS</ref>
</publisher>
<availability status="free">
<p>This work is in the public domain. It is provided here with the
<ref target="https://creativecommons.org/publicdomain/mark/1.0/deed.de">Public
Domain Mark Declaration</ref> and can be re-used without restrictions.
The XML-TEI markup is also considered to be free of any copyright and
is provided with the same declaration.</p>
</availability>
<date>2020</date>
<idno type="cligs">nh0018</idno>
<idno type="url">https://github.com/cligs/conha19/blob/master/tei/nh0018.xml</idno>
</publicationStmt>
329After the title statement, the file description continues
with a part on the extent of the novel. It contains an element
documenting the number of words in the novel (<measure
unit="words">, see example 8 above). Words are understood as tokens here, and
their number is counted with a simple regular expression in Python
applied to the main body of the novel’s text, excluding headings and
notes (tokens = re.split(r"\W+", text,
flags=re.MULTILINE)). Many other measures could be included in
the TEI header, for example, the number of chapters, paragraphs,
sentences, characters, and so on. However, because all of these measures
can be determined programmatically and are not adjusted manually here, it
was decided only to note the number of words because this measure is
basic to characterize the files in the corpus and is used very often.
Other measures can be calculated ad hoc when needed. Next, information
concerning the publication of the TEI file is given. This includes the
indication of the publisher, in this case, the project CLiGS.
Furthermore, details about the availability of the text are encoded. The
question of access to the TEI files needs some more discussion and is
explained further below. Additional parts of the publication statement
are the year in which the TEI file was first published (<date>), the CLiGS identifier (<idno
type="cligs">), which is also used for the file names, and a URL
pointing to the repository where the file is published (<idno type="url">).301
330Regarding the availability of the TEI files, their status
can be either “free” or “restricted”. The TEI files of all the free texts
are published with the Public Domain Mark Declaration, allowing the reuse
of the files without restrictions (see Creative Commons n.d.Creative Commons. n.d. “Public Domain Mark 1.0.”
https://web.archive.org/web/20230610120916/https://creativecommons.org/publicdomain/mark/1.0/deed.en.). Almost all
the texts of the corpus are in the open domain according to German
copyright laws. In Germany, a work becomes free from copyright 70 years
after the author’s death (Bundesamt für Justiz n.d.aBundesamt für Justiz. n.d.a “Gesetz über
Urheberrecht und verwandte Schutzrechte (Urheberrechtsgesetz). § 64 Allgemeines.”
Gesetze im Internet. https://web.archive.org/web/20230423112139/https://www.gesetze-im-internet.de/urhg/__64.html.). An
overview of the authors’ death years is given in figure 24.302
331If one takes the year of 2022 as a reference point, there
is only one author of novels in the corpus who died after 1953: the
Argentine writer Enrique Larreta (1875–1960). There is one novel written
by Larreta in the corpus, so the TEI file of this novel can only be
published in 2030.303 In addition, there are 13
authors whose years of death are unknown. In such cases, the German rule
is that the copyright expires 70 after the first publication of the
work.304 Because all the works in the corpus
were first published at the latest in 1910, the novels of these authors
are all in the open domain.305 In figure
25, the years of the novels’ first editions are displayed.
332Part of the German copyright law is also the ancillary
copyright protecting, for example, scholarly editions of works that are,
in principle, free. This protection ends 25 years after the publication
of the edition (Bundesamt für Justiz n.d.cBundesamt für Justiz. n.d.c “Gesetz über
Urheberrecht und verwandte Schutzrechte (Urheberrechtsgesetz). § 70
Wissenschaftliche Ausgaben.” Gesetze im Internet.https://web.archive.org/web/20230423113034/https://www.gesetze-im-internet.de/urhg/__70.html.). This law is relevant for the
corpus because also modern editions were used to extract the texts of the
novels. Figure 26 shows the
publication years of the editions that were used as a basis for the TEI
files in the corpus. These publication years refer to print editions when
these were used directly, to print editions underlying a digital
reproduction, or to digital editions that form a new textual basis and
are not considered simple reproductions.306
333Among the novels, there are twelve novels whose text was
extracted from print editions that were published after 1997 and for
which access is also restricted here, as indicated in example 9.307
<availability status="restricted">
<p>This file is prepared for personal research use only and not for publication
because the ancillary copyright of the underlying print edition has not yet
expired according to German law.</p>
</availability>
334Other cases that need to be clarified are novels where digital editions are available, but the underlying print editions are unknown. As long as the works themselves are in the open domain and no special rights are declared for the digital editions, it is assumed here that these editions are not considered new scholarly revisions of older editions but reproductions of existing historical editions. In consequence, the publication of the corresponding TEI files should be unproblematic.308 Next, there are some cases of digital editions for which copyright is claimed because they constitute new scholarly preparations of old texts that are themselves out of copyright. All of these novels were retrieved from the portal “La novela corta: una biblioteca virtual” (Universidad Nacional Autónoma de México 2008–2023Universidad Nacional Autónoma de México. 2008–2023. “La Novela Corta. Una biblioteca virtual.” https://web.archive.org/web/20230328173719/https://www.lanovelacorta.com/.).309 In one case, the underlying print edition is unknown, and in five cases, it is known but is itself not affected by the ancillary copyright. Nevertheless, because these digital editions can be considered scholarly editions and copyright is claimed for them, they are interpreted as falling under the ancillary copyright and are therefore classified as “restricted” here. Finally, there are two more cases that are not very clear. Two novels were downloaded from the “Biblioteca Digital del Instituto Latinoamericano de la Comunicación Educativa” (ILCE), “La Rumba” (1891, MX) by Ángel de Campo y Valle and “El diablo en México” (1858, MX) by Juan Díaz Covarrubias. Both novels can be downloaded as PDF files. In the first case, the edition only contains the base text but no introduction, notes, or other scholarly commentary, and it is not indicated on what print edition the digital one is based. However, an organizational editor and a publication year are indicated and the following claim is made: “Las particularidades de esta edición están protegidas por derechos de autor” (Campo y Valle 2009Campo y Valle, Ángel de. 2009. La Rumba. Colección Autores del Siglo XIX. México: Instituto Latinoamericano de la Comunicación Educativa. http://web.archive.org/web/20160615221017/http://bibliotecadigital.ilce.edu.mx/Colecciones/ObrasClasicas/_docs/Rumba.pdf.). In the second case, the underlying print edition is also unknown. In addition, the publication date of the digital edition is not given, no indication of an individual person responsible for the creation of the edition is made, there is no introduction, and there are no notes. However, at the end of the PDF file, the following advice is given: “Material autorizado sólo para consulta con fines educativos invariablemente como fuente de la información la expresión ‘Edición, culturales y no lucrativos, con obligación de citar digital. Derechos Reservados. Biblioteca Digital © Instituto Latinoamericano de la Comunicación Educativa ILCE’” (Díaz Covarrubias n.d.Díaz Covarrubias, Juan. n.d. El diablo en México. Obras clásicas de siempre. Biblioteca Digital del ILCE. https://web.archive.org/web/20230423115244/http://bibliotecadigital.ilce.edu.mx/Colecciones/ObrasClasicas/_docs/El_diablo_en_Mexico-Juan_Diaz_Covarrubias.pdf.). Although copyrights are declared, these two editions are not considered as falling under the ancillary copyright because no added scholarly value is visible. They are therefore classified as “free” here.
335So, in total, there is one novel that is still protected by
the general copyright and 18 by the ancillary copyright. As a
consequence, there are, in total, 19 of the 256 TEI files of the corpus
that cannot be published immediately.310 This information is illustrated in figure 27.
336The discussion of copyrights shows that preparing a digital full text and TEI corpus of novels poses some challenges in this regard. Whereas the determination of the general copyright is relatively clear because it depends on the authors’ death dates and the dates of the first publication of the works, the German ancillary copyright is often more difficult to assess. First, existing source editions can be of very different kinds: print sources, images, PDF files, plain texts, or web pages. The relationship between originals, reproductions, and edited versions is not always clear because it is not always explained, and in some cases relevant information is missing. Moreover, the legal status of source editions can be difficult to determine when no publication dates or responsibilities for their creation are given. On the other hand, some claims for copyright on material in the open domain are exaggerated. Another problem is that web resources are not necessarily stable, not even if they are published by a scholarly institute. They may cease to be accessible after some years so that information that is relevant to the editions’ legal status cannot be retrieved anymore. In other cases, updates of contents that were produced earlier postpone the publication date and thereby also the end of the ancillary copyright.
337Apart from the title statement, information about the
extent of the novel, and the publication statement, the file description
in the TEI header also contains the source description, in which details
about the sources that the digital text was derived from are encoded in
the form of bibliographic references (see example 10).
<sourceDesc xml:base="https://raw.githubusercontent.com/cligs/bibacme/master/app/data/editions.xml">
<bibl type="digital-source" xml:id="DS"> Iglesia, Álvaro de la. "Adoración.
Novela original." <seg rend="italic">HathiTrust Digital Library</seg>,
<ref target="https://catalog.hathitrust.org/Record/009049820">https://catalog.hathitrust.org/Record/009049820</ref>.
Accessed 31 April 2018.
</bibl>
<bibl type="print-source" n="222" xml:id="PS" corresp="#E1786">
Iglesia, Álvaro de la. <seg rend="italic">Adoración. Novela original.</seg>
Barcelona: Ed. F. Granada, <date when="1906">1906</date>. 222 p.
</bibl>
<bibl type="edition-first" xml:id="E1" corresp="#E1280">
Iglesia, Álvaro de la. <seg rend="italic">Adoración. Novela original.</seg>
Matanzas: Imprenta de la Propaganda, <date when="1894">1894</date>.
</bibl>
</sourceDesc>
338Three main types of bibliographic references are included
in the source description: the first one documents which digital source
was used, the second reference describes the print source underlying the
digital source edition, and the third one documents the first known
edition of the novel. The date of the first edition is the one generally
referred to when the novels are mentioned in this dissertation and also
when they are analyzed. In the case of the novel “Adoración”, digital
images were retrieved from the “Hathi Trust Digital Library” and were
used to extract the full text. Here, the underlying print edition is a
historical one from 1906, but not the first one, which was published in
1894. In other cases, the used print edition may correspond to the first
known edition so that the entries “PS” and “E1” reference the same
edition. For some novels in the corpus, there is no digital source (when
print editions were used directly), and for others, the print source of
the digital source edition is unknown, so there may also be just two
levels of sources. On the other hand, more than three sources may be
listed in cases where different front matters of historical editions were
transcribed to extract genre labels occurring on them. In these cases,
further bibliographic entries of the type “edition” are added. The
attribute @corresp is used on the bibliographic
entries to indicate to which edition they correspond in the bibliography
Bib-ACMé, in which more structured bibliographic descriptions of the
editions can be found. The identifiers pointed to in this attribute can
be resolved using the base URI indicated in @xml:base on the element <sourceDesc>.
339After the file description, the TEI header continues with
the encoding description. A short general description of the text
treatment and text encoding is given in each file of the corpus, as example 11 shows.
<encodingDesc>
<p>The source PDF file was processed with OCR. The software used
was ABBYY Finereader 12 Professional, with Spanish as
recognition language. The result of the OCR process was
checked, but due to temporal restrictions, corrections were
only made in a rough manner and remaining errors cannot be
excluded.</p>
<p>The spelling was checked and corrected where appropriate.</p>
<p>The following phenomena were marked up: front matter (where
available, e.g. title page, dedication, preface,
introduction), part and chapter divisions, headings,
paragraphs, inserted texts (e.g. letters or newspaper
articles), direct speech or thought, verse lines, dramatic
text, quotations (e.g. epigraphs), notes by the author, and
gaps.</p>
</encodingDesc>
340The phenomena that were marked up in the texts are explained further below. The encoding description is followed by the profile description, where non-bibliographic metadata about the texts is documented. For the corpus at hand, two sections of the profile description are used: abstracts and text classification.
341If available, abstracts summarizing the content of the
novels or containing comments on the novels made by literary historians
are given. For the novel “Adoración”, a description of the plot coming
from the preface of the novel itself is quoted. A section of the abstract
is reproduced here in example
12.
<abstract source="#Iglesia_1906">
<p>
<quote><p>Es el caso de un joven, casi adolescente, que está
enamorado a la vez de dos jovencitas. El mismo narra el
desarrollo de ese complejo estado de conciencia, a que
asiste en cierto modo, a veces aturdido, a veces
espantado, sin acertar a explicárselo [...]</p></quote>
<bibl>Varona, Enrique José. "Prólogo." In: Iglesia, Álvaro de
la. <seg rend="italic">Adoración. Novela original.</seg>
Barcelona: Ed. F. Granada, <date when="1906">1906</date>.</bibl>
</p>
</abstract>
342The source of the abstract is encoded as a bibliographic
citation (<bibl>), and, in addition, it is indicated
in the attribute @source with a pointer to an
external list of bibliographic references.311 The abstract itself is encoded as a
quotation (<quote>) that is structured further with
paragraph elements if needed. Each TEI file can contain none, one, or
several abstracts. The abstracts are helpful in getting an overview of
the content of the novels when the results of the genre analyses are
interpreted.
343Besides the abstract, the profile description also contains
the element <textClass> (“text classification”). In
general, this element is used to “group[...] information which describes
the nature or topic of a text in terms of a standard classification
scheme, thesaurus, etc.” (Text
Encoding Initiative Consortium 2023jText Encoding Initiative Consortium. 2023j.
“<textClass>.” In: TEI P5: Guidelines for Electronic Text Encoding and
Interchange, 1782–1783. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.). Inside <textClass>, the <keywords> element is used to
group a list of keywords describing the nature of the text from various
perspectives, for example, the genre or the setting of the novel. To
illustrate the usage of this taxonomic system for the corpus, the list of
keywords for the novel “Adoración” is represented in example 13.
<textClass>
<keywords scheme="../schema/keywords.xml">
<term type="author.continent">America</term>
<term type="author.country">Cuba</term>
<term type="author.country.birth">Spain</term>
<term type="author.country.death">Cuba</term>
<term type="author.country.nationality">Cuba</term>
<term type="author.gender">male</term>
<term type="text.source.medium">digital</term>
<term type="text.source.filetype">image</term>
<term type="text.source.institution">HathiTrust Digital Library</term>
<term type="text.source.edition">historical</term>
<term type="text.publication.first.country">Cuba</term>
<term type="text.publication.first.medium" cert="medium">book</term>
<term type="text.publication.first.type" cert="medium">independent</term>
<term type="text.publication.type.independent" cert="medium">yes</term>
<term type="text.language">Spanish</term>
<term type="text.form">prose</term>
<term type="text.genre.supergenre">narrative</term>
<term type="text.genre">novel</term>
<term type="text.title" n="1894">Adoración. Novela original</term>
<term type="text.title" n="1901">Adoración. Novela original</term>
<term type="text.title" n="1906">Adoración. Novela original</term>
<term type="text.genre.subgenre.title.explicit">novela original</term>
<term type="text.genre.subgenre.title.implicit"
resp="#uhk">novela sentimental</term> [...]
<term type="text.narration.narrator">autodiegetic</term>
<term type="text.narration.narrator.person">first person</term>
<term type="text.speech.sign">—</term>
<term type="text.speech.sign.type">single</term>
<term type="text.setting.continent">America</term>
<term type="text.setting.country">Cuba</term>
<term type="text.time.period">unknown</term>
<term type="text.time.period.author">contemporary</term>
<term type="text.time.period.publication">contemporary</term>
<term type="text.prestige">low</term>
</keywords>
</textClass>
344The types of keywords are encoded in <term> elements that are specified further by the attribute @type. The keyword values are given as the content
of the <term> elements (e.g., <term type="text.genre">novel</term>). The whole system of keywords is regulated
by an external taxonomy referenced from the <keywords> element (<keywords
scheme="../schema/keywords.xml">). The taxonomy, explained
further below, defines which types of keywords exist and which values
they can take. In general, the keyword types are organized hierarchically
with the goal of systematizing the different kinds of metadata. In the
values of the terms’ @type attribute, the
different levels of the hierarchy are separated by a dot, so the type
"text.genre", for example, refers to the keyword level
“text” and to the sublevel “genre”. For some keyword types, the list of
possible values is closed, meaning that only certain specific values are
allowed, and for others, it is open, depending on the kind of
information. For instance, there is a keyword type referring to the
narrative perspective of the text (<term
type="text.narration.narrator">). Only three keyword values are
possible for this type: “autodiegetic”, “homodiegetic”, and
“heterodiegetic”. On the other hand, the values of the keywords
concerning explicit mentions of the subgenre of the text (e.g., <term type="text.genre.subgenre.title.explicit">) are
not previously defined.
345In the above example, all the types of keywords used for the corpus are included, except the terms used to record the subgenre of the novels, because these are described in more detail in the next chapter 3.3.4, in which the assignment of subgenre labels to the corpus is explained. As can be seen, there are two general groups of keywords: on the one hand, keywords about the author of the text and, on the other hand, keywords about the text itself. Information about the author is already present in the title statement (her or his name and the VIAF and Bib-ACMé identifiers) as well as in the digital bibliography. Furthermore, an author can be the creator of several novels in the corpus, so that the information is eventually repeated in the metadata of several texts. Nevertheless, some authorial metadata is encoded in the keyword system because it is especially relevant for the analysis of the novels. That way, it is not necessary to retrieve this information from external files every time that the novels are analyzed. Furthermore, even though all the TEI files of the corpus are embedded in a corpus ecosystem, including the digital bibliography, a keyword taxonomy, and schema files, it should be possible to reuse a subset or individual files of the corpus without the necessity to rebuild the whole system. Therefore, some metadata that is considered essential for the stylistic analysis of the novels is repeated to make the TEI files more self-contained.
346The authorial keywords concern the gender (<term type="author.gender">) as well as the
geographic, cultural, and national belonging of the author
("author.continent", "author.country",
"author.country.birth", "author.country.death",
"author.country.nationality"). The values for the continent
and country correspond to the general assignment of an author to one of
the three countries covered with the corpus (Argentina, Cuba, and
Mexico).312 With the additional
terms, the assignment to a country is differentiated further because
authors can have a different country of birth, death, or nationality than
the one to which they are generally assigned. The author of the novel
“Adoración”, Álvaro de la Iglesia, for example, is considered a Cuban
author because he moved to Cuba as a young adult and was active and
naturalized there, but he was born in Spain.
347The first group of keywords related to the text itself is
about its sources: the medium of the source (<term
type="text.source.medium">), its filetype
("text.source.filetype"), the institution it was retrieved
from ("text.source.institution"), and the kind of edition of
the source ("text.source.edition"). The medium can be either
“digital” or “print”, the filetype “image” or “text”, the type of edition
“first”, “historical”, or “modern”, and the keyword about the source
institution can take any value from an open list of institutions.313 This kind of metadata is important to document
from what sources the corpus was constructed.314
348Next, keywords about the publication of the novel are
included: in which country was it published first (<term
type="text.publication.first.country">), in which medium
("text.publication.first.medium"), in what type of
publication ("text.publication.first.type"), and has it been
published independently
("text.publication.first.independent")? The term concerned
with the medium can take the values “book”, “journal”, “magazine”, or
“unknown”, and the type of publication can be either “independent” (e.g.,
in book form), “dependent” (e.g., in a journal, magazine, or as part of a
book), “collection” (dependent, but together with other items of the same
kind, e.g., an anthology or the œuvre of an author), or “unknown”. In
many cases, the information about the medium and type of publication of
the novel cannot be given with high certainty because it depends on the
knowledge of all the (historical) editions of the work. Here, the
attribute @cert serves to indicate the degree of
certainty about these metadata values. Information about how the novel
was published historically is of interest from various perspectives: it
is related to the question of the generic identity of the work315 and also its canonicity.316
The historical conditions of the production and reception of novels can
also be investigated by analyzing how they were (first) published.
349Some general keywords about the text follow: in what
language it is written (<term
type="text.language">), in what form it is composed
("text.form"), and to which major genres it belongs
("text.genre.supergenre" and "text.genre"). The
values of these keywords are the same for all the works in the corpus:
they are all written in Spanish, composed in prose, and they are all
narrative texts as well as novels. So these keywords are not used to
distinguish the texts inside of the corpus from each other but to give
some general information about them, which can be useful when this corpus
is reused in other contexts, for example, in a multilingual setup or in a
study contrasting different major genres.
350The next terms in the example contain the title of the
novel as it appears in different editions, including series titles and
subtitles. In the attribute @n, the year of the
edition is indicated (e.g., <term type="text.title"
n="1894">). This information is more fully documented in the
digital bibliography but is repeated in a compact form in the individual
corpus files because the titles of the novels’ editions are analyzed when
their subgenres are determined. That way, all the information necessary
to reproduce the subgenre assignment is available directly in the
respective TEI file. In the example, there are three editions from 1894,
1901, and 1906, but the title and subtitle of the novel do not change
from one edition to the other. The keywords following the text’s titles
all relate to the subgenre of the novel. The first type of term
concerning the subgenre serves to record explicit subgenre labels that
occur in the title of the novel (<term
type="text.genre.subgenre.title.explicit">). The novel
“Adoración” has the explicit label “novela original”. The second subgenre
term indicates a subgenre that is signaled implicitly in the title (<term type="text.genre.subgenre.title.implicit">). In
this case, this is a “novela sentimental” because the main title
“Adoración” means “admiration”. Because the inference of implicit signals
is an interpretive process, this <term> element
carries a @resp attribute documenting who entered
the value. Here, only two of these terms are illustrated because the
assignment of subgenres is discussed more fully in the next chapter 3.3.4.
351Next, there are three groups of keywords related to the
content of the novel: the narrative perspective of the text, the kind of
speech sign used in it, its setting, and the time period covered by the
plot of the novel. The narrative perspective is given in two variants:
first, as the kind of narrator (<term
type="text.narration.narrator">), which can be “autodiegetic”,
“homodiegetic”, or “heterodiegetic” and second, indicating the person in
which the text is narrated (<term
type="text.narration.narrator.person">), with the possible values
“first person” and “third person”. The narrative perspective is an
important metadata item in the context of a stylistic analysis because it
significantly influences the language of the text. For example, a novel
that is written in the first person contains many more verbs in the first
person than a novel narrated in the third person, where the first-person
verbs only occur in direct speech or thoughts. Of course, the narrative
perspective can change throughout the novel. The perspective encoded here
is the one dominating the text because, from a statistical point of view,
this affects the linguistic material of the text the most. Minor shifts
are neglected. Literary-historical characterizations of the texts were
consulted to determine the narrative perspective. The openings of the
novels were read, and other parts of the novels were checked
randomly.
352After the keywords describing the narrative perspective,
two terms defining the type of speech sign used in the novel follow (<term type="text.speech.sign"> and <term type="text.speech.sign.type">). The first of these terms
has the purpose to indicate which typographical sign is predominantly
employed to mark direct speech, and the second term classifies the speech
sign as “single” or “double”. A speech sign of the type “single”
functions as a marker for the beginning and eventually also for the end
of a speech. It is a single sign indicating a change in the narrative
mode. A speech sign of the type “double”, in contrast, serves to enclose
passages of direct speech and usually consists of two different signs, an
opening and a closing one (e.g., the double angle brackets « and »). The
metadata about speech signs is collected to enable a rule-based automatic
detection of direct speech using this typographic information (see chapter 3.3.3.2.8 below).
In the novel “Adoración”, the main speech sign is a long hyphen (—),
which is a speech sign of the type “single”.
353The setting of the novel is described in two keywords
stating the continent (<term
type="text.setting.continent">) and the country (<term type="text.setting.country">) in which the plot
takes place. Here, too, only one principal value is given, although the
setting can involve several continents or countries, for example, in
travel novels. The main setting is understood to be the primary place of
action and, if there are several ones and no predominant place can be
determined, the place where the action starts and the characters come
from. The setting was taken up in the metadata because it is related to
the question of how American or national the
Argentine, Cuban, and Mexican novels were in terms of content. The same
strategy as for the narrative perspective was followed to find out the
setting of the novels.
354The third group of content-related keywords covers the time
period in which the action of the novel takes place. The first keyword of
this kind serves to hold a concrete time span, if available (<term type="text.time.period">). A regular expression
was used to locate years explicitly mentioned in the text (“\d{4}”) to find out the time period. The found
years were checked to see if they were only mentioned or if they referred
to the action and which span of years they covered. Furthermore,
summaries of the novels and first chapters were consulted to find
information about the time period of the plot. In the novel “Adoración”,
there is no explicit temporal localization, so the corresponding term
takes the value “unknown”. In other cases, the values are statements such
as “1827”, “1539–1541”, or “~1700”.317 Even when dates are
mentioned, the time period cannot always be determined exactly. The novel
“María Luisa” (1896, MX) by Andrés Portillo, for example, begins with the
following statements:
Era joven aún este siglo XIX que hoy contemplamos anciano y moribundo, tan lleno de glorias y cargado de responsabilidades.
México había derramado su oro y su sangre por espacio de once años para librarse de la dominación española y lanzábase a la vida independiente con la vaguedad del hombre que acaba de tener un sueño penoso.
Se ensayaban todas las formas de gobierno, se convocaban congresos nacionales, se defendían principios y contraprincipios y había de una parte, quienes suspiraban por el régimen colonial, y de otra, quienes aplaudían las doctrinas más atrevidas de la revolución francesa.
(Portillo [1896] 2020Portillo, Andrés. (1896) 2020. María Luisa. Leyenda histórica. Würzburg: CLiGS. Accessed January 28, 2023. https://github.com/cligs/conha19/blob/master/tei/nh0100.xml.)
355The action is located temporarily somewhere in the early
nineteenth century. It is said that Mexico is already independent, so it
must be after 1821, and that several forms of government have been tried
out, so some years must have passed since the declaration of
independence. This is encoded as <term
type="text.time.period" n="1830">. The main purpose of this
metadata is to find out if the novels are set in the present, in a recent
or more distant past, or even in the future because the time period is an
important feature related to the subgenres of the novels: contemporary,
different kinds of historical, and science fiction novels. Therefore, the
values encoded in the first term of this type are set in relation to the
life dates of the author ("text.time.period.author") and to
the year of publication of the novel
("text.time.period.publication") in the subsequent keyword
terms. These terms can take the following values: “contemporary”, “recent
past”, “past”, and “future”. When the time period is not marked in the
text, it is assumed that the time frame of the action can be considered
contemporary, as in the current example “Adoración”. Table 16 summarizes how the values for these
keyword types are determined.
| Type of keyword | Value | Explanation |
|---|---|---|
| text.time.period.author | contemporary | If the narrated time is contemporary to the author (during the author's lifetime) or if it is not marked at all. |
| text.time.period.author | recent past | If the narrated time is within 30 years before the author's birth date. |
| text.time.period.author | past | If the narrated time is more than 30 years before the author's birth date. |
| text.time.period.author | future | If the narrated time is more than 100 years after the author's birth date. |
| text.time.period.publication | contemporary | If the narrated time is contemporary to the publication date (within 30 years before and after) or if it is not marked at all. |
| text.time.period.publication | recent past | If the narrated time is between 30 and 60 years before the publication date. |
| text.time.period.publication | past | If the narrated time is more than 60 years before the publication date. |
| text.time.period.publication | future | If the narrated time is more than 30 years after the publication date. |
356Regarding the author, novels that take place during her or his lifetime are classified as contemporary. They are categorized as belonging to the recent past if the narrated time is within 30 years before the author’s birth date and as past if it is more than 30 years away from it. A novel set in the future is one where the narrated time is located more than 100 years after the author’s birth date. The temporal limits were chosen based on the assumption that 30 years approximately mark a generation and that an author who placed the action of the novel more than 100 years away from his birth date did not expect to live in that future anymore. The time spans were chosen slightly differenty to decide upon the temporality of the novel in relation to its publication date, but they were also based on generational changes. A novel is marked as contemporary if the narrated time is within 30 years before or after its publication date, as recent past if the narrated time lies within 30 to 60 years before its publication, as past if it is more than 60 years ago, and as future if it is located more than 30 years after the appearance of the novel. Obviously, the time spans are narrower for the publication because it is a point in time and wider for the author because his or her life dates are a period of time.
357The last type of keyword included in the text
classification section of the TEI header serves to classify the novels in
terms of prestige (<term type="text.prestige">) as
either “high” or “low”. This metadata value is useful to assess the
composition of the corpus regarding the canonicity of the texts. High or
low literary prestige can be described and measured in many different
ways, for example, considering literary prizes that the works have won,
the number of editions and copies of the texts that were produced, the
number and kind of critical and scholarly engagements with them,
assessing the prestige of the authors or subgenres of the novels, etc.
For this corpus, it was decided to use a measure that is simple to
capture and that reflects how the texts have been valued by scholars and
the public in the second half of the twentieth up to the twenty-first
century. To this end, the union catalog WorldCat was used to check which
novels were republished between 1860 and 2020 as new editions or reprints
of historical editions. All the novels that were republished at least
once during this period are classified as high prestige, the others as
low.318 This measure results in many novels being classified as
high prestige without differentiating further between those that were
only reprinted or reedited once and others that received much more
attention. On the other hand, it clearly points out which works have been
largely forgotten. As the measure applies to works and not authors, there
are cases where some novels of an author are classified as “high” and
others as “low”. In the corpus, 174 novels have high, and 82 have low
prestige.319
358Many more kinds of metadata could be collected for the novels, especially regarding their content. For example, information about the characters could be included. Some of this metadata can be created automatically or semi-automatically, but many kinds need manual checks of selective or full reading. The selection of metadata encoded for this corpus was made to gain insight into some principal parameters and contents of the novels, but as this dissertation focuses on the analysis of subgenres of the novel, more attention was put on metadata related to this aspect. Nevertheless, besides their overview function, the metadata about the settings and time periods covered by the novels can also be used as control values for characteristics of the texts determined automatically with text mining and NLP methods.
359As stated above, the keyword system is controlled by an
external taxonomy stored in the file “keywords.xml”.320 It serves to describe and order the
possible types of keywords and their values and is itself also formulated
in TEI. Example 14 shows
an excerpt from the taxonomy.
<taxonomy xml:id="keywords">
<category xml:id="author">[...]</category>
<category xml:id="text">[...]
<category xml:id="text.narration">
<catDesc>text.narration</catDesc>
<category xml:id="text.narration.narrator">
<catDesc>text.narration.narrator</catDesc>
<category xml:id="text.narration.narrator_1">
<catDesc>autodiegetic</catDesc>
</category>
<category xml:id="text.narration.narrator_2">
<catDesc>homodiegetic</catDesc>
</category>
<category xml:id="text.narration.narrator_3">
<catDesc>heterodiegetic</catDesc>
</category>
<category xml:id="text.narration.narrator.person">
<catDesc>text.narration.narrator.person</catDesc>
<category xml:id="text.narration.narrator.person_1">
<catDesc>first person</catDesc>
</category>
<category xml:id="text.narration.narrator.person_2">
<catDesc>third person</catDesc>
</category>
</category>
</category> [...] </category>
</category>
</taxonomy>
360In the example, the keywords about the narrative
perspective of the novel are listed. Each keyword level and type is
encoded in a <category> element whose attribute @xml:id serves as a unique identifier for the
category in question. The system of categories is organized
hierarchically, which is expressed by the XML element structure. In the
identifiers, which are used in the corpus files to reference the keyword
types, this hierarchy is mapped to a string separated by dots. Categories
on the lowest level correspond to the values that the keyword type can
take. On the different levels, <catDesc> elements are
used to either indicate the name of the category, a description of it, or
its possible values. In the example, the possible values for both
"text.narration.narrator" and
"text.narration.narrator.person" consist of closed lists,
meaning that these keywords can only take one of the values listed in the
taxonomy. In other cases, for example, the authors’ countries of birth,
lists of values mean that these are the countries that appear in the
corpus, but the list is, in principle, open for more entries. Open lists
have the function to ensure that the values of the keywords are spelled
identically each time that they are used. At the same time, they document
the range of values occurring in the corpus.
361The external taxonomy in itself does not guarantee that the
keyword types and values are used in the intended way in the TEI files of
the novels. A Schematron file was created and is referenced from each
corpus file to make sure that the usage of the keywords is consistent
throughout the corpus.321 This file is not only used to check
the keywords but also the other metadata contained in the TEI header, as
example 15 shows.
<sch:pattern>
<sch:rule context="tei:titleStmt">
<sch:assert test="tei:title[@type = 'short'][. != '']">
<sch:value-of select="$cligs-idno"/>: TEI header error:
Short title is missing.</sch:assert>
</sch:rule>
</sch:pattern>
<sch:let name="keywords-file" value="document('keywords.xml')"/>
<sch:pattern>
<sch:let name="cat-narration"
value="$keywords-file//tei:category[@xml:id='text.narration']"/>
<sch:rule context="tei:term[@type=’text.narration.narrator’]">
<sch:assert test="normalize-space(.) =
$cat-narration/tei:category[@xml:id =
'text.narration.narrator']/tei:category/tei:catDesc">
<sch:value-of select="$cligs-idno"/>: Metadata error:
text.narration.narrator</sch:assert>
</sch:rule>
</sch:pattern>
362The first rule applies to the title statement. It contains
an assertion testing whether there is a <title>
element of the type “short”. If this is not the case, an error message is
displayed. The context of the second rule is a keyword term of the type
“text.narration.narrator”. The external keywords file and the definition
of the keyword type to check (“text.narration”) are stored in Schematron
variables. Then it is tested whether the term of the type
“text.narration.narrator” contains one of the possible values listed in
the external taxonomy. If not, a metadata error is raised. The Schematron
file is a good way to complement the general schema controlling the TEI
structure of the corpus because it allows to check the content of the
attributes and elements depending on the XML structure and on the
external taxonomy.322 That way, it allows the definition of more detailed
and rigorous rules, which is useful to ensure that the metadata is
consistent throughout the corpus.
363After the profile description, including the keywords list,
the last part of the TEI header is the revision description, a section
holding information about the revision history of the TEI file. It is
useful to document changes made between different versions of the files,
especially when many different files are updated manually and when
several people work together. For the current project, the revision
description was not essential because the corpus was prepared by one
person and because it does not have a long public history yet. Therefore,
up to now, in most cases, the revision descriptions of the corpus files
only contain one entry indicating when the TEI file was first created
(see example 16). However,
the encoding of changes made to the files might become more important in
the future when this corpus is possibly reused by other researchers.
<revisionDesc>
<change when="2015-03-31" who="#uhk">Initial TEI version.</change>
</revisionDesc>
364To sum up, the encoding of the corpus metadata in the TEI header is kept simple for general administrative and bibliographic information and is more elaborated in the keywords part, where different aspects of the novels that are considered relevant for their stylistic analysis are described. Some of the metadata that is encoded as part of the taxonomic keyword system could as well be placed elsewhere in the TEI file, but it was decided to keep this kind of metadata in one place and in an analogous structure to facilitate the analysis of the texts.
365Besides the TEI header, the second main part of each corpus
file is the transcription and encoding of the novel in the <text> element. It is further subdivided into three parts: <front>, <body>, and <back>. While the body is present in all the TEI files of the corpus,
the other two parts are optional. The front part may contain “any prefatory
matter (headers, abstracts, title page, prefaces, dedications, etc.) found
at the start of the document, before the main body” (Text Encoding Initiative Consortium 2023gText Encoding Initiative Consortium. 2023g. “<front>.”
In: TEI P5: Guidelines for Electronic Text Encoding and Interchange,
1206–1209. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.). The
back part can contain appendices of any kind (Text Encoding Initiative Consortium 2023eText Encoding Initiative Consortium. 2023e. “<back>.”
In: TEI P5: Guidelines for Electronic Text Encoding and Interchange,
933–936. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.). In
the corpus, the front part was used to encode title pages, dedications, and
prefaces of available historical editions of the novels because they often
provide information about the subgenres of the texts. Such front matters
were included in 231 files of the corpus. For the other 25 novels, no
historical editions could be accessed, so no front matter is available.323 Front matters of modern editions were not
transcribed. In example 17,
an excerpt of the front matter for the novel “Adoración” is shown.
<front>
<div source="#PS" n="1906">
<div type="titlepage">
<ab>Biblioteca de Autores Americanos</ab>
<ab>Alvaro de la Iglesia</ab>
<ab>Adoración</ab>
<ab>Novela original</ab>
<ab>Tercera edición</ab>
<ab>Barcelona</ab>
<ab>F. Granada C.ª, Editores</ab>
<ab>Calle de Escudillers, 20</ab>
<ab>Buenos-Aires</ab>
<ab>Serafín Ponzinibbio, Editor</ab>
<ab>B. Mitre, 1.100</ab>
<ab>1906</ab>
</div>
<div type="dedication">
<p><seg rend="italic">A Antonio Herrera</seg></p>
<p><seg rend="italic">en El Mundo</seg></p>
<p><seg rend="italic">testimonio sincerísimo de afecto.</seg></p>
<ab>
<seg rend="italic">El Autor.</seg>
</ab>
</div>
<div type="preface">
<head>Prólogo</head>
<p>Si los hombres no fueran tan dados a vaticinar y tan
reacios a escarmentar, no obstante la facilidad con que se
viene abajo la fábrica de sus pronósticos, no oyéramos con
tanta frecuencia los horóscopos que anuncian casi para día
fijo la muerte de la poesía. [...]</p>
<ab>Enrique José Varona.</ab>
<ab>Habana (Cuba).</ab>
</div>
</div>
</front>
366In the example, the front matter of one historical edition of
the novel from 1906 is transcribed. It includes a title page, a short
dedication, and a longer preface, of which only a part is shown here. In
other cases, there may be several front matters. Each front matter is
enclosed by a division element, indicating its source edition in the
attribute @source (source="#PS"). This
attribute contains a reference to the edition’s bibliographic description in
the source description in the TEI header. The year of the corresponding
edition is encoded in the attribute @n
(n="1906") on the <div> element. Inside
the main division for each front matter, its different parts are encoded in
further subdivisions (e.g., <div type="titlepage">,
<div type="dedication">, <div
type="preface">). Although the TEI offers specialized elements for
the encoding of front matter, e.g., <titlePage>, <byline>, <docImprint>, etc. (Text Encoding Initiative Consortium
2023kText Encoding Initiative Consortium. 2023k.
“<titlePage>.” In: TEI P5: Guidelines for Electronic Text Encoding and
Interchange, 201–203. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.), only the general elements <div>, <ab>, <head>, <p>, and <seg> are used here to keep the overall TEI
model for the corpus simple and because there is no special interest in the
semantics of the front matter structure here. Instead, the front matters are
transcribed with the primary goal of interpreting their contents with regard
to the subgenres of the novels.324
367A back matter is included in 140 of the 256 TEI files. In
general, back matters are less relevant for the subgenre assignment. In most
cases, they only contain a phrase marking the end of the novel (“Fin”) or a
dateline documenting where and when the novel was written (e.g., “Buenos
Aires, Agosto 27 de 1858”). Only rarely notes or comments by the authors are
appended, such as, for example the following remarks made by Ignacio Manuel
Altamirano about the length of his novel “Clemencia” (1869, MX), as shown in
example 18.
<back>
<div>
<head>Nota</head>
<p>El menor de los defectos de esta pobre novelita es que para
cuento parece demasiado larga. Pero no hay que tomar
formalmente la ficción de que el doctor relate esto en una
noche. Es un artificio literario, como otro cualquiera, pues
necesitaba yo que el doctor narrara, como testigo de los
hechos, y no creí que debía tener en cuenta el tamaño de la
narración. Además, a pesar de mi pequeñez me amparan, para
hacer perdonable lo largo del cuento, los ejemplos de Víctor
Hugo en Bug-Jargal, de Dickens en varios de sus Cuentos de
Navidad, de Erkmann Chatrian en sus Cuentos populares, de
Enrique Zschokke en sus Cuentos suizos, y de Hoffman en
muchos de los suyos. En lo que si no tengo amparo es en lo
demás, y no me queda más recurso que apelar a la bondad de
los lectores.</p>
<ab type="signed">EL AUTOR</ab>
</div>
</back>
368The encoding of the main body of the novel’s text is kept
simple, as well. Above all, the markup is used to represent how a novel is
structured into parts and chapters to be able to use this structural
information in the analysis of the texts. Example 19 shows how the beginning of the novel
“Adoración” is encoded.
<body>
<div type="chapter">
<head>I</head>
<head>El escenario</head>
<p>Allí donde se rompe sobre el acantilado granítico el inmenso
empuje de dos mares y el movimiento formidable del Océano
levanta al aire blancas trombas de rugiente espuma
manteniendo en un constante clamoreo las aguas de la costa,
la labor eterna de las olas ha abierto una ensenada en el
abrupto litoral en que va a morir la resaca como en un
remanso, cual si cansada de su fatigoso golpeo se tendiera
perezosa en las brillantes arenas de la playa.</p> [...]
</div>
</body>
369In general, divisions are marked with the element <div>, using the attribute @type
to characterize the kind of division further into "part",
"subpart", "chapter", or "subchapter".
Headings and paragraphs are also encoded. In general, no difference is made
between the main and subheadings. Only longer descriptions of the content of
a following chapter are marked as <head
type="argument">. Regarding the structure inside of the main textual
divisions, it was decided to generally encode blocks separated by line
breaks or blank lines with the element <p>, following a
typographic definition of a paragraph. The only exceptions made are for
verse lines, which are encoded with <l>, and dramatic
speech, encoded with <sp> because these are considered
important distinctions from the point of view of genre analysis. It follows
from this that the content of a <p> element does not
always correspond to the structural linguistic definition of a paragraph as
a sequence of semantically related sentences or as a thematic building block
of a written text.325 A ubiquitous
phenomenon in the novels, for example, is blocks of direct speech. These are
also marked with <p> and additionally with <said>, as explained further below.
370The TEI standard includes many different elements for the
encoding of text blocks, for example, the neutral element <ab>326 or special elements for structures like openers and
closers in letters, for list or table entries, etc. In principle, such
alternative elements would be a better choice to encode blocks in the novels
that are not paragraphs in the linguistic-semantic sense. However, a
detailed analysis of the text bodies would be required to identify such
structures. In addition, more specialized markup would require advanced
scripts for querying the XML structure. Furthermore, it can be estimated
that non-paragraph blocks that are not verse lines, dramatic speech, or
direct speech are few in number in the novels. The <p>
element was therefore preferred here as a general solution for the markup of
typographic blocks in the text body.
371Besides this general structure of divisions, headings, and paragraphs, some more phenomena were encoded, as summarized in table 17.
| Type of phenomenon | TEI element(s) used |
|---|---|
| Typographically marked subdivisions of the text (e.g., with a line or asterisks) | <milestone>
with @unit and @rend |
| Typographically highlighted words or phrases | <seg> with
@rend |
| Gaps | <gap> |
| Verse lines | <lg>, <l> |
| Dramatic text | <castItem>,
<castList>, <sp>, <speaker>, <stage>, <said> |
| Representations of written text | <writing> with
@type |
| Quotations | <quote> |
| Direct speech or thought | <said> |
| Text contained in quotation marks that is not a representation of written text, not a quotation, and not direct speech or thought | <q> |
| Embedded texts interrupting the surrounding text | <floatingText> |
372The encoding of the first two phenomena (typographically marked subdivisions of the text and typographically highlighted words or phrases) aims to preserve minor structural information that was already contained in a structured way in the editions used as sources for the corpus. These typographic details may be interesting when individual sections of texts are analyzed, but they can hardly be used for comparative analyses of all the texts in the corpus. They depend highly on how a specific source edition of a novel was typeset and also on how much of possibly existing typographic information in the sources was kept when editions were digitized. Gaps were encoded to get a quantitative overview of how much text is missing in the novels. The other phenomena that were encoded in the body focus on how the narrated text is presented in terms of genre (prose versus poetry versus drama), medium (written versus spoken), voice, and perspective (quotations, narration, and the representation of speech and thought). In the remainder of this subchapter, examples of the different phenomena that were encoded in the main body of the novels are given, with a special focus on the detection of direct speech and thought.
373Regarding the structure of the novels, sometimes chapters
are divided further into sections. Such subdivisions are marked with
different typographic means in the editions, for example, using a line
between two paragraphs, one or more asterisks or other symbols, or just
more blank lines than between paragraphs of the same section. Wherever
this information was contained in the digital editions used as sources
for the corpus or where it could be marked in the process of text
treatment, it was kept and encoded with the element <milestone>, as example
20 from the novel “A fuego lento” (1903, CU) by Emilio Bobadilla
illustrates.
<p>La vida, durante la noche, se concentraba en la plaza de la
Catedral, donde estaba, de un lado, el
<seg rend="italic">Círculo del Comercio,</seg> y del otro,
<seg rend="italic">El Café Americano.</seg> Las familias
tertuliaban en las aceras o en medio del arroyo hasta las once.
En el silencio sofocante de la noche, la salmodia de las ranas
alternaba con el rodar de las bolas cascadas sobre el paño de
los billares y el ruido de las fichas sobre el mármol de las mesas.
La calma era profunda y bochornosa. El cielo, a pedazos de tinta,
anunciaba el aguacero de la madrugada o tal vez el de la media
noche.</p>
<milestone unit="section" rend="asterisks"/>
<p>La casa de don Olimpio andaba manga por hombro. Misia Tecla, su
mujer, gritaba a los sirvientes, que iban y venían atolondrados
como hormiguero que ha perdido el rumbo. Una
<seg rend="italic">marimonda</seg>, que estaba en el patio, atada por
la cintura con una cuerda, chillaba y saltaba que era un gusto
enseñando los dientes y moviendo el cuero cabelludo.
</p>
374In the edition, several asterisks mark the transition from one section to the other. The paragraph before the section boundary contains the description of a scene on a public square. In the following paragraph, the setting switches to the house of Don Olimpio, so the section boundary coincides with a content-related change inside of a chapter of the novel. However, because it is hard to verify if section boundaries inside of chapters, if present, are represented reliably throughout the different editions of a novel, the corresponding milestones will not be used systematically to analyze the structure of the novels. They were primarily encoded to not lose the existing structural information and because they can still be useful when individual passages of the novels are inspected.
375In the editions of some novels, individual words or phrases are highlighted using italics. A number of reasons can be identified for such highlighting, for example:
<seg> with the attribute @rend
indicating how the emphasis is rendered typographically, as shown in example 21.
<p>—¿Cómo se llama Vd.?</p>
<p>—<seg rend="italic">Me ñama Ginoveve Santa Crú. Mi marío e
Tribusio Polanca. Elle tien uno sijo ñamao Malanga que ha
sacao mala cabesa. ¡Ha matao ma branco!... Tondá lo coge como
ratón con quesa le dominga depué de Niño perdío, cuando diba
nel entierre de ña Chepa Alarcó.</seg></p>
<p>—¿Chepilla Alarcón? repitió preguntando María de Regla.</p>
<p>—<seg rend="italic">Sí, sí, agrego Genoveva. Le meme. Asín se
ñamaba. Ha perdío un güen caserite.</seg></p>
<p>—¿Tenía una nieta?</p>
<p>—<seg rend="italic">Sí, tube un. ¡Ma linde! ¡Ah! ¡qué bunite! No
la ha vito ma bunite en la vía.</seg></p>376In the case of incomplete, partly damaged, or illegible
source editions, there may be gaps in the text body. Wherever they became
apparent in the process of text treatment, these gaps were marked up with
the element <gap>, with the goal to be able to
quantify the overall amount of missing text in the corpus. The encoding
of a gap is illustrated in example 22.
<p><said>—Sí, pero yo quiero romper esas ligaduras; sí, quiero
romperlas, porque un día miro cercano en que no pudiendo ya
mi corazón hacerse más violencia, romperá las cadenas de su
deber, atro-</said></p>
<gap unit="page" extent="2" reason="missing"/>
<p>luchar hasta morir al frente de vuestros ejércitos, y si llegáis
a vencer un día, acordaos de que soñó con vuestra independencia
el infortunado nieto de Cárlos I.</p>
377Three attributes are added to the <gap>
element, characterizing it further. In the case at hand, the gap consists
of two (extent="2") missing (reason="missing")
pages (unit="page"). Possible values for @unit are "page", "line",
"word", and "char". The number of missing units
is given in @extent. Sometimes it cannot be known
exactly how many items, for example, words or characters, are missing. In
such cases, the number is estimated. For the purpose of this text
collection, the attribute @reason may take the
values "missing" or "illegible".327
378Verse lines were encoded using the elements <lg> for groups of verse lines and <l> for single verse lines. The main interest in encoding verse
lines in the novels lies in the ability to calculate the proportion of
poetry contained in the prose texts. Verse lines were detected in the
process of text conversion from the source editions to the TEI files and
also searched for with a simple XPath expression in the resulting XML
files: //p[count(tokenize(.," ")) <
10][not(contains(.,"—"))]. This expression finds blocks that
are encoded as paragraphs, that are shorter than ten tokens separated by
whitespace, and that do not contain a long hyphen, which is a
conventional speech sign. The expression assumes that verse lines are
usually short. It also returns short prose paragraphs but helps to scan
through possible candidates for verse lines quickly. Poems are typically
included in the novels as part of quotations, for example, at the
beginning of chapters, as part of the representation of written
materials, for instance, love letters, or as songs sung by characters, as
in example 23 below.
<p>Boca-lobo guardó su moneda.</p>
<p>El jefe se levantó de su asiento, y los demás le siguieron.</p>
<p>Al retirarse, el jefe, para demostrar su complacencia, se puso a
cantar en voz baja:</p>
<said>
<lg>
<l>"El que pasa una noche</l>
<l>en rumbantela,</l>
<l>si está triste se alegra</l>
<l>y se consuela;</l>
<l>que está probado</l>
<l>que, el que de rumba anda</l>
<l>nunca está <seg rend="italic">triste</seg>."</l>
</lg>
</said>
379Dramatic text was encoded for the same reason as verse
lines – to get an overview of how much of this structure that is
characteristic of another major genre, drama, is included in the novels.
In the CLiGS TEI schema, all the typical elements for encoding dramatic
text are available because the schema also covers collections of drama.
In this corpus of novels, mainly the elements <sp>
for speech in a performance text, <speaker> for
labels giving the name of a speaker, <p> for the
structure of the speech, and <stage> for stage
directions are used, as illustrated in example 24. In the excerpt taken from the
novel “Pot-pourri (Silbidos de un vago)” (1882, AR) by Eugenio
Cambaceres, a whole chapter is presented as a dramatic scene. In this
case, the narrator uses this generic shift as a stylistic means to
caricature the behavior and personality of other characters. As can be
seen, even though elements of drama are used, in this case, they are
mixed with prose paragraphs in which the narrator comments on the
dialogue.
<div type="chapter">
<head>X</head>
<sp>
<speaker><seg rend="italic">Juan</seg>.</speaker>
<p>— ¡Una y mil veces malditos los negocios!</p>
<p>¡Quién pudiera nutrirse de ambrosía como los habitantes del
Olimpo!</p>
<p>Ved aquí a un hombre joven, sano, alegre, dispuesto, que no
ambicionaría otra cosa, sino que lo dejaran vivir eternamente
mano a mano con su mujercita a quien adora, siendo a su vez
adorado por ella... <stage><seg rend="italic">(le da un
beso)</seg></stage>.</p>
</sp>
<sp>
<speaker><seg rend="italic">María</seg>.</speaker>
<p>— ¡Juan, por Dios, qué dirá este caballero!
<stage><seg rend="italic">(poniéndose colorada hasta
la punta de la nariz con incomparable
modestia)</seg>.</stage></p>
</sp> [...]
</div>
380To find passages of dramatic text contained in the novels,
again, they were checked during the process of text conversion.
Furthermore, the XPath expression //p[tokenize(.,"
")[1][ends-with(.,":") or ends-with(.,".")]] was used on the
TEI files to detect paragraphs beginning with the pattern
NAME: or NAME.
381A phenomenon that occurs in many of the novels is that some
kind of written text that forms part of their fictional world is
presented by the narrator or by characters. This can be, for example, a
diary entry, a letter, a newspaper article, a short note, a historical
document, an inscription, for example, on a tombstone, or one of many
other types of writings. The inclusion of written texts into the novels
ranges from pure mentions, for instance, that somebody received a letter,
to selective citations of their content and full representations of the
documents. In some cases, the written texts are shown by the narrator, in
others, they are read by characters. Representations of written text are
often easy to detect in the novels because they are usually
typographically differentiated from surrounding text in the source
editions and are often introduced with angular or curved quotation marks
(«...» or “...”). The encoding of inserted written texts is of interest
for stylistic analyses of novels and their subgenres for two main
reasons. First, it appears that certain types of writings are typically
included in novels of a certain subgenre. Letters, for example, are often
found in romantic and sentimental novels, and source documents are often
cited in historical novels. Being able to analyze the amount of different
types of written text represented in the novels allows us to examine such
hypotheses. Second, when written texts are represented directly, they
often entail a change of perspective in the novels, for example, from a
third-person to a first-person narrator or vice-versa, which also affects
the style of the novels. The element <writing> was
used to encode representations of written text, as shown in example 25, which contains a
newspaper advertisement included in the novel “La virgen del Niágara”
(1871, MX) by José Rivera y Río.
<p>Felipe mostró a su amigo un aviso que el día anterior había hecho
insertar en el <seg rend="italic">Herald</seg> y que decía poco más
o menos lo siguiente:</p>
<p
><writing type="newspaper">“Los dos caballeros que entraron en el
ómnibus de la estación de Fulton, se considerarán muy
agradecidos si las dos hermosas señoritas vestidas de luto a
cuyo frente se sentaron y con quienes se sonrieron, les conceden
el honor de una entrevista. Dirigirse al despacho del
<seg rend="italic">Herald,</seg> a F. y <seg rend="italic">M.</seg>”
</writing>
</p>
<p>—Esta aventura,—dijo Felipe,—nos va a indemnizar del tedio de este
domingo.</p>
382The element can be used inside paragraphs to mark short
stretches of written text, but it can also contain entire embedded
documents. Table 18 lists the
types of written texts that were differentiated in this corpus, as
indicated in the attribute @type on the <writing> element.
@type |
Description |
|---|---|
| letter | letters and any other kind of notice directed to someone |
| newspaper | newspaper articles of any kind |
| diary | diary entries and other kinds of written monologues (e.g., memoirs) |
| document | other kinds of written documents (e.g., notes, reports, historical sources, inscriptions) |
| book | parts of printed books |
| poem | written poems |
| speech | written speeches directed to someone |
| unknown | if it is just known that something is written but the kind of writing cannot be specified |
383Although the overall range of types of written texts represented in the novels is broad, it was decided to focus on a few recurring types and to define these types broadly. From a systematic point of view, the different kinds of writing may overlap. A letter, for example, can be published in a newspaper, or a poem can be part of a diary entry. The most obvious and prominent type was chosen for each writing, also depending on how it is announced in the novel. Some of the types of writings are usually connected to changes in the narrative perspective, for example, letters, diary entries, and speeches. The others primarily entail a style and type of language use that differs from the surrounding narrated or spoken text.
384According to the TEI Guidelines, a quotation is “a phrase
or passage attributed by the narrator or author to some agency external
to the text” (Text Encoding
Initiative Consortium 2023iText Encoding Initiative Consortium. 2023i. “<quote>.”
In: TEI P5: Guidelines for Electronic Text Encoding and Interchange,
1581–1583. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.). The element <quote> is used in that sense to mark passages that are clearly
attributed to other authors, like the two quotations of Balzac and
Milanés in example
26 below.
<div type="part">
<head>Libro Primero.</head>
<quote>
<p xml:lang="fr">La paix profonde et sereine imprimée par les
sculpteurs aux visages des figures vierges destinées a
representer la justice, l'innocence, toutes les divinités
qui ne savent rien des agitations terrestres; ce calme est
le plus grand charme d’une fille, il est le signe de sa
pureté; rien encore ne l’a emuée; aucune passion brisée,
aucun intérét trahi n’a nuancé la plácide expression de
son visage; est il joné, la jeune fille n’est plus.</p>
</quote>
<p>De Balzac.</p>
<div type="chapter">
<head>I.</head>
<quote>
<lg>
<l>Necio, y digno de mil quejas</l>
<l>el que ronca sin decoro</l>
<l>cuando el sol con rayo de oro</l>
<l>da en las domésticas tejas.</l>
</lg>
</quote>
<p>J. J. Milanes.</p>
<p>Acababa de amanecer, y el tibio sol de invierno a
principios de febrero del año pasado, derramaba mansas
olas de luz sobre los techos y campanarios de la ciudad,
que comenzaba e despertar de un delicioso sueño. [...]</p>
</div>
</div>
385In the novels, such quotations are often found at the beginning of parts and chapters, as in the example, but do also occur inside of chapters, where they are usually highlighted with quotation marks. Representations of written texts that are part of the fiction are understood to be internal to the text and are not treated as quotations in this corpus. Direct speech reported on whatever level is also not interpreted as quotation.
386Regarding structural elements of the texts below the chapter level, it was also decided to encode direct speech and thought expressed by characters of the novels. The difference between the narrator text and the representation of character speech and thought is a fundamental aspect of the various possible narrative strategies used in novels to present the plot, characters, and setting, and it can be considered a stylistic choice (Leech and Short 2007, 255–281Leech, Geoffrey, and Mick Short. 2007. Style in Fiction. A Linguistic Introduction to English Fictional Prose. 2nd ed. Harlow, England: Pearson Education Limited.). Therefore, it is also of interest for a stylistic analysis of the subgenres of the novels. For example, it can be asked to what extent the amount of direct speech in a novel differs depending on the subgenre to which the novel belongs, or in what way narrated text and direct speech differ stylistically from subgenre to subgenre. Because also indirect forms are possible, direct speech or thought is only one of the variants of character speech and thought representation, but it is the one that is easiest to detect because it is often introduced by speech signs. To simplify, by differentiating the direct forms from the surrounding text, indirect variants are considered as part of the narrated text here. The encoding of direct speech and thought in the TEI files prepares its use as a feature for textual analysis. Hence, the topic is covered in this section with regards to text encoding, but the generation of features for genre analysis that are based on the distinction between direct speech and narrated text is a future task that can be carried out starting from the encoding of the texts in this corpus.
387To manually markup all direct speech in novels would be a very time-consuming task. Therefore, an automatic approach relying on the usage of typographic speech signs and using regular expressions was pursued here for a part of the corpus. However, given that the typographic signs were not reliable enough, expensive manual checks were indispensable. The problem of unreliable signs for the detection of direct speech is, on the one hand, a general one. It is caused by the overall tradition of how character speech is signaled typographically in Spanish language novels. On the other hand, the issue is complicated if a corpus considerably relies on historical editions, such as the one described here, because speech signs are handled less consistently in historical than in modern editions. Therefore, it was decided to only encode the direct speech in a subset of the corpus. Little more than one-third of the novels (92 texts) were prepared with the mentioned semi-automatic approach. These texts were selected randomly from the corpus, with no special focus on certain kinds of editions, authors, genres, or narrative perspectives.328 The direct speech encoding in this part of the corpus constitutes a gold standard that can be used as a training set to build machine learning models for detecting direct speech in novels.329
388In what follows, the encoding of direct speech in the TEI files is outlined. First, some general problems of defining what direct speech is are discussed, which arise independently of the question of how to detect it, but have consequences for it. Then the difficulties of using typographic speech signs as indicators in nineteenth-century Spanish-American novels are explained. Finally, the subset of the corpus with encoded direct speech is used to estimate the loss of information that would result from only relying on typographical signs. This is done by comparing the checked annotations with results that would have been obtained by applying the pure regular expression approach to the same files. The score can be compared to results usually obtained with machine learning approaches based on other features and indicate if and to what extent a learning-based approach would be advantageous over a simple regular expression approach.
389For the encoding of direct speech and thought, the TEI
element <said> was used, as example 27 from the novel “Adoración”
illustrates.
<p><said>—¿Pero ya estás bien, Daniel?</said>—me preguntó
solícita.</p>
<p><said>—Bien del todo, Adoración. ¡Si no valió nada! Lo que
siento solamente es los días que me privó de verte.</said></p>
<p>Adoración lanzó un suspiro.</p>
<p><said>—¡He pensado tanto en ti! Mira; hasta me atreví a
suplicarle a Estrovo que averiguase la causa de tu
ausencia.</said></p>
<p><said>—Sí; él acaba de decírmelo.</said></p>
<p><said>—¿Te lo contó?</said>—exclamó Adoración poniéndose muy
colorada.<said>—Yo siento que haya sido una indiscreción de
mi parte, pero estaba tan cuidadosa......</said></p>
<p>¡Qué remordimientos más atroces sentí entonces! Aquella pobre
niña, con su afecto tierno y sincero tan ingenuamente expresado,
era el mayor castigo que pudiera yo recibir por mi defección. La
tomé una mano [...]</p>
390In “Adoración”, the beginning of direct speech is marked with a long hyphen. If not otherwise indicated, the speech ends with the end of the paragraph (e.g., “—Sí; él acaba de decírmelo.”). Alternatively, there may be a phrase closing the speech (e.g., “—me preguntó solícita.”) which is itself introduced by a speech sign. In addition, there are insertions leading over from one speech act to the next inside of paragraphs, which are also marked with hyphens (e.g., “—¿Te lo contó?—exclamó Adoración poniéndose muy colorada.—Yo siento [...]”). In the example, the direct speech corresponds to speech acts expressed by the characters in dialogue and is easy to distinguish from the surrounding narrative text, also because the speech signs are used in a consistent way in this edition of the novel “Adoración”.
391In general, however, the report of direct speech in novels
is not limited to the representation of character dialogues. For example,
the transition between direct and indirect speech and thought reported by
the narrator can be smooth, as example 28 from the novel “S. Y.” (1895, CU) by Francisco
Calcagno shows.
<p>¿Qué infame suerte era aquella suya que lo condenaba siempre a
ser deudor del hombre a quien ansiaba poder odiar? ¡Ah! ¡el
viejo rey Priamo tuvo, que besar la mano del matador de su hijo;
y él, Milanés, lleno de rencor y de odio, tenía que dar las
gracias a quien le había de arrebatar a la mujer que amaba! ¡Y
no poder ni vengarse! Un puñal en aquel alevoso pecho... no, ¡él
no era hombre de puñal! pero frente a frente, cuerpo a cuerpo,
con armas iguales, escarnecerlo, atacarlo, estrecharlo,
confundirlo y atravesarle de parte a parte el pecho...</p>
<p><said>—¡Oh!... ¡si llegara ese momento</said>,—pensaba,—
<said>aunque cayera sobre su cadáver el mío! Miserable que
atrincherado en su colosal riqueza, me confunde a beneficios,
y tal vez ríe de mi impotencia; me arrebata la felicidad, y
seguro de su triunfo, tan impotente juzga a su rival que lo
protege y lo enriquece y paga sus deudas y hasta le cede el
puesto al lado de su novia. ¡Y no puedo batirme! ¡y no puedo
matarlo! ¡y Jacinta me prohíbe que lo afrente! y tengo,...
¡ah! no; yo le arrojaré sus favores a la cara; mi odio será
más potente que sus beneficios, yo le haré ver que prefiero
la indigencia a la riqueza que proceda de su infame mano...
yo le... pero ¡ay!... ¿y mi pobre madre?</said></p>
<p>¡Así suele cegarnos la pasión! así, ofuscado por el lóbrego
porvenir de su amor desgraciado, se empeñaba en acriminar a
aquel don Cristóbal cuya meritoria conducta mal su grado se veía
obligado a reconocer y admirar.</p>
392Here, the thoughts of a character are represented,
switching between free indirect and direct thought. Only the direct
thought is encoded with the <said> element. In other
cases, the narrator uses quotation marks to highlight individual words or
passages, only some of which can be understood as citations of character
speech, as in examples
29 and 30,
taken from the novels “Los precursores” (1909, MX) by José López Portillo
y Rojas and “La Ginesa” (1894, AR) by Carlos María Ocantos, respectively.
<p>Y para que nada faltase a sus inocentes hechizos, había recibido
de Dios la índole más mansa y cariñosa que se ha visto. Nunca se
oponía a nada, a todo estaba constantemente dispuesta; su
complacencia era perpetua e intuitiva. La primera palabra que
aprendió a decir, después de <q>“mamá”</q>, fue <q>“sí”</q>. A
todo cuanto se le decía, contestaba que <said>“sí”</said>.</p><p>Y en esto llegó una carta de la capital para Lía, y Lía la
guardó sin abrirla, trémula, leyendo con los ojos del alma los
garrapatos del niño adorado: <writing type="letter">«Ven,
Ginesita; ¡si no vienes, me muero! ¡no puedo más! cruel,
perversa, ingrata...»</writing> Llegó otra y también la
guardó sin abrirla, pero adivinando cuanto decía:
<writing type="letter">«Si no vienes, creeré que te has marchado con
otro y que eso de haberte refugiado en Las Piedras, al lado
de tu madre, es una papa...»</writing> Y tres más, cuyos
sobres dejó intactos, aunque figurábaselas cariñosas, coléricas,
o desesperadas; pero, cuando a la visita matinal del cartero
sucedió la del telegrafista y Cándido la entregó, con ligera
sonrisa irónica, el feo sobre color de ladrillo, diciéndole al
oído: <said>«¿Será del hijo del patrón, que se
impacienta?...»</said> no hubo más remedio que enterarse del
despacho y que el niño dispuesto estaba <q>«a venir, si ella no
iba»</q>. Tal susto llevó, que la fiebrecilla, que remitido
había días atrás, la retentó nuevamente.</p>
393In such passages, of the stretches in quotation marks, only
those that are announced as speech by a reporting clause or that are
recognizable as direct speech by the form of the pronouns and verbs are
marked as direct speech. The others are interpreted as another form of
emphasis by the narrator, which is marked up with the general element <q> for quoted material here.330 In the first example, the words “mamá” and “sí”
are first mentioned as general linguistic units and are therefore encoded
with <q>. In the next sentence, the word “sí” is
cited as an answer that the little girl Berta mentioned in the passage
gives regularly and is therefore marked with <said>.
In the second example, the quotation marks are used with several
different functions. First, the content of two letters is cited («Ven,
Ginesita [...] and «Si no vienes [...]) and marked as written text with
the element <writing> here. Next, a question directly
uttered by the character Cándido, which is marked as direct speech,
follows: «¿Será del hijo del patrón [...]?». Third, the content of a
telegram is cited in quotation marks but in indirect form («a venir, si
ella no iba»). Therefore, it is not interpreted as direct speech but
instead marked with <q>. In the above examples, the
degree of mediation of character speech by the narrator varies inside of
the same and between subsequent paragraphs. These examples show that
beyond the classic character dialogue, there are cases where detailed
decisions are required to draw the line between what is considered direct
speech and what is not.
394Another aspect that needs to be considered is that the
thought and speech of characters, even if it is clearly represented
directly, can take the form of a monologue or a longer argumentative or
narrative passage. Without knowing the context of the utterances, it can
be difficult to recognize that such passages are direct speech.
Furthermore, direct speech can be reported on several levels in a novel.
If a character speaks and becomes the narrator, he or she can cite the
speech of other characters directly. The question is whether all
character speech, independently of its functional text type,331 should be
treated as direct speech. Here it was decided to mark up direct speech on
several levels so that nested structures are possible and to rely on the
outer structure to decide if a token is part of direct speech or not.
Nevertheless, if the speech of a character is announced as narration
inside of the novel and extends over many paragraphs or whole chapters
without being explicitly marked by speech signs, it is typified as
“narration” with the attribute @ana, as example 31 shows.
<p><said>—¿Duermes, bella Cheherazada?</said> —dije a Laura cuando
le hube contado seis horas de sueño—. <said>Pues si estás
despierta, refiéreme, te ruego, esa interesante
historia.</said></p>
<p><said>«De cómo Laura moribunda
recobró la salud y la hermosura por la ciencia maravillosa de
un médico homeópata».</said></p>
<p><said ana="#narration">Un día, uno de los peores de mi dolencia, en
su interminable charla sobre las excelencias de la
homeopatía, recordó la insigne calaverada de un joven cliente
suyo, tísico en tercer grado, que apartándose del método por
él prescrito, impuso a su arruinado pulmón la fatiga de
interminables viajes.</said></p>
<p><said ana="#narration"><said>—Y, extraña aberración de la
naturaleza</said> —añadió—, <said>aquel prolongado
sacudimiento, aquel largo cansancio, lo salvaron; sanó...
Pero son esos, casos aislados, excepcionales, que no
pueden reproducirse. Aplíquese el tal remedio aquí, donde
ya no hay sujeto; y en la primera etapa todo habrá
acabado.</said></said> [...]</p>
395The example includes selected paragraphs of the first
chapter of the novel “Peregrinaciones de un alma triste” (1876, AR) by
Juana Manuela Gorriti. The novel is narrated in the first person.
However, the principal narrator mainly cedes the word to her friend Laura
who narrates her travels through Chile, Argentina, Paraguay, and Brazil,
so that almost the whole novel could be interpreted as direct character
speech. Even so, as Laura becomes the narrator, her speech is marked as
narration here and is excluded from the direct speech
analysis. On the other hand, the character speech cited by her, such as
the words of the doctor in the example, are counted in.
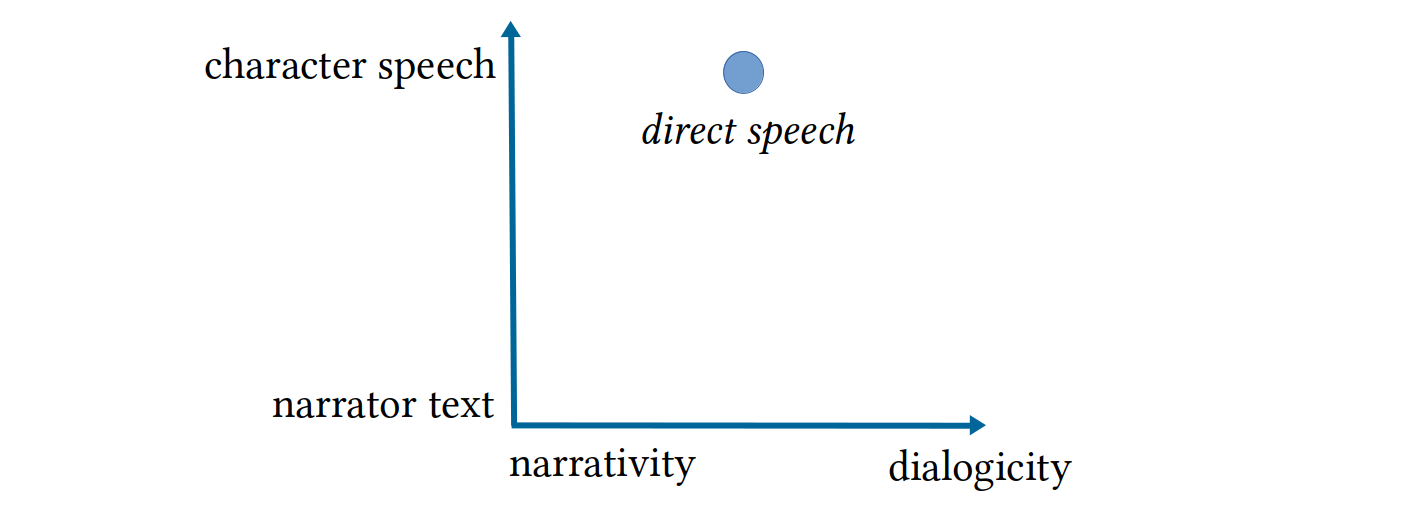
396In figure 28, a sketch of the kind of direct speech annotated in this corpus is given along the two axes of narrator text versus character speech and narrativity versus dialogicity. Here it was decided to mark up character speech that can be part of a dialogue, but that can also be a monologue, and that can be narrative to a certain degree. Nevertheless, when passages are formally character speech (considering the overall structure of the novel) but linguistically and typographically not distinguishable from narrator text (considering the local context), they are marked as narrative speech. On the other hand, only speech that is contrasted with the narrator text through speech signs and/or linguistically recognizable as such is marked up as direct speech. Ambiguous forms are associated with the narrator text. Another axis that is not displayed in the figure is the one between written and spoken language. Here it was decided not to mark up representations of written text (e.g., a letter inserted into a novel) as direct speech unless they contain cited spoken language (e.g., a character dialogue cited in a letter inserted into a novel). However, written language can be close to oral speech (e.g., diary entries, notes, or letters) and is often also marked with the same signs as speech in the novels. The choices made here focus on the local context of the utterances and favor clear typographic and linguistic signs. This probably meets the characteristics of automatic recognition of direct speech quite well. Still, the passages marked up as direct speech are not limited to simple character dialogue. When comparing the results of direct speech recognition in fictional narrative prose texts, it should be kept in mind that the definition of direct speech underlying the analysis influences the results.
397Turning to the question of how to capture direct speech technically, a rule-based approach can be used in the case of consistent use of speech signs, as in the edition of “Adoración” cited in the first example above. To this end, an XSLT script was created,332 which marked all paragraphs beginning with a speech sign as direct speech or thought. Subsequently, the encoding was refined by also transforming insertions and closing phrases inside of paragraphs. Regular expressions were used inside the XSLT to detect relevant cases. The script differentiates between different types of speech signs (e.g., dashes versus angular or curved quotation marks) and speech sign types (single versus double). It focuses on one primary speech sign type per novel. The aim of the script is to detect as much direct speech as possible with rather simple rules.
398Unfortunately, this strategy is not suitable to detect
direct speech and thought reliably across all kinds of editions because
there is much variation in the presence and absence of speech signs. In
many cases, no signs are used at all. Sometimes only the narrative
insertions and closing phrases are not marked, but there are also cases
where even the beginning of the direct speech is not indicated with a
special sign. Furthermore, when a character speaks over several
paragraphs, usually, only the first one is marked with a speech sign, and
the reader has to infer from other indicators that the speech continues.
An automatic approach that is only based on speech signs can miss longer
passages of direct speech in such cases. Even more complicated are
editions where no consistent usage of speech signs can be recognized at
all. An example is shown in figure
29, displaying two pages of the first edition of the novel
“Libro extraño” (1894, AR) by Francisco Sicardi.333

399On the first of the two example pages, speech signs are used, but only to mark the beginning of direct speech. Insertions in the middle of the speech are not marked typographically (for example: “—Tata era bueno y honrado, contestó Genaro y la besó en la frente. Tú no te acuerdas porque eras muy chica....”). Speech inside of speech is highlighted with angular quotation marks (“[...] las cosas que me dijo.... «Esa chiquita va á ser tu hija, no olvides nunca tu nombre»”). On the second example page, in contrast, no speech signs are used at all: “Si, si yo te conozco [...] Por qué está triste, mi viejo papá querido? agregó la niña [...]”. In such editions, direct speech can hardly be captured with simple rules relying on punctuation and speech marks.
400A case where the direct speech of a character continues in
subsequent paragraphs without being indicated typographically is
illustrated in example 32,
taken from the novel “Puebla” (1903, MX), which is part of the work “La
Intervención y el Imperio (1861–1867)” by Victoriano Salado Álvarez.
<p>Miró el mexicano a su compañero con cara de espanto, y el otro,
sin esperar a que le pidieran explicaciones, habló así:</p>
<p><said>—Me llamo Nicolás Chardon, soy originario de París y mi
padre es normando, de tierra de Rouen. Profesor de latín en
las Universidades de provincia, no ha cesado un punto desde
que se entronizó el Imperio, de hacerle la guerra mediante la
propaganda republicana más activa...</said></p>
<p><said>El ministro Duruy, que atribuyó a mi padre los famosos
<seg rend="italic">Propos de Labbiennus,</seg> le
persiguió con durísima saña, pues aseguraba que ninguno de
los profesores de Francia podía escribir una sátira tan
erudita y tan mordaz... [...] </said></p>
<p>Refirió Miguel su vida y sus andanzas; y cariñoso el otro le
ofreció su amistad y su afecto.</p>
401In the example, the speech is introduced with the phrase “habló así:” and an opening speech sign. The character Nicolás Chardon talks about his origin and career over several paragraphs. The only way for the reader to know that the direct speech ends is to note the change of perspective that is signaled by the person of the verb forms and pronouns and by the mention of the characters involved: “Refirió Miguel su vida y sus andanzas; y cariñoso el otro le ofreció su amistad y su afecto”.
402An additional factor complicating the automatic capture of
direct speech indicated by hyphens is that the same sign may also be used
as a marker for explanatory, meditative, or other kinds of parenthesis
that are not direct speech, as depicted in example 33.
<p>Nunca me habló de su familia: yo creo que jamás la tuvo. Vivía
sólo como un hongo, allá en su vivienda,—que como he dicho ya,
no conocí nunca,—y solo también entre los arrecifes en que
buscaba el sustento, ya con la caña, ya con el disparo en que
era diestrísimo. Algunas veces me veía cerca y me saludaba con
respetuoso afecto.</p>
403Angle and curved quotation marks, too, are not only used to mark direct speech but also for representations of written text, for quotations, for highlighting foreign words, or for other types of emphasis, as was shown above.
404Because of the limitations of the regular expression-based
approach using typographic speech signs, it was only applied to a subset
of 92 novels in the corpus, which were then checked manually. To be able
to estimate the loss of information caused by only using typographical
indicators, the checked annotations were compared with the results
obtained by the pure regular expression approach. To this end, tokenized
versions of the 92 novels in TEI were created, to which stand-off markup
with direct speech annotation was added. The first set of stand-off
annotations is for the manually checked direct speech gold standard
(DS_gold), and the second set is for the speech
annotation based on regular expressions (DS_reg). In example 34, an excerpt of
this derivative format is given for the novel “El guajiro” (1842, CU) by
Cirilo Villaverde.
<w xml:id="p367.w135">las</w>
<w xml:id="p367.w136">palabras</w>
<w xml:id="p367.w137">no</w>
<w xml:id="p367.w138">le</w>
<w xml:id="p367.w139">salieron</w>
<w xml:id="p367.w140">enteras</w>
<w xml:id="p367.w141">:</w>
<w xml:id="p368.w1">—</w>
<w xml:id="p368.w2">¡</w>
<w xml:id="p368.w3">Señores</w>
<w xml:id="p368.w4">,</w>
<w xml:id="p368.w5">fuera</w>
<w xml:id="p368.w6">de</w>
<w xml:id="p368.w7">la</w>
<w xml:id="p368.w8">valla</w>
<w xml:id="p368.w9">!</w>
<w xml:id="p369.w1">Despejada</w>
<w xml:id="p369.w2">enteramente</w>
<w xml:id="p369.w3">la</w>
<w xml:id="p369.w4">valla</w>
<linkGrp type="DS_gold"> [...]
<link target="#p367.w135 #NARR"/>
<link target="#p367.w136 #NARR"/>
<link target="#p367.w137 #NARR"/>
<link target="#p367.w138 #NARR"/>
<link target="#p367.w139 #NARR"/>
<link target="#p367.w140 #NARR"/>
<link target="#p367.w141 #NARR"/>
<link target="#p368.w1 #DS"/>
<link target="#p368.w2 #DS"/>
<link target="#p368.w3 #DS"/>
<link target="#p368.w4 #DS"/>
<link target="#p368.w5 #DS"/>
<link target="#p368.w6 #DS"/>
<link target="#p368.w7 #DS"/>
<link target="#p368.w8 #DS"/>
<link target="#p368.w9 #DS"/>
<link target="#p369.w1 #NARR"/>
<link target="#p369.w2 #NARR"/>
<link target="#p369.w3 #NARR"/>
<link target="#p369.w4 #NARR"/>
[...]
</linkGrp>
<linkGrp type="DS_reg">
<link target="#p367.w135 #NARR"/>
<link target="#p367.w136 #NARR"/>
<link target="#p367.w137 #NARR"/>
[...]
</linkGrp>
405As the example shows, the direct speech annotation is made
per word token. Here, the words with the identifiers p367.w135 up to
p357.w141 are marked as narrated text (#NARR) in the gold
standard, followed by direct speech (#DS) up to word
p368.w9, continuing with narrated text. The structure of the second
annotation set DS_reg is the same as for the gold standard so that it is
possible to compare directly whether there are differences in the two
approaches.334 This was
done by calculating the precision, recall, accuracy, and F1 scores for
all the novels, and comparing the DS_gold annotation with
DS_reg.335 The resulting scores are displayed in
figure 30.
406The median F1 score is at 90 %, which is quite a good
result for a regular expression-based approach. It is comparable to the
results achieved with machine learning approaches in other studies.336 For
the second and third quartile, the scores range from 80 % to 95 %, which
also seems acceptable, but when also outliers are considered, the
dispersion of values is broad, and there are some cases with very low
scores. This means that the regular expression-based approach is very
successful in many cases, but apparently, it fails in some cases, so it
is not very reliable. Considering not only F1 but also other types of
scores, the differences between them point out some strengths and
weaknesses of the regular expression approach. The precision and accuracy
scores are higher and vary less than the recall scores, which means that
there are more false negatives (i.e., actual direct speech tokens that
were not recognized) than false positives (i.e., actual tokens of
narrated text that were mistaken as direct speech). So apparently, whole
paragraphs of direct speech that are missed because there is no initial
speech sign weigh more in quantitative terms than individual tokens of
narrated text that are contained in paragraphs with initial speech signs
but not marked explicitly by further signs, at least if the speech signs
are single dashes and not double marks. In figures 31 and 32, the F1 scores are differentiated by the kind of source
edition (modern, historical, or unknown)337 and by the type of speech sign (single or double) to
see if these factors have an influence on the results.
407Contrary to what one would expect, the median F1 score is
similar for the three kinds of editions: 91 % for historical editions,
and 90 % for both modern and unknown editions, so historical editions are
not more problematic than other kinds of editions. However, the
comparison of types of editions relies on different group sizes. In the
corpus, there are 158 historical editions, but only 78 modern ones, and
20 cases where the kind of source edition is unknown. The results might
be different in a dataset that is more balanced in this aspect. Above,
several factors complicating the use of speech signs for direct speech
recognition were discussed. The findings for the different kinds of
source editions suggest that inconsistencies in the usage of speech
signs, which were recognized more often in historical editions than in
modern ones, are not decisive.
408To look at the type of speech sign is not very instructive, either, because, in the whole corpus, there are only three novels based on source editions with double speech signs.338 To get a better sense of the factors influencing the results, it would be necessary to inspect the passages and tokens that were misclassified, which is considered a future work. Furthermore, this semi-automatically edited gold standard can be used to develop a machine-learning workflow to see if even better results can be achieved with it. Moreover, such a workflow could be reused in other contexts. Research into the automatic detection of direct speech in narrative texts is not abundant and has not been conducted based on a corpus of Spanish-American novels yet. Developing such a workflow would, therefore, also be of interest from a methodological point of view.
409To conclude the presentation of TEI elements that were used
to mark up the text body of the novels, the element <floatingText>, which serves to encode embedded texts, needs to be
introduced. It can contain an entire textual body with divisions,
paragraphs, etc. In the TEI guidelines, this element is defined as
follows: “<floatingText> contains a single text of
any kind, whether unitary or composite, which interrupts the text
containing it at any point and after which the surrounding text resumes”
(Text Encoding Initiative
Consortium 2023fText Encoding Initiative Consortium. 2023f.
“<floatingText>.” In: TEI P5: Guidelines for Electronic Text Encoding
and Interchange, 1192–1194. Version 4.6.0. Revision f18deffba. https://web.archive.org/web/20230423102337/https://tei-c.org/release/doc/tei-p5-doc/en/Guidelines.pdf.). It is thus a useful element to encode
passages in novels that occur inside of chapters but have their own
structure, for example, an own title, an own heading, or own
chapters.339 The encoding of
floating texts is shown in examples 35 and 36.
<p>D. Luis empezó a leer la siguiente carta:</p>
<said>
<writing type="letter">
<floatingText>
<body>
<div>
<p>Parroquia de Santa Maña, Febrero 2 de 1798.</p>
<p><seg rend="italic">Señor D. Luis Ferri.</seg></p>
<p>«Mi querido padre:</p>
<p>Después de largo tiempo que ha trascurrido sin
tener noticias de vd. a pesar de las repetidas
cartas que le he escrito, vuelvo otra vez a
dirigirle esta para anunciarle que dentro de poco,
si termino unos asuntos que tengo entre manos, iré
a su lado para recibir su bendición y abrazarlo
con el cariño que sabe le profeso.</p>
</div>
</body>
</floatingText>
</writing>
</said>
410The first example is taken from the novel “Amelia de
Floriani o el castillo del diablo” (1887, AR) by José Victoriano Cabral
and shows a letter that is read aloud by the character D. Luis. The
element <floatingText> is used to mark that the
various paragraphs of the letter, i.e., the dateline, address,
salutation, and the text itself, belong together. In addition, the letter
is marked as written text (<writing type="letter">)
and as direct speech (<said>) because it is read by a
character.
<p>No. No podía ser un contemporáneo, porque sintetizaba demasiado.
Uno de mis camaradas hubiera entrado en mayores detalles, no
hubiera visto las cosas a bulto, hubiera cometido menos errores.
Vean ustedes: aquí tengo el recorte, con su título y todo:</p>
<writing type="newspaper">
<floatingText>
<body>
<div>
<head><seg rend="capital">Divertidas aventuras del
nieto de Juan Moreira</seg></head>
<p>«Tan ignorante y tan dominador como el abuelo, nació
en un rincón de provincia, y creció en él sin
aprender otra cosa que el amor de su persona y la
adoración de sus propios vicios.</p>
[...]
</div>
</body>
</floatingText>
</writing>
<p>Y seguía una larga serie de anécdotas, casi todas falsas —entre
ellas el <q>'envenenamiento'</q> de Camino—, pero tras de cuyas
líneas se transparentaba claramente mi persona, para terminar
diciendo:</p>
<writing type="newspaper">
<floatingText>
<body>
<div>
<p>»El que esto escribe no quiere mal al nieto de Juan
Moreira, ni a don Mauricio Gómez Herrera, ni a...
¡tantos otros! [...]</p>
<p>»¡Que el nieto de Juan Moreira nos represente en
Europa! [...]</p>
</div>
</body>
</floatingText>
</writing>
<p>Y firmaba <writing type="newspaper">«Mauricio Rivas»</writing>.</p>
411The second example includes sections of a newspaper article
that are cited in the novel “Divertidas aventuras del nieto de Juan
Moreira” (1910, AR) by Roberto Payró. Here the text is not read but shown
to the reader by the narrator (“Vean ustedes: aquí tengo el recorte”).
Not the whole newspaper article is represented, but some excerpts that
the narrator comments on. All the parts are marked up as representations
of written text (<writing type="newspaper">), but
only those with a cohesive structure that is more complex as a single
paragraph are marked additionally as floating texts.
412In this corpus, the element <floatingText> is only used for structural reasons. The
classification of the embedded text as a representation of written text,
as direct speech, as a quote, etc. is expressed through elements that are
defined more narrowly semantically, such as <writing>, <said>, <quote>,
and so on, which can all be wrapped around a floating text or be used
independently of it inside of individual paragraphs. Furthermore, the
examples show that the floating texts can both be texts that are embedded
as a whole, as the letter in the novel “Amelia de Floriani”, or partially
and subsequently, as the newspaper article in the novel “Divertidas
aventuras del nieto de Juan Moreira”.
413Overall, encoding the novels in the TEI body served several purposes. Some phenomena were only marked up to keep structural information that existed in the texts’ source files (typographically marked subdivisions of the text and typographically highlighted words or phrases) and to document missing information (gaps). Other structures were marked up because they are of interest for the analysis of subgenres of the novel (verse lines, dramatic text, representations of written text, quotations, and direct speech or thought), and finally, floating texts were marked up to achieve a valid TEI structure. The TEI offers more elements to encode information in literary narrative texts, and more levels of information than the ones chosen here could be useful for genre analysis, so the choices made for this corpus are a selection focusing on the insertion of non-narrative generic forms and on the representation of writing, speech, and thought.
414The encoding of the novels is controlled by a RELAX NG schema,
which in turn is based on a more abstract ODD file.340 The RELAX NG schema makes
sure that the general TEI vocabulary and structure of the corpus are
consistent. It is complemented by a Schematron file that serves to check the
structure and content of the metadata in the TEI header in a more detailed
way (see chapter
3.3.3.1.6 on text classification in the TEI header above). Links to
both schema files are included as processing instructions in each of the
corpus files, as shown in example
37.
<?xml-model
href="../schema/keywords.sch" type="application/xml"
schematypens="http://purl.oclc.org/dsdl/schematron"?>
<?xml-model
href="https://raw.githubusercontent.com/cligs/reference/master/tei/cligs.rng"
type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
415The Schematron file (“keywords.sch”) is corpus specific and is therefore kept inside of the same repository.341 The RELAX NG schema (“clings.rng”) and the underlying ODD file, on the other hand, are designed more generally for all the corpora developed in the CLiGS project and are therefore stored in a separate repository called “reference”.342
416The CLiGS TEI schema includes elements that are basic for the
encoding of literary narrative, dramatic, and poetic texts. However, it
avoids other specialized block-level and inline elements. Its definition was
kept as restrictive as possible, only allowing for elements and attributes
that are actually in use in the different corpora. Compared to other
established TEI customizations such as TEI Lite, TEI Simple, or the
DTA-Basisformat (DTABf), the CLiGS schema is more restrictive, although it
is not an exact subset of either of them. On the other hand, a few
attributes have been added to the schema in the project-specific namespace
“https://cligs.hypotheses.org/ns/cligs” (Schöch et al. 2019, paras 14–18Schöch, Christof, José Calvo Tello, Ulrike
Henny-Krahmer, and Stefanie Popp. 2019. “The CLiGS Textbox: Building and Using
Collections of Literary Texts in Romance Languages Encoded in TEI XML.”
Journal of the Text Encoding Initiative. Rolling Issue. https://doi.org/10.4000/jtei.2085.). In
the main TEI corpus files, the only additional attribute is @cligs:importance, used to assign degrees of importance
to metadata category values, for example, of different subgenre
assignments.343
Second, several custom attributes have been added to the schema to hold
linguistic annotations produced with the NLP package FreeLing.344
417A Python script is used to test the validity of the corpus files against the RELAX NG schema. It produces a log file reporting the success or failure of the validation process for each TEI file.345 Validating the TEI files against the Schematron file requires a different strategy. In principle, Schematron validation is possible with the Python module “lxml”, but only if the queries used in the Schematron file conform to the XSLT 1.0 standard (Behnel 2022Behnel, Stefan. 2022. “Validation with lxml.” lxml – XML and HTML with Python. https://web.archive.org/web/20230611112928/https://lxml.de/validation.html.). To check that the metadata keywords in the TEI header conform to the keyword taxonomy, however, it was necessary to also use XSLT 2.0 expressions in the Schematron file. An alternative way for validation without Python is to compile the Schematron file as XSLT and apply this transformation script to all the TEI files in the corpus using Saxon directly from the command line. The error output of this transformation process is stored in a log file.346
418To summarize this chapter on the encoding of the text corpus, it can be said that this thesis focuses on the encoding of detailed metadata about the novels rather than on a very detailed encoding of the texts themselves. This is due to the kind of resource that the corpus is intended to be: it is an edited text collection aimed to serve as the basis for quantitative genre analysis where metadata about the authors, source editions, the form and content of the texts and, above all, about the subgenres that the novels have been assigned to plays an important role. For the encoding of the textual body, a special emphasis was put on the markup of direct speech in a subset of the novels. In the next section, the assignment of subgenre labels to the novels, which was bypassed in this general chapter about metadata and text encoding, is set out in more detail.
419In principle, the assignment of subgenre labels to the novels in the corpus Conha19 follows the same criteria as the assignment of subgenre labels to the novels contained in the digital bibliography Bib-ACMé, as presented in chapter 3.2.3 above. The same literary-historical sources and bibliographic information were used to collect subgenre labels, the same discursive model to organize them, and the same encoding strategies to express them. In contrast to the novels in the bibliography, however, more information that is relevant to the subgenre assignment is available from the full-text editions of the novels in the corpus. This chapter briefly summarizes the overall encoding of subgenre labels in the corpus files. It focuses on the kind of labels that were only added to the novels in the corpus but not in the bibliography.
420As in Bib-ACMé, also in Conha19, subgenre labels were collected
from a selection of literary-historical sources. On the other hand, explicit
and implicit indications of subgenres in the titles of the novels’ editions
were evaluated. To recapitulate, example 38 shows the subgenre labels that were added to the
bibliographic entry of the novel “Rastaquouère” (1890, ARG) by Alberto del
Solar.
<bibl xml:id="W1234">
<author key="A464">Solar, Alberto del</author>
<title>Rastaquouère</title>
<term type="subgenre.title.explicit">Ilusiones y desengaños sudamericanos
en París</term>
<term type="subgenre.title.implicit" resp="#uhk">novela naturalista</term>
<term type="subgenre.title.implicit" resp="#uhk">novela realista</term>
<term type="subgenre.litHist" resp="#Schlickers_2003">novela naturalista</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela de tendencia mixta</term>
<term type="subgenre.litHist" resp="#Sanchez_1953">novela social</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela naturalista</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela realista</term>
<term type="subgenre.litHist.interp" resp="#uhk">novela social</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">novela social</term>
<term type="subgenre.summary.signal.explicit"
resp="#uhk">novela de costumbres</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">estudio</term>
<term type="subgenre.summary.signal.explicit" resp="#uhk">cuadros</term>
<term type="subgenre.summary.signal.implicit" resp="#uhk">novela naturalista</term>
<term type="subgenre.summary.signal.implicit" resp="#uhk">novela realista</term>
<term type="subgenre.summary.theme.explicit" resp="#uhk"
cligs:importance="2">novela social</term>
<term type="subgenre.summary.theme.explicit"
resp="#uhk">novela de costumbres</term>
<term type="subgenre.summary.theme.litHist" resp="#uhk">novela social</term>
<term type="subgenre.summary.current.implicit" resp="#uhk"
cligs:importance="2">novela naturalista</term>
<term type="subgenre.summary.current.implicit" resp="#uhk">novela realista</term>
<term type="subgenre.summary.current.litHist" resp="#uhk">novela naturalista</term>
<term type="subgenre.summary.current.litHist" resp="#uhk">novela realista</term>
<term type="subgenre.summary.mode.intention.explicit" resp="#uhk">estudio</term>
<term type="subgenre.summary.mode.medium.explicit" resp="#uhk">cuadros</term>
<term type="subgenre.summary.mode.representation.explicit"
resp="#uhk">cuadros</term>
<term type="subgenre.summary.mode.representation.explicit"
resp="#uhk">estudio</term>
<idno type="cligs">nh0255</idno>
[...]
</bibl>
421The novel “Rastaquouère” has the explicit subtitle “Ilusiones y
desengaños sudamericanos en París” (as encoded in the term
"subgenre.title.explicit"), which is interpreted as a sign for a
naturalistic and realist novel ("subgenre.title.implicit"). In
literary-historical works, the novel has been classified as novela
naturalista, novela de tendencia mixta, and novela
social ("subgenre.litHist"). The literary-historical
assignments are interpreted and normalized in terms of the type
"subgenre.litHist.interp". Following this, the different subgenre
label values are summarized to capture values that are signaled in the text
explicitly or implicitly ("subgenre.summary.signal.explicit" and
"subgenre.summary.signal.implicit"). In addition, the values are
summarized to sort them according to the discursive model developed in chapter 3.2.3 above
("subgenre.summary.theme", "subgenre.summary.current",
"subgenre.summary.mode", etc.). In the summarizing part, all
subgenre labels are included, not only the ones derived directly from the title
of the work and from literary histories (as for all bibliographic entries in
Bib-ACMé) but also values that were only collected for the texts in the corpus.
The values “estudio” and “cuadros”, for instance, are added here as a result of
a further examination of generic signals for the novel “Rastaquouère” because
it is part of the text corpus. The origin of these additional subgenre labels
will now be explained.
422For the novels in the corpus, beyond the work title, also other paratextual elements were assessed, including further information on title pages, in dedications, prefaces, headings, or tables of content. All these elements are part of the peritext, i.e., the paratexts that are published together with the work itself. Exceptionally, also information from the epitext, i.e. paratexts outside of the immediate context of the work, was considered, for example, statements about the subgenre of a novel made by contemporaries and published elsewhere. However, this kind of information was not researched systematically. Finally, in cases where no subgenre signals were available from the paratexts, the opening of the novels, typically the first chapter, was evaluated.347 In the TEI files of the corpus, the explicit and implicit generic signals are collected in the keyword section of the TEI header.348 Besides the terms that were already used in the work list of the bibliography Bib-ACMé for the assignment of subgenres, some additional terms are available in the corpus, as listed in table 19.
| Keyword type | Description |
text.genre.subgenre.paratext.explicit |
the subgenre as given explicitly and literally in the paratext of the work (beyond the title) |
text.genre.subgenre.paratext.implicit |
the subgenre as indicated by implicit genre signals in the paratext of the work (beyond the title) |
text.genre.subgenre.contemp.explicit |
the subgenre as given explicitly and literally in statements made by contemporaries |
text.genre.subgenre.opening.interp |
the subgenre as interpreted from genre signals in the opening of the text (e.g., in the first chapter) |
text.genre.subgenre.historical.explicit |
a summary of
text.genre.subgenre.title.explicit,
text.genre.paratext.explicit, and
text.genre.subgenre.contemp.explicit |
text.genre.subgenre.historical.explicit.norm |
a normalized version of the historical subgenre label |
text.genre.subgenre.historical.implicit |
a summary of
text.genre.subgenre.title.implicit,
text.genre.subgenre.paratext.implicit, and
text.genre.subgenre.opening.interp |
423The genre signals that occur in the wider paratext of the work,
i.e., beyond the work’s title, are collected in terms of the type
"text.genre.subgenre.paratext", differentiating between explicit
and implicit signals. Statements made by contemporaries about the subgenre of a
novel are encoded in a term of the type
"text.genre.subgenre.contemp.explicit". Subgenre signals that are
interpreted from the opening of a novel are given in the keyword type
"text.genre.subgenre.opening.interp". In addition, three keywords
of the type "text.genre.subgenre.historical" serve to summarize all
previous explicit and implicit values. All of these terms may occur several
times in the keyword section of a novel’s TEI file. Example 39 represents the encoding of the entirety
of subgenre labels in the corpus file of the novel “Rastaquouère”.
<keywords scheme="../schema/keywords.xml">
[...]
<term type="text.title" n="1890">Rastaquouère. Ilusiones y desengaños
sudamericanos en París</term>
<term type="text.genre.subgenre.title.explicit">Ilusiones y desengaños
sudamericanos en París</term>
<term type="text.genre.subgenre.title.implicit" resp="#uhk">novela
naturalista</term>
<term type="text.genre.subgenre.paratext.explicit">estudio de crítica social</term>
<term type="text.genre.subgenre.paratext.explicit">escritor de costumbres</term>
<term type="text.genre.subgenre.paratext.explicit">pintor de cuadros de
circunstancias</term>
<term type="text.genre.subgenre.paratext.explicit">estudio de las costumbres</term>
<term type="text.genre.subgenre.paratext.explicit">Balzac</term>
<term type="text.genre.subgenre.paratext.explicit">Comedia Humana</term>
<term type="text.genre.subgenre.paratext.implicit" resp="#uhk">novela
realista</term>
<term type="text.genre.subgenre.paratext.implicit" resp="#uhk">novela
de costumbres</term>
<term type="text.genre.subgenre.paratext.implicit" resp="#uhk">novela
naturalista</term>
<term type="text.genre.subgenre.paratext.implicit" resp="#uhk">novela social</term>
<term type="text.genre.subgenre.historical.explicit">Ilusiones y desengaños
sudamericanos en París</term>
<term type="text.genre.subgenre.historical.explicit">estudio de crítica
social</term>
<term type="text.genre.subgenre.historical.explicit">estudio de las
costumbres</term>
<term type="text.genre.subgenre.historical.explicit.norm" resp="#uhk">estudio</term>
<term type="text.genre.subgenre.historical.explicit.norm" resp="#uhk">novela
social</term>
<term type="text.genre.subgenre.historical.explicit.norm" resp="#uhk">novela
de costumbres</term>
<term type="text.genre.subgenre.historical.explicit.norm" resp="#uhk">cuadros</term>
<term type="text.genre.subgenre.historical.implicit" resp="#uhk">novela
naturalista</term>
<term type="text.genre.subgenre.historical.implicit" resp="#uhk">novela
de costumbres</term>
<term type="text.genre.subgenre.historical.implicit" resp="#uhk">novela
realista</term>
<term type="text.genre.subgenre.historical.implicit" resp="#uhk">novela
social</term>
<term type="text.genre.subgenre.litHist" resp="#Schlickers_2003">novela
naturalista</term>
<term type="text.genre.subgenre.litHist" resp="#Sanchez_1953">novela
de tendencia mixta</term>
<term type="text.genre.subgenre.litHist" resp="#Sanchez_1953">novela social</term>
<term type="text.genre.subgenre.litHist.interp" resp="#uhk">novela
naturalista</term>
<term type="text.genre.subgenre.litHist.interp" resp="#uhk">novela
realista</term>
<term type="text.genre.subgenre.litHist.interp" resp="#uhk">novela social</term>
<term type="text.genre.subgenre.summary.signal.explicit"
resp="#uhk">novela social</term>
<term type="text.genre.subgenre.summary.signal.explicit"
resp="#uhk">novela de costumbres</term>
<term type="text.genre.subgenre.summary.signal.explicit" resp="#uhk">estudio</term>
<term type="text.genre.subgenre.summary.signal.explicit" resp="#uhk">cuadros</term>
<term type="text.genre.subgenre.summary.signal.implicit" resp="#uhk">novela
naturalista</term>
<term type="text.genre.subgenre.summary.signal.implicit" resp="#uhk">novela
realista</term>
<term type="text.genre.subgenre.summary.theme.explicit" resp="#uhk"
cligs:importance="2">novela social</term>
<term type="text.genre.subgenre.summary.theme.explicit"
resp="#uhk">novela de costumbres</term>
<term type="text.genre.subgenre.summary.theme.litHist"
resp="#uhk">novela social</term>
<term type="text.genre.subgenre.summary.current.implicit" resp="#uhk"
cligs:importance="2">novela naturalista</term>
<term type="text.genre.subgenre.summary.current.implicit"
resp="#uhk">novela realista</term>
<term type="text.genre.subgenre.summary.current.litHist"
resp="#uhk">novela naturalista</term>
<term type="text.genre.subgenre.summary.current.litHist"
resp="#uhk">novela realista</term>
<term type="text.genre.subgenre.summary.mode.intention.explicit"
resp="#uhk">estudio</term>
<term type="text.genre.subgenre.summary.mode.medium.explicit"
resp="#uhk">cuadros</term>
<term type="text.genre.subgenre.summary.mode.representation.explicit"
resp="#uhk">cuadros</term>
<term type="text.genre.subgenre.summary.mode.representation.explicit"
resp="#uhk">estudio</term>
[...]
</keywords>
424As can be seen, several explicit and implicit subgenre labels stem from the paratext of the novel and are added to the ones derived from the work’s title and from literary-historical works: “estudio de crítica social”, “escritor de costumbres”, “pintor de cuadros de circunstancias”, “estudio de las costumbres”, “Balzac”, “Comedia Humana” as explicit terms and “novela realista”, “novela de costumbres”, “novela naturalista”, and “novela social” as implicit ones interpreted from the paratexts. The explicit values may be all kinds of terms or phrases that carry generic meanings. In this example, there are not only classifications of the work itself (“estudio de crítica social”, “estudio de las costumbres”), but also characterizations of the work’s author (“escritor de costumbres”, “pintor de cuadros de circunstancias”) that imply the subgenre of the novel as well as intertextual references pointing to another author and work that served as a generic model for the novel at hand (“Balzac”, “Comedia Humana”). The values that are interpreted from the explicit terms and phrases correspond to a closed set of subgenre labels, which is based on the overall set of empirical historical subgenre terms found in the bibliography and corpus, as well as on literary-historical knowledge, as documented in chapter 3.2.3 above.
425In the case of “Rastaquouère”, there is an introduction to the
novel in the first edition of 1890, which contains several hints to the generic
frame in which the author sees his work. This introduction is included in the
front matter of the TEI corpus file. Some excerpts containing the generic
signals evaluated in the TEI header keyword section are given in example 40. The signals are
highlighted in curly brackets.
<text>
<front>
[...]
<div type="introduction">
<head>Introducción</head>
<head>El por qué de este libro y su propósito</head> [...]
<p>¿Qué somos los americanos del sud para una gran parte de
los europeos que nos juzgan?</p>
[...]
<p>Unidos por vínculos
de raza y por sentimientos naturales de confraternidad,
forman nuestras colonias sud-americanas en Europa una familia
numerosa y compuesta en su mayor parte de gente conspicua y
respetable, que se esfuerza, con patriótico empeño, en
exhibir allí las prendas y cualidades que más tiendan a hacer
estimables en el extranjero nuestros hábitos, nuestra manera
de ser y nuestras condiciones de sociabilidad y cultura. Pero
sucede a veces que dichas personas tropiezan con el
inconveniente de tener que luchar en el sentido de destruir o
borrar el mal efecto producido por las debilidades, los
candores, las inconveniencias de otros determinados
compatriotas, salidos de algún rincón cualquiera de esta
América lejana, y convertidos, allá en el Viejo Mundo, por
virtud de la expatriación y por las ventajas que les
proporcionan la independencia y la libertad con que viven, en
personajes de valía, en pseudo-notabilidades de su
tierra.</p>
[...]
<p>¿Se prestará, por ventura, el examen de
las costumbres y modos de ser de esas gentes a conclusiones
tan claras y precisas que alcancen a darnos tema para un
estudio de crítica social tan completo como el que
desearíamos ofrecer a nuestros lectores?...</p>
<p>He aquí las preguntas que nos hicimos cuando se nos ocurrió,
por vez primera, la idea de emprender la composición de este
volumen.</p>
<p>La tarea, sobre ser de suyo ardua, se nos presentaba, por
entonces, como escabrosa y compromitente. Todo lo que se
parezca a alusión personal directa, nos decíamos, debe ser
rechazado en absoluto por el escritor de costumbres, llamado
únicamente a censurar lo que crea censurable, a la manera del
pintor de cuadros de circunstancias, que, al hacer el dibujo
de las siluetas que juzga conveniente explotar, se cuida,
ante todo, de no reproducir satíricamente en su lela la
fisonomía de algún prójimo viviente determinado.</p>
[...]
<p>Al intentar llevar a cabo el estudio de las costumbres de
una mínima fracción de ese inmenso todo que se llama la
sociedad — conjunto que tan magistralmente trató,
observándolo en detalle, analizándolo y definiéndolo con
criterio sin igual el ilustre Balzac — hemos pensado que
debíamos seguir, por nuestra parte, las doctrinas del
maestro, y buscar, a nuestra vez, el tema, el medio ambiente
y los personajes de nuestra fábula dentro del gran escenario
del mundo, dentro de la misma vida real, aunque
manteniéndonos forzosamente en una esfera estrecha, que nos
obligaba a no salir de los casos concretos y de las
colectividades sueltas; ya que en el orden social
particularísimo a que estos apuntes se refieren, la verdadera
especie, tal como Balzac la comprendió en su inmortal Comedia
Humana, no existe todavía entre nosotros.</p>
[...]
</div>
</front>
</text>
426In the introduction, the author presents the motivation, aim, and theme of the novel and refers to several generic models. He starts with the question of how South Americans are seen and judged by Europeans when they travel to European countries. From his point of view, his compatriots are, in general, respectable and sociable persons. However, their reputation suffers from a small group of people who give themselves airs as celebrities without being honorable (“personajes de valía”, “pseudo-notabilidades de su tierra”). The title of the novel, “Rastaquouère”, refers to this group of newly rich South Americans who resided in Paris at the end of the nineteenth century.349 The novel aims at studying the customs of this special social group in a detailed critical analysis (“estudio de crítica social tan completo”). Subsequently, the author elaborates on his concept of a novel of customs: in painting his pictures of circumstances (“pintor de cuadros de circunstancias”, “dibujo de las siluetas”) the writer should avoid direct references to his personal surroundings in order to formulate a general critique and not a particular satire. Furthermore, he bases his novel on the model of Balzac’s “La Comédie humaine”, contributing one piece to the superordinate goal of creating a total picture of contemporary society, a project not yet realized in his socio-cultural context. So, on the one hand, the author refers to the Hispanic tradition of the novela de costumbres and, on the other hand, inscribes his novel in the realist and naturalistic (“estudio de crítica social”, “Balzac”, “Comedia Humana”) movements of French origin.
427The example shows that paratextual information can contribute considerably to assessing what subgenres the novels were assigned to historically by their authors, editors, and other contemporaries (in the case of dedications and prefaces written by others). For the whole corpus, it was intended to add at least the front matter of one historical edition to each novel, including the title page and possibly other existing prefatory matters. This was achieved for 231 of the 256 novels.350 In 42 cases, front matters of several different historical editions were added and evaluated as to their generic signals. The front matters need not correspond to the source editions used to extract the full texts of the corpus because the subgenre assignments to the novels are made on the work level and not on the level of the work expression and manifestation.351
428The additional information about the subgenre of a novel that is available through its paratexts varies from case to case. At the one extreme are novels that carry their generic program directly with them. In the edition of 1890, the novel “Ensalada de pollos” (1871, MX) by José Tomás de Cuéllar, for example, is preceded by a prologue sketching the design and purpose of the whole series of “novelas de costumbres mexicanas” called “La linterna mágica”, of which “Ensalada de pollos” is the first part:
QUÉ linterna es esa? [...]
Este título, que bien puede servirle á una tienda mestiza, ¿es una palabra de programa, altisonante y llamativa para anunciar el parto de los montes, ó encierra algo provechoso para el lector? [...]
Yo he copiado á mis personajes á la luz de mi linterna, no en drama fantástico y descomunal, sino en plena comedia humana, en la vida real, sorprendiéndoles en el hogar, en la familia, en el taller, en el campo, en la cárcel, en todas partes [...] he tenido especial cuidado de la corrección en los perfiles del vicio y la virtud: de la manera que cuando el lector, á la luz de mi linterna, ría conmigo, y encuentre el ridículo en los vicios, y en las malas costumbres, ó goce con los modelos de la virtud, habré conquistado un nuevo prosélito de la moral y de la justicia.
Esta es la linterna mágica: no trae costumbres de ultramar, ni brevete de invención; todo es mexicano, todo es nuestro, que es lo que nos importa, y dejando á las princesas rusas, á los dandies y á los reyes en Europa, nos entretendremos con la china, con el lépero, con la polla, con la cómica, con el indio, con el chinaco, con el tendero y con todo lo de acá.
(Cuéllar 1890, vii–xCuéllar, José Tomás de. 1890. “Prólogo.” In Ensalada de pollos. Novela de estos tiempos que corren (1871) tomada del carnet de Facundo (José T. de Cuéllar). Vol. 1 of La linterna mágica. Segunda época. Barcelona: Tipo-Litografía de Hermenegildo Miralles. http://web.archive.org/web/20230128094558/http://cdigital.dgb.uanl.mx/la/1080046422_C/1080046436_T2/1080046436_01.pdf.)
429The “magic lantern” illuminates the characters and the living spaces that the author wants to represent. He aims to “copy” them from real life, avoiding dramatic, fantastic, and incredible effects. At the same time, he sees it as his task to clearly point out vices and virtues, ridiculing the former and elevating the latter, guiding the reader to internalize morality and justice. An important aspect of his program is to bring to light Mexican and not foreign customs and to focus on characters that are social outsiders or belong to the lower classes of society (“china”, “lépero”, “polla”, “cómica”, “indio”, “chinaco”, “tendero”).352 In consequence, all the novels of the series “La linterna mágica” can be assigned the label “novela de costumbre mexicana”.
430On the other hand, there are novels that do not exhibit any clear
subgeneric signals in their paratexts. In these cases, the opening of the
novels was checked for signs pointing to a certain subgenre. The novel “La
Mestiza” (1891, MX) by Eligio Ancona, for example, only carries the subtitle
“Novela original” and is not preceded by any preface or introduction.
Nevertheless, the beginning of the novel is typical for a romantic and
sentimental novel, as the excerpts from the first chapter given in example 41 show.
<div type="chapter">
<head>Capítulo I</head>
<head>La callejuela de San Sebastián</head>
<p>Eran las siete y media de la mañana de un hermoso día de primavera.
La atmósfera estaba limpia de vapores y el bellísimo azul de los
cielos se ostentaba entonces con toda su imponente majestad y
hermosura. [...]</p>
<p>No dejaba de participar de estos beneficios una angosta callejuela
del barrio de San Sebastián, formada por dos hileras de rústicas
albarradas, cuya mala construcción desaparecía en parte bajo un
tapiz de silvestre enredadera. [...]</p>
<p>Acababa de presentarse en la callejuela un joven de veinte a
veinticinco años, de una figura bastante recomendable y simpática,
que venía tarareando distraídamente una canción, como el que trae
demasiado ocupado el pensamiento.</p>
[...]
<p>Ya partía con los
dientes la ciruela más tierna qué había encontrado, cuando
dirigiendo la vista por la centésima vez al lugar que hemos
indicado, vio aparecer al extremo izquierdo de la callejuela el
blanco vestido de una mestiza.</p>
[...]
<p>—¡Dolores! —exclamó el
joven con alegría. </p>
<p>—¡Señor Pablo! —respondió la mestiza. </p>
<p>Y después de este reconocimiento, porque no creemos que merezca
otro nombre, ambos guardaron silencio; el joven contemplaba
ávidamente a Dolores, y Dolores inmóvil junto a él, tenía los ojos
fijos en tierra porque sentía clavadas sobre su semblante las
miradas de fuego de Pablo.</p>
<p>Y Pablo tenía razón en devorar con sus miradas a la mestiza, porque
Dolores era una bellísima criatura.</p>
[...]
</div>
431The first chapter is entitled “The alley of San Sebastián” and begins with a detailed description of the setting, emphasizing the impression that the weather and surroundings, including the vegetation and buildings, have on the observer. Soon the main topic becomes a meeting between the young man Pablo and the mestiza Dolores in the said alley. Both are described as pleasant and beautiful (“un joven de veinticinco años, de una figura bastante recomendable y simpática”, “Dolores era una bellísima criatura”), and the romantic relationship between them is clearly suggested (“el joven contemplaba ávidamente a Dolores”, “Dolores [...] tenía los ojos fijos en tierra porque sentía clavadas sobre su semblante las miradas de fuego de Pablo”). When one reads the first chapter of the novel, a sentimental theme and a romantic style are expected. Here implicit subgenre signals can be located at the beginning of the text, but because of the missing explicit signals, the novel should also be considered as representing the general narrative fiction of its time.
432In this section, the assignment of subgenre labels to the novels in the corpus Conha19 was explained, starting from the strategies that were already used for the assignment of subgenre labels to the novels contained in the bibliography Bib-ACMé. There, series titles, work titles, and subtitles were evaluated regarding explicit mentions and implicit signals. This was done to cover the historical characterization of the novels as representatives of particular subgenres. In addition, literary-historical descriptions of the novels’ subgenres were assessed. For the corpus, further historical textual elements were analyzed for subgenre signals, including paratexts beyond titles and openings of the texts. As a result, a bundle of explicit, implicit, historical, and critical subgenre assignments to the novels is available. It is organized into several levels of an empirical, discursive model of subgenre terms which serves as the basis for analyzing the subgenres in the corpus.
433In the previous sections, the text corpus has been presented in terms of the sources and selection of novels, the treatment of the full texts, the encoding of metadata about the novels and the texts themselves in TEI, as well as the assignment of subgenre labels to the novels. In this final chapter about the corpus, two further aspects are covered: the creation of other corpus formats derived from the TEI and the organization and strategy for the publication of the corpus. Several derivative formats were created to prepare the analysis of the corpus with different tools. One of them, a tokenized version of a subset of the corpus with direct speech annotation, was already presented in chapter 3.3.3.2.8 about the encoding of direct speech and thought. Two other basic derivative formats are a plain text version of the corpus files and a linguistically annotated version. Plain text files are required as an input format for many natural language processing and text analysis tools, and a prepared linguistically annotated version of the corpus allows the use of lexical and grammatical categories in further analyses. More derivative formats can be created in an ad-hoc manner, but it was decided to prepare these two fundamental corpus versions so that they are ready for use in a variety of contexts.
434The corpus created for this dissertation is published for several reasons. Most of the texts are in the public domain,353 which makes it possible to redistribute this part of the corpus freely. Moreover, considerable preparatory work was invested to create this corpus of novels for subgenre analysis, and it is desirable to share it with the research community and general public for reuse in other contexts, not least because also this work builds on previous efforts made by others to edit, digitize and curate the works in question. As the corpus covers a broad time period in the nineteenth and up to the beginning of the twentieth century, works from three different Spanish-American countries, written by many different authors and attributable to a whole range of subgenres of the novel, it can be hoped that there will be other scenarios to use it. Therefore, the TEI master files, schemas, and main derivative formats of the corpus were prepared for research data publication. This subsection serves to first document the creation of the two main derivative corpus formats, followed by an overview of the corpus publication.
435The plain text format is derived from the TEI files with an XSLT
script designed to process a single file. It can be applied to the whole corpus
using the Saxon XSLT processor from the command line (Saxonica n.d.Saxonica. n.d. “Running XSLT from the Command Line.”
Saxonica. XSLT and XQuery Processing. https://web.archive.org/web/20230610171712/https://www.saxonica.com/html/documentation12/using-xsl/commandline/.).354 For the plain text version of a corpus
file, the TEI header, front and back parts are ignored. Also headings of book
parts and chapters are skipped. In case of dramatic speech inside of the
novels, the speaker names are omitted, as well. The text of paragraphs is
copied and separated by blank lines. Groups of verse lines are also separated
by blank lines, but individual verses are only copied with a newline. A snippet
of the plain text version of the first novel in the corpus, “El guajiro” (1842,
CU) by Cirilo Villaverde, is shown in example 42.
[...]
Un ronquido profundo, como el estertor de un agonizante, fue
la única respuesta que obtuvo la enamorada muchacha. Continuaba en
sacudir y pellizcar a la negra; pero la misma voz volvió a dejarse oír
con esta otra décima:
Dices que no hay ocasión
para que hablemos aquí,
donde me temes a mí
y teme tu corazón.
—¡Mentira, mentira! —dijo precipitadamente, sin ser dueña a
contenerse, y como si él pudiera oirla—, yo no te temo a ti, Tatao mío,
ni temo por mí, sino a mi padre, que es duro y tiene el sueño más ligero
que un pájaro. ¡Ay, si te oyese! Si yo pudiera.
El canto la obligó a interrumpirse.
[...]
436For the linguistically annotated version, the tool FreeLing was
used. It is a suite of open-source language analysis tools based on C++ and was
chosen because it includes a comprehensive morphological dictionary for
Spanish, containing over 555,000 forms and over 76,000 lemma-PoS combinations
(Padró and
Stanislovsky 2012Padró, Lluís, and Evgeny Stanislovsky. 2012.
“FreeLing 3.0: Towards Wider Multilinguality.” In Proceedings of the
Language Resources and Evaluation Conference (LREC 2012) ELRA,
2473–2479. Istanbul, Turkey: ELRA. https://web.archive.org/web/20230610172457/http://www.lrec-conf.org/proceedings/lrec2012/pdf/430_Paper.pdf.; Padró
n.d.aPadró, Lluís. n.d.a. “FreeLing Home Page.” https://web.archive.org/web/20230610172727/https://nlp.lsi.upc.edu/freeling/.). FreeLing was used in version 4.0. FreeLing has a front-end
called “analyzer”, which is its main program and was used in client/server mode
to annotate the corpus files (Padró
n.d.e.Padró, Lluís. n.d.e. “Using analyzer Program to Process
Corpora.” FreeLing 4.0 User Manual. https://web.archive.org/web/20230610173731/https://freeling-user-manual.readthedocs.io/en/v4.0/analyzer/.).355 Each call of this program serves to
process one file. A sample command line call to process the first chapter of
the first novel in the corpus is given in example 43.
analyze -f es.cfg --server on --port 50005 --workers 1 --outlv tagged
--sense ukb --nec --output xml & analyzer_client 50005
< /home/ulrike/Git/conha19/txt/nh0001_d1.txt
> /home/ulrike/Git/conha19/tei_annotated/nh0001.xml
437The first line of the call serves to set the default
configuration file for Spanish (-f es.cfg), to establish the
client/server mode (--server on --port 50005 --workers 1), and to
set the options for the linguistic annotation. Here, part-of-speech annotation
(--outlv tagged), sense annotation (--sense ukb),
and named entity classification (--nec) are performed. Finally,
the output format is set to a FreeLing-specific XML format (--output
xml). The second line of the call specifies the input file to be
processed and the path to the output file. An excerpt of the annotation result
in the FreeLing format is shown in example 44.
<sentence id="1">
<token id="t1.1" form="Más_allá_de" lemma="más_allá_de" tag="SP" ctag="SP"
pos="adposition" type="preposition"/>
<token id="t1.2" form="el" lemma="el" tag="DA0MS0" ctag="DA" pos="determiner"
type="article" gen="masculine" num="singular"/>
<token id="t1.3" form="pueblo" lemma="pueblo" tag="NCMS000" ctag="NC" pos="noun"
type="common" gen="masculine" num="singular" wn="07942152-n"/>
<token id="t1.4" form="de" lemma="de" tag="SP" ctag="SP" pos="adposition"
type="preposition"/>
<token id="t1.5" form="San_Diego_de_Núñez" lemma="san_diego_de_núñez" tag="NP00G00"
ctag="NP" pos="noun" type="proper" neclass="location" nec="LOC"/>
<token id="t1.6" form="," lemma="," tag="Fc" ctag="Fc" pos="punctuation"
type="comma"/>
<token id="t1.7" form="en" lemma="en" tag="SP" ctag="SP" pos="adposition"
type="preposition"/>
<token id="t1.8" form="la" lemma="el" tag="DA0FS0" ctag="DA" pos="determiner"
type="article" gen="feminine" num="singular"/>
<token id="t1.9" form="isla" lemma="isla" tag="NCFS000" ctag="NC" pos="noun"
type="common" gen="feminine" num="singular" wn="09316454-n"/>
<token id="t1.10" form="de" lemma="de" tag="SP" ctag="SP" pos="adposition"
type="preposition"/>
<token id="t1.11" form="Cuba" lemma="cuba" tag="NP00G00" ctag="NP" pos="noun"
type="proper" neclass="location" nec="LOC" wn="02795169-n"/>
<token id="t1.12" form="," lemma="," tag="Fc" ctag="Fc" pos="punctuation"
type="comma"/>
<token id="t1.13" form="camino" lemma="camino" tag="NCMS000" ctag="NC" pos="noun"
type="common" gen="masculine" num="singular" wn="00172710-n"/>
<token id="t1.14" form="de" lemma="de" tag="SP" ctag="SP" pos="adposition"
type="preposition"/>
<token id="t1.15" form="Bahía_Honda" lemma="bahía_honda" tag="NP00G00" ctag="NP"
pos="noun" type="proper" neclass="location" nec="LOC"/>
[...]
</sentence>
438Here, the first sentence of the novel’s first chapter is annotated, starting with the phrases “Más allá del pueblo de San Diego de Núñez, en la isla de Cuba, camino de Bahía Honda [...]”. FreeLing marks sentence and token boundaries and attaches the linguistic annotations to the tokens. The tagset for the part-of-speech annotation is based on the EAGLES Recommendations (e.g., “NC” for “common noun” and “NCMNS000” for “common masculine noun in nominative singular”) (Expert Advisory Group on Language Engineering Standards (EAGLES) 1996Expert Advisory Group on Language Engineering Standards (EAGLES). 1996. “EAGLES. Recommendations for the Morphosyntactic Annotation of Corpora.” https://web.archive.org/web/20230610174614/https://home.uni-leipzig.de/burr/Verb/htm/LinkedDocuments/annotate.pdf.; Padró n.d.dPadró, Lluís. n.d.d. “Tagset for Spanish (es).” FreeLing 4.0 User Manual. https://web.archive.org/web/20230610173624/https://freeling-user-manual.readthedocs.io/en/v4.0/tagsets/tagset-es/.). The sense annotation is based on WordNet and results in sense identifiers (e.g., “00172710-n” for the noun “camino”) (Fellbaum 1998Fellbaum, Christiane, ed. 1998. WordNet: An Electronic Lexical Database. Cambridge, MA: MIT Press.; Miller 1995Miller, George A. 1995. “WordNet: A Lexical Database for English.” Communications of the ACM 38 (11): 39–41. https://doi.org/10.1145/219717.219748.; Padró n.d.bPadró, Lluís. n.d.b. “Linguistic Data.” FreeLing Home Page. https://web.archive.org/web/20230610173053/https://nlp.lsi.upc.edu/freeling/index.php/node/12.). The named entity classification differentiates between persons, geographical locations, organizations, and others (e.g., “LOC” for “San Diego de Núñez”). A very useful feature of FreeLing is that it is able to recognize words consisting of several tokens, such as the preposition “más allá de” and the place names “San Diego de Núñez” and “Bahía Honda” in the example (Padró n.d.cPadró, Lluís. n.d.c. “Multiword Recognition Module.” FreeLing 4.0 User Manual. https://web.archive.org/web/20230610173340/https://freeling-user-manual.readthedocs.io/en/v4.0/modules/locutions/.).
439To annotate the whole corpus, the functionality of the FreeLing analyzer program was integrated into an annotation workflow, aiming to produce derivative TEI files keeping the TEI header and basic text structure (parts, chapters, and paragraph-like structures356) of the TEI master files, but replacing the contents with the linguistically annotated text. That way, the structures that were marked up in the texts are still available for analysis in conjunction with linguistic information. On the other hand, if the linguistic annotation had been applied to the entire plain text files of the novels, the structural information would have been lost in the process. Integrating the annotation output directly into the TEI structure required adapting the FreeLing XML output a bit in order to conform to the TEI standard. Furthermore, the FreeLing sense annotation output was enhanced by adding WordNet lexnames to the synset identifiers that were produced by FreeLing itself.357 The annotation workflow was written in Python, including XPath and XSLT calls, and comprises the following steps:358
440The result of this process is shown in example 45.
<div type="chapter">
<p xml:id="nh0001_p1">
<s>
<w cligs:form="Más_allá_de" lemma="más_allá_de" cligs:tag="SP" cligs:ctag="SP"
pos="adposition" type="preposition" cligs:wnsyn="xxx"
cligs:wnlex="xxx">Más_allá_de</w>
<w cligs:form="el" lemma="el" cligs:tag="DA0MS0" cligs:ctag="DA"
pos="determiner" type="article" cligs:gen="masculine" cligs:num="singular"
cligs:wnsyn="xxx" cligs:wnlex="xxx">el</w>
<w cligs:form="pueblo" lemma="pueblo" cligs:tag="NCMS000" cligs:ctag="NC"
pos="noun" type="common" cligs:gen="masculine" cligs:num="singular"
cligs:wnsyn="07942152-n"
cligs:wnlex="noun.group">pueblo</w>
<w cligs:form="de" lemma="de" cligs:tag="SP" cligs:ctag="SP" pos="adposition"
type="preposition" cligs:wnsyn="xxx" cligs:wnlex="xxx">de</w>
<w cligs:form="San_Diego_de_Núñez" lemma="san_diego_de_núñez"
cligs:tag="NP00G00" cligs:ctag="NP" pos="noun" type="proper"
cligs:neclass="location" cligs:nec="LOC"
cligs:wnsyn="xxx" cligs:wnlex="xxx">San_Diego_de_Núñez</w>
[...]
</s>
</p>
</div>
441The example shows that the TEI chapter and paragraph structures
are preserved. Inside paragraphs, <s> elements were
produced, which in turn contain the individual <w> elements
carrying the linguistic information in different attributes. Of the attributes
produced by FreeLing, @lemma, @pos, and @type conform to the TEI standard,
but the others (e.g., @tag, @gen,
or @nec) are not available in TEI and were therefore
attributed to a custom CLiGS namespace, to which also the WordNet-related
attributes @wnsyn and @wnlex were
added.
442As a result, the linguistically annotated derivative format of the corpus can be directly used for analytic purposes, for example, by querying them to calculate the frequencies of specific word categories, lemmas, etc. in the novels. It can also be used to produce other formats of the texts as starting points for further analyses, such as, for example, a text version consisting only of lemma nouns which would be suitable for topic modeling.
443The quality of the part-of-speech (POS) annotation was checked in
one aspect that had been noted during the text treatment and the spell-checking
process as a specific characteristic of Spanish historical texts: the frequency
of verb forms with enclitic pronouns that were not recognized by the
spell-checker, such as, for example, “habíase” instead of “se había” or
“diósela” instead of “se la dio”.359 As a
first step, the list of regular expressions that was prepared to capture such
word forms as exceptions in the spell-checking process was used to detect how
many of these forms occur in the texts of the corpus.360 The results are summarized in figure 33.
444In the figure, the counts of the verb forms with enclitic
pronouns are given relative to the novels’ text length in the number of tokens.
The median is at 0.3 %. The novels with the maximum relative amount have about
1 % of verb forms with enclitic pronouns. There is no clear separation of the
values into two groups which would suggest that the texts of novels with
historical source editions are completely different in this aspect than the
ones of novels based on modern editions. It has to be reminded, though, that
not all of the verb forms with enclitic pronouns are out of use today. They are
still used with infinitive or imperative forms, for example (“hablarnos”,
“dáselo”). As the infinitive forms can be matched unequivocally by single
regular expressions, they were ignored for this analysis, but the imperative
forms are not that easily separated and were kept. In a second step, it was
checked how many verb forms with enclitic pronouns persist as entire tokens in
the FreeLing output. With the standard settings, FreeLing separates the
enclitic pronouns from the verbs and returns two tokens, as shown in example 46, which shows the
annotated phrase “comenzó a hablarnos”.
<w cligs:form="comenzó" lemma="comenzar" cligs:tag="VMIS3S0" cligs:ctag="VMI"
pos="verb" type="main" cligs:mood="indicative" cligs:tense="past" cligs:person="3"
cligs:num="singular" cligs:wnsyn="00348746-v" cligs:wnlex="verb.change">comenzó</w>
<w cligs:form="a" lemma="a" cligs:tag="SP" cligs:ctag="SP" pos="adposition"
type="preposition" cligs:wnsyn="xxx" cligs:wnlex="xxx">a</w>
<w cligs:form="hablar" lemma="hablar" cligs:tag="VMN0000" cligs:ctag="VMN" pos="verb"
type="main" cligs:mood="infinitive" cligs:wnsyn="xxx" cligs:wnlex="xxx">hablar</w>
<w cligs:form="nos" lemma="nos" cligs:tag="PP1CP00" cligs:ctag="PP" pos="pronoun"
type="personal" cligs:person="1" cligs:gen="common" cligs:num="plural"
cligs:wnsyn="xxx" cligs:wnlex="xxx">nos</w>
445However, verb forms that are not recognized because they are no
longer in use are not separated and tend to be misclassified, as the following
example 47 of the phrase
“diósela a Bruno” shows.
<w cligs:form="diósela" lemma="diósela" cligs:tag="NCFS000" cligs:ctag="NC" pos="noun"
type="common" cligs:gen="feminine" cligs:num="singular" cligs:wnsyn="xxx"
cligs:wnlex="xxx">diósela</w>
<w cligs:form="a" lemma="a" cligs:tag="SP" cligs:ctag="SP" pos="adposition"
type="preposition" cligs:wnsyn="xxx" cligs:wnlex="xxx">a</w>
<w cligs:form="Bruno" lemma="bruno" cligs:tag="NP00G00" cligs:ctag="NP" pos="noun"
type="proper" cligs:neclass="location" cligs:nec="LOC" cligs:wnsyn="xxx"
cligs:wnlex="xxx">Bruno</w>
446In the example, the verb form “dió” and the two pronouns “se” and
“la” attached to it are interpreted as a common noun. Because of the way in
which verb forms with enclitic pronouns are usually treated by FreeLing
(separation of verb and pronouns), it was concluded that tokens in the FreeLing
output that still match the regular expressions for verb forms with enclitic
pronouns are misclassifications. These forms were collected, and it was
analyzed to which part of speech they were assigned, as visualized in figure 34.361
447In total, 24,131 forms were found, compared to 80,694 forms that
were found in the non-annotated plain text files of the corpus, which means
that the morphological structure of 70 % of the forms was probably analyzed
correctly by FreeLing. Of the forms that remained, 26 % were analyzed as verbs
and the others as other parts of speech. 56 % were marked as nouns, more than
half of them as proper nouns, and the other part as common nouns. 17 % were
analyzed as adjectives, only 1 % as adverbs, and only one instance each as a
number and an interjection. If almost one-third of the remaining forms were
classified as verbs, why were they not separated into verbs and pronouns
morphologically? A look into the verb matches shows that more than half of them
were recognized as subjunctive forms. In Spanish, imperfect subjunctive forms
can have the same structure as verb forms with the enclitic pronoun “se”. For
example, “hablase” can be used in a context like “no quería que hablase” (“I
did not want him to speak”, verb form in imperfect subjunctive) or “Hablase de
intrigas” (“There is talk of intrigues”, (historical) verb form in present
tense with the enclitic passive pronoun “se”). In the other cases, the tense of
verb forms was not recognized correctly. For example, preterit, imperfect, and
conditional forms with enclitic pronouns were mistaken as indicative present
tense forms (“salióle”, “parecíale”, “faltábale”, “bastaríame”). For the
misclassified verb forms with enclitic pronouns, it was also analyzed how they
are distributed in the novels of the corpus relative to text length in tokens,
as represented in figure 35.
448Here it becomes clear that it is not the number of verb forms with enclitic pronouns, in general, that is very unequally distributed in the novels, but the number of misclassified forms of this type, for which it can be assumed that they are no longer in use. As can be seen, the boxes in the plot have a much smaller variance in the first and second quartiles than in the third and fourth ones. This means that there are many novels with zero or very low misclassifications and another half with higher, varying proportions of them. Such an imbalance in the quality of part-of-speech assignments can potentially have distorting effects on the results of stylistic analyses. For example, verb forms and enclitic pronouns that are not separated are not counted as individual tokens in a bag-of-words approach. Instead, they end up as new items in the vocabulary. The influence of the misclassifications also depends on which kind of word forms are used in an analysis. If one wants to analyze named entities, the verbs with enclitic pronouns classified as proper nouns will permeate the set of entities found. Alternatively, if only nouns are selected, as is often done for topic modeling, again, the verb forms with enclitic pronouns that were classified as common nouns will affect the results.
449As a provisional solution, the set of regular expressions was
used to split the misclassified forms into verbs and pronouns and to correct
the main part-of-speech assignment.362 In the corrected form, the
above-mentioned phrase “diósela a Bruno” looks as shown in example 48.
<w cligs:form="dió" lemma="dió" pos="verb">dió</w>
<w cligs:form="se" lemma="se" pos="pronoun">se</w>
<w cligs:form="la" lemma="la" pos="pronoun">la</w>
<w cligs:form="a" lemma="a" cligs:tag="SP" cligs:ctag="SP" pos="adposition"
type="preposition" cligs:wnsyn="xxx" cligs:wnlex="xxx">a</w>
<w cligs:form="Bruno" lemma="bruno" cligs:tag="NP00G00" cligs:ctag="NP" pos="noun"
type="proper" cligs:neclass="location" cligs:nec="LOC" cligs:wnsyn="xxx"
cligs:wnlex="xxx">Bruno</w>
450As the regular expressions cannot match the verb forms with enclitic pronouns unequivocally in all cases, there can be false positives in this approach. To prevent this as much as possible, a list with exception words was created. To identify the exception words, all the matches of supposedly misclassified verb forms with enclitic pronouns that occurred five times or more often were checked and false positives were added to the exception list.363 Linguistic knowledge is indispensable to find a sustainable and more precise solution. A lexicon of verb forms and rules for the recognition of historical enclitic constructions could be used to improve the linguistic annotation in the first place instead of correcting the output afterward. Nevertheless, the regular expression-based solution works as a first approach to improve the linguistic annotation as a basis for further text analysis.
451The text corpus Conha19 (“Corpus de novelas hispanoamericanas del siglo XIX”) is published in a GitHub repository at https://github.com/cligs/conha19. GitHub is a commercially driven, web-based open platform for source code management and collaborative version control. Because it is a working environment, the corpus can be continued to be curated in the repository and be published in subsequent stable and referenceable releases. The collaborative features of GitHub facilitate other researchers to reuse the corpus by cloning or forking the repository. Comments and suggestions on the corpus can be created as issues. Because this environment alone is not suitable for long-term archiving, the stable corpus releases are additionally stored on Zenodo.org, an archiving service for researchers that is managed by the European OpenAire program and operated by CERN (Nielsen 2013Nielsen, Lars Holm. 2013. “ZENODO - An Innovative Service for Sharing All Research Outputs.” Talk presented at the Joint OpenAIRE/LIBER Workshop, Ghent. http://dx.doi.org/10.5281/zenodo.6815.).364 Publications on Zenodo.org receive Digital Object Identifiers (DOI) so that the corpus releases are identifiable and reachable in the long term. The different components of the corpus publication are listed in table 20.365
| Directory / file name | Description of contents |
|---|---|
| metadata.csv | selected, basic corpus metadata in CSV format |
| tei | TEI master files |
| schema | Taxonomy for metadata keywords, Schematron file for keyword control, validation log files |
| bib | Bibliography file (in TEI) holding full bibliographic references of literary-historical works cited in the corpus files |
| txt | plain text version |
| annotated | linguistically annotated version (in TEI) |
| annotated_corr | linguistically annotated version (in TEI) with corrected POS annotation for verb forms with enclitic pronouns |
| tei_ns | subset of 92 files without direct speech mark-up (in TEI) |
| tei_ds | subset of 92 files with direct speech mark-up only based on regular expressions (in TEI) |
| tei_tokenized_ds | subset of 92 files as tokenized text with two stand-off direct speech annotations (DS_gold versus DS_reg; in TEI) |
| spellcheck | lists with exception words and results of the spell check in CSV format, for the whole corpus and per novel |
452Although the text corpus has been designed specifically for the study of subgenres of nineteenth-century Argentine, Cuban, and Mexican novels, its open publication aims to encourage the reuse of the data in other contexts. As the creation of richly annotated and curated collections of historical, literary texts is labor-intensive, it should be a goal to share the results of this work as far as the legal conditions allow. The corpus at hand could, for example, also be useful for studies concentrating on one of the countries or on individual authors. It could also be integrated into more extensive corpora comprising different genres or a wider chronological range. In addition, the TEI files could serve as starting points for creating digital critical editions of individual novels.
453From the point of view of quantitative digital literary studies, with its 256 novels, Conha19 can be considered a corpus of medium size, lying somewhere between small-scale text collections for stylometric studies and the “million volumes” analyzed by Underwood (Underwood 2015b, 2–3Underwood, Ted. 2015b. Understanding Genre in a Collection of a Million Volumes. White Paper Report. Urbana-Champaign: University of Illinois. http://dx.doi.org/10.17613/M6W07V. ). The medium size of the corpus made it possible to add detailed metadata and structural markup to the texts. On the other hand, the size of the corpus made it necessary to rely on an automatic orthography check to assess the quality of the full texts. Moreover, in this medium-sized corpus, not only canonical works are included but also lesser-known ones. Furthermore, the corpus is new in this composition and was not retrieved from one source but from a whole range of different source institutions. It was also built from different types of source editions (historical and modern, scholarly as well as general ones). Finally, also the range of subgenres included in the corpus is broad, and the number of different authors is considerably high. In the following section, overviews of the corpus’ contents are given from various perspectives. They are compared to the works included in the digital bibliography Bib-ACMé to estimate how the distribution of novels in the corpus relates to the overall production of novels of the time in the three countries in question.