454Before the novels are analyzed by subgenre textually, the data contained in the digital bibliography and the text corpus are analyzed on a metadata level in this chapter. One goal of this analysis is to provide a general overview of the contents in both databases: how many novels are there in the reference bibliography (of which subgenre, written by which authors, published in which of the three countries and when)? How many novels are there in the corpus, and is the corpus similarly structured in quantitative terms, or are there differences between both resources? Furthermore, the quantities of novels by subgenre in the corpus are assessed to find out which groups are big enough to carry out a quantitative text analysis. A choice is then made for two discursive levels (thematic subgenres and literary currents) and a specific set of subgenre labels (the primary labels on these two levels) to analyze the novels further in the text analysis part. When the numbers of novels in the bibliography and corpus are compared, and differences are observed, these are mainly described in qualitative terms, which means that the numbers are interpreted and set in relation to each other. However, statistical tests for significance are only done in the case of the novels’ text length. On the level of the metadata categories, most of the groups are quite small, so most differences are not expected to be significant in a statistical sense. Nonetheless, they show how specific subsets of the bibliography and corpus proportionally vary.
455When analyzing the subgenres in a corpus of novels, an important question is to what extent the results can be interpreted as statements about the subgenres in question and not only about the selected novels in the corpus, that is, how far they are generalizable. The search for an answer to this question involves determining the representativeness of the corpus. Assuming that the corpus does not consist of the entire literary production, to which degree does it represent it? How to capture “the entire literary production”?
456For linguistic corpora, questions of representativeness in corpus design have been addressed by Douglas Biber, in particular (Biber 1993aBiber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.). As he formulates, “[r]epresentativeness refers to the extent to which a sample includes the full range of variability in a population” (Biber 1993a, 243Biber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.). Two important terms are introduced here: the population as a whole, such as the entire production of a spoken or written language or the entire literary production, and the sample as a selected section of the population. Biber states that the assessment of the representativeness of a sample depends first on a prior definition of the population and second on the sampling technique used to make selections from it. He mentions two important aspects for the definition of the population: “(1) the boundaries of the population—what texts are included and excluded from the population; (2) hierarchical organization within the population—what text categories are included in the population, and what are their definitions” (Biber 1993a, 243Biber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.).
457The population of this corpus has been defined in chapter 3.1 on selection criteria, making use specifically of the first aspect. The “Boundaries of the Novel” (3.1.1) specified what kind of texts are included (novels) and how this generic kind is defined and delimited in the current context. Furthermore, the population was situated cultural-geographically and chronologically by discussing the “Borders of Argentina, Cuba, and Mexico” (3.1.2) and the “Limits of the Nineteenth Century” (3.1.3). On the other hand, regarding the second aspect, no restrictions were made for the internal organization of the population in terms of types of subgenres. No specific subgenres were set or excluded. However, the population is internally organized into works from the three countries.
458The definition of a population is, first of all, theoretical work because it does not mean it would be possible to have complete access to it. An operational definition of the population is needed, which is called “sampling frame” by Biber: “an itemized listing of population members from which a representative sample can be chosen” (Biber 1993a, 244Biber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.). The sampling frame for the corpus Conha19 is the bibliography Bib-ACMé (see chapter 3.2), to which the population’s selection criteria were applied and the sources of which were presented in chapter 3.2.1.
459Biber describes several sampling strategies. Probabilistic sampling relies on random selection and can, for example, be realized as a simple random sampling, where all items have the same chance to be selected. Another variant of probabilistic sampling is stratified sampling, which makes use of subgroups in the population and applies random sampling to each subgroup in a second step (Biber 1993a, 244Biber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.). For the creation of the corpus Conha19, no formal random sampling was applied, neither general nor stratified, because the selection of texts from the bibliography was restricted to the texts actually available in digital format or a format suitable for digitization. So in this case the availability of the sources had a strong influence on the resulting sample. Nevertheless, in an informal procedure, the texts were selected in a way to ensure a balance of countries, authors, and major subgenres as far as possible.
460One way to evaluate representativeness is by looking at the sample size. Which overall proportion of the population is contained in the sample? However, the aspect of how much of the population’s variability is included is considered even more important by Biber. In the context of linguistic corpora, he finds that
variability can be considered from situational and from linguistic perspectives, and both of these are important in determining representativeness. Thus a corpus design can be evaluated for the extent to which it includes: (1) the range of text types in a language, and (2) the range of linguistic distributions in a language. (Biber 1993a, 243Biber, Douglas. 1993a. “Representativeness in Corpus Design.” Literary and Linguistic Computing 8 (4): 243–257. https://web.archive.org/web/20230128095417/http://otipl.philol.msu.ru/media/biber930.pdf.)
461It is very clear that this view on variability is specifically linguistic: text types are bound to communicative situations, and the relevant text-internal features are linguistic distributions. For a literary corpus, corresponding requirements could be formulated in the following way:
462If genres are understood as external attributions to the texts in question, then the first, third and fourth factors are external, while the second one depends on the internal characteristics of the texts. However, using the second criterion to determine the internal variability of a literary corpus is not straightforward. More research is available on the range of linguistic distributions in languages than on textual distributions in literature.367 First of all, it would be necessary to determine what kind of textual distributions are relevant. Distributions of linguistic features in literary texts? Or distributions of specifically literary features? If the latter, which kind of features would these be? If the “literature” in this case is “the novel”, it would be necessary to have general knowledge about textual distributions in novels. To give examples, this could be knowledge about the typical range in the amount of direct speech in novels or knowledge about the typical distribution of topics in novels.368 As things now stand, though, knowledge about such textual distributions in literary texts is rather still the aim of digital literary studies than a fund of basic knowledge to which one could refer. Therefore, the second point is not used here to evaluate the representativeness of the corpus. Instead, the sampling frame Bib-ACMé and the sample Conha19 are compared on several levels that are derived from the metadata encoded for both: the authors (in chapter 4.1.2), works (4.1.3), editions (4.1.4), and subgenres (4.1.5) covered. Both the sample size and its relative variability in relation to the sampling frame are assessed.
463In addition, specific overviews are given for the works in Conha19 (in 4.1.3.2) for features available for the corpus but not for the whole bibliography. These are specific metadata such as the novels’ narrative perspective or status as high- or low-prestige literature, but also characteristics derived from the full texts themselves, such as their length. These overviews thus offer a more descriptive perspective on the corpus. They are nonetheless important because they highlight specific characteristics of the corpus that influence later analyses. This allows for assessing what is typical for the whole corpus and what is a specific result in a particular analysis. Nevertheless, when interpreting the corpus-specific overviews, it must be remembered that these distributions have not been checked against a sampling frame. They are properties of the corpus and do not necessarily allow for generalizations about the novel that the corpus aims to represent.
464Besides the factors of authorship and genre and the work and edition levels, in the overviews, also the chronological aspect is covered. On the one hand, distributions over the years and decades are used to get a sense of the overall production of novels over time and how it is proportionally reflected in the corpus. On the other hand, the question arises of how Bib-ACMé and Conha19 are organized in terms of literary periods. In chapter 3.1.3 above, the chronological limits for the whole bibliography and corpus were set to 1830 and 1910, including the first national literary productions and delimiting the corpus from new avantgardistic literary currents arising in the twentieth century. However, during this long nineteenth century, several different literary currents played a major role in Spanish-American novels, particularly Romanticism, Realism, Naturalism, and Modernism. A non-trivial question is how to map these different currents to chronological periods that would allow comparing their relative coverage in the bibliography and the corpus. As Varela Jácome explains, different literary currents of European provenance reached Spanish America with delay and also simultaneously. As a consequence, there are chronological overlaps of works that can be attributed to the different currents and also works that draw their aesthetic influence from several currents at once (Varela Jácome [1982] 2000, sec. 1.1.3, 1.4.1., 2Varela Jácome, Benito. (1982) 2000. Evolución de la novela hispanoamericana en el siglo XIX (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmct14z8.). Nonetheless, he sees a clear breakthrough of Realism in the 1880s (sec. 3Varela Jácome, Benito. (1982) 2000. Evolución de la novela hispanoamericana en el siglo XIX (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmct14z8.). Rössner also describes the year 1880 as the beginning of a phase that was marked by significant changes in the social and economic life of all the Spanish-American countries, which led to the development of the Modernismo current (Rössner 2007, 200Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.). Without deciding on clear chronological limits for the various literary currents of the nineteenth century and without needing to establish a temporal sequence of currents, the year 1880 will be used as a cutting point here to see how many works were published before and after that year both in the bibliography and the corpus.
465An aspect that is not relevant for the sampling procedure here and hence also not for the evaluation of representativeness is sampling within the texts themselves. Only whole novels are included in the corpus and not, for example, selected subchapters or randomly selected text snippets of a certain size. As Gemeinböck points out in her study on “Representativeness in Corpora of Literary Texts”, to use extracts of prose fiction is not advisable because, for example, beginnings and endings of the texts would differ considerably. The loss of information about entire text sections is to be considered more problematic than texts of different length (Gemeinböck 2016, 36Gemeinböck, Iris. 2016. “Representativeness in corpora of literary texts: introducing the C18P project.” MATLIT: Materialidades da Literatura 4 (2): 29–48. https://doi.org/10.14195/2182-8830_4-2_2.).
466Technically, the overviews in the following sections entirely draw on information that is encoded in XML-TEI. Therefore, an XSLT script was used for the calculations and to generate the visualizations.369 With XSLT, also complex structures can be easily assessed, for example, exact publication dates versus ranges or relationships between publication dates of editions and the biographical data of authors.
467Three points are important when interpreting the numbers in the following overviews. First, only authors, works, and editions contained in Bib-ACMé and Conha19 are considered without claiming completeness. The sources of both the bibliography the corpus were presented in chapters 3.2.1 and 3.3.1 above, respectively. There are probably more authors, works, and above all, more editions that would have been eligible according to the selection criteria. They are, however, not captured because they were not included in the sources selected to create the databases.
468Second, there are more authors, works, and editions in the context of the bibliography and the corpus that were not included because they did not correspond to the selection criteria. For example, an author that is part of the corpus may have published more works after 1910 that are not represented here. So the following overviews concentrate on the authors, works, and editions selected for the purpose of this study but they do not represent the entire literary field.
469Third, in the TEI files of the bibliography and the corpus, there are metadata values that are marked with degrees of certainty. The nationality of an author, for example, may have been assigned with low certainty if it was implied from source information but could not be verified, for instance, by an entry in an authority file. Such values with lesser degrees of certainty are not reflected in the overviews but are counted in as if they were certain. Then again, there are also completely unknown metadata values. Their number in turn is mentioned or included in the overview figures.
470The analysis of the metadata on the bibliography and the corpus has produced many overview graphs since the two resources have been studied from many different perspectives to paint as comprehensive a picture as possible of their characteristics. In order to still keep the text in this chapter readable, it was decided to describe the results in the text but to outsource the actual graphs, which can be found in the appendix to this dissertation (“Appendix of Figures”).
471In the bibliography, 829 works by 383 different authors are included. The corpus contains 256 works by 121 different authors, which corresponds to 31 % of the overall number of works and 32 % of the overall number of authors.370 The mean number of works per author is 2.2 in the bibliography and 2.1 in the corpus. The numbers show that little less than one-third of the novels and authors in the bibliography are part of the text corpus.371
472The majority of authors (230, 60 %) in the bibliography wrote just one novel. 130 authors (34 %) wrote two to five novels, and 23 authors (6 %) more than five novels. In the corpus, most authors are also represented with just one novel (67 authors, i.e., 55 %). There are 47 authors (39 %) with two to five novels in the corpus and 7 authors (6 %) with more than five novels. Comparing the bibliography and the corpus, the number of authors with only one novel is a little bit lower in the corpus, whereas the number of authors with two to five novels is a bit higher. However, all in all, the proportions of the number of works per author are similar. The most productive authors in the bibliography and the authors with the most novels included in the corpus are listed in table 21.372 Authors who only occur at the top ranks of the bibliography but not of the corpus are marked in blue, and those who only appear at the top of the corpus but not the bibliography are in orange.
| Bib-ACMé | Conha19 | |||||
|---|---|---|---|---|---|---|
| Author name | Country | Novels | Author name | Country | Novels | |
| 1 | Gutiérrez, Eduardo | AR | 34 | Cuéllar, José Tomás de | MX | 9 |
| 2 | Olavarría y Ferrari, Enrique | MX | 22 | Gutiérrez, Eduardo | AR | |
| 3 | Paz, Ireneo | MX | 17 | Gamboa, Federico | MX | 8 |
| 4 | Mateos, Juan Antonio | MX | 14 | Ocantos, Carlos María | AR | |
| 5 | Ocantos, Carlos María | AR | 13 | Gómez de Avellaneda, Gertrudis | CU | 7 |
| 6 | Auber de Noya, Virginia Felicia | CU | 11 | Calcagno, Francisco | CU | 6 |
| 7 | Puig y de la Puente, Francisco | CU | Paz, Ireneo | MX | ||
| 8 | Cuéllar, José Tomás de | MX | 10 | Altamirano, Ignacio Manuel | MX | 5 |
| 9 | Rivera y Río, José | MX | Ancona, Eligio | MX | ||
| 10 | Salado Álvarez, Victoriano | MX | Holmberg, Eduardo Ladislao | AR | ||
| 11 | Gamboa, Federico | MX | 8 | Sicardi, Francisco | AR | |
| 12 | Gómez de Avellaneda, Gertrudis | CU | Villaverde, Cirilo | CU | ||
| 13 | Guerrero y Pallarés, Teodoro | CU | Cambaceres, Eugenio | AR | 4 | |
| 14 | Calcagno, Francisco | CU | 7 | Castera Cortés, Pedro | MX | |
| 15 | Guillo, Francisco | AR | Delgado, Rafael | MX | ||
| 16 | Güell y Renté, José | CU | Gorriti, Juana Manuela | AR | ||
| 17 | Iglesia, Álvaro de la | CU | Mateos, Juan Antonio | MX | ||
| 18 | Riva Palacio, Vicente | MX | Meza, Ramón | CU | ||
| 19 | Ancona, Eligio | MX | 6 | Rabasa, Emilio | MX | |
| 20 | Gorriti, Juana Manuela | AR | Riva Palacio, Vicente | MX | ||
| 21 | Holmberg, Eduardo Ladislao | AR | Sánchez Mármol, Manuel | MX | ||
473In the bibliography, the most productive author is the Argentine Eduardo Gutiérrez, who is responsible for 34 novels and who wrote many popular crime and gaucho novels. He is followed by the Mexican author of historical novels Enrique Olavarría y Ferrari with 22 works, and Ireneo Paz with 17 works, a Mexican author who wrote historical as well as sentimental novels. More authors mainly dedicated to historical novels are part of the top positions in the bibliography: Juan Antonio Mateos with 14, Victoriano Salado Álvarez with 10, Francisco Guillo and Vicente Riva Palacio with 7, and Eligio Ancona with 6 novels. Among the other authors in the top list of Bib-ACMé are the Argentine writer of Realist novels Carlos María Ocantos with 13 works, the Mexican Naturalist Federico Gamboa with 8 novels, and the Mexican writer of novelas de costumbres José Tomás de Cuéllar with 10 novels, who are all well-known. On the other hand, there are some lesser-known authors of mainly sentimental and romantic novels who were very productive in their time: the Cuban authors Virginia Felicia Auber de Noya, Francisco Puig y de la Puente (11 novels each), Teodoro Guerrero y Pallarés (8 novels), José Güell y Renté, and Álvaro de la Iglesia (7 novels each), as well as the Mexican writer José Rivera y Río (10 novels). Together with both lesser-known authors of historical novels Enrique Olavarría y Ferrari and Victoriano Salado Álvarez, all of them are highlighted in blue and thus not part of the top list of the corpus.
474In Conha19, the authors who are represented with the most novels (9 each) are again Eduardo Gutiérrez and the Mexican writer of novelas de costumbres José Tomás de Cuéllar. They are directly followed by Federico Gamboa and Carlos María Ocantos with 8 novels each, and the famous Cuban writer Gertrudis Gómez de Avellaneda with 7 novels, who ranges a bit lower in the top list of Bib-ACMé. Authors that entered the top list of the corpus but not of the bibliography are the Mexicans Ignacio Manuel Altamirano (5 novels), Pedro Castera, Rafael Delgado, Emilio Rabasa, and Manuel Sánchez Mármol (4 novels each), the Argentine authors Francisco Sicardi (5 novels) and Eugenio Cambaceres (4 novels), and the Cuban authors Cirilo Villaverde (5 novels) and Ramón Meza (4 novels). Except for Sicardi and Sánchez Mármol, these are all well-known authors who entered the general literary-historical canon of the countries in question. Sicardi reaches a top place because he wrote a cycle of five novels called “Libro extraño”, which is completely included in the corpus, and Sánchez Mármol because there is a recent edition of his complete works, including novels, from 2011 (Sánchez Mármol 2011Sánchez Mármol, Manuel. 2011. Obras completas I: novelas. Edited by Manuel Sol. Colección Manuel Sánchez Mármol. Villahermosa: Universidad Juárez Autónoma de Tabasco.).
475The comparison of the top productive authors in the bibliography and the corpus shows that 12 of the 21 authors occur in both lists, which is a bit more than half of them. Moreover, some differences become visible: in the bibliography, many of the writers who wrote much did so in specific subgenres of the novel. In addition, some lesser-known authors are prolific writers. On the other side, in the top list of the corpus, well-known canonical authors play a more important role, and specific subgenres are a little less important. This has very practical reasons: the corpus is built as much as possible on novels that were available in a digital full-text format and to date, there are more such digital editions of works written by the more prominent authors.
476How does the picture change if not the number of works but the number of editions per author is considered? The number of historical editions373 that have been published of an author’s works is not so much a sign of productivity but of success, be it because the works were valued highly by contemporaries or read much.374
477Most authors in the bibliography have only published one edition (191 authors, i.e., 50 %). 148 authors (39 %) published two to five editions, and 44 (11 %) authors more than five editions. In the corpus, 41 authors (34 % of all the authors in the corpus) are represented with one edition, 54 authors (45 %) with two to five, and 26 authors (21 %) with more than five editions. If one compares the proportion of authors represented with a certain number of editions in Conha19 and Bib-ACMé, the numbers show that the corpus contains fewer authors with only one edition, a bit more with two to five editions, and considerably more with more than five editions. The numbers of editions indicate that the works contained in the corpus were, on average, republished more often than the works in the bibliography. All in all, the authors in the corpus were more popular, more successful, or had more prestige than the average author in general. This observation is in line with the above finding that the authors represented with most works in the corpus are the ones that are more known and more canonized. The same picture emerges when looking at the list of authors with most editions in Bib-ACMé and Conha19, represented in table 22.375
| Bib-ACMé | Conha19 | |||||
|---|---|---|---|---|---|---|
| Author name | Country | Novels | Author name | Country | Novels | |
| 1 | Gutiérrez, Eduardo | AR | 89 | Gutiérrez, Eduardo | AR | 29 |
| 2 | Olavarría y Ferrari, Enrique | MX | 41 | Gómez de Avellaneda, Gertrudis | CU | 24 |
| 3 | Gómez de Avellaneda, Gertrudis | CU | 25 | Altamirano, Ignacio Manuel | MX | 17 |
| 4 | Mateos, Juan Antonio | MX | Cuéllar, José Tomás de | MX | 16 | |
| 5 | Paz, Ireneo | MX | Gamboa, Federico | MX | 15 | |
| 6 | Puig y de la Puente, Francisco | CU | 20 | Mateos, Juan Antonio | MX | 13 |
| 7 | Cuéllar, José Tomás de | MX | 18 | Riva Palacio, Vicente | MX | 12 |
| 8 | Altamirano, Ignacio Manuel | MX | 17 | Villaverde, Cirilo | CU | |
| 9 | Ocantos, Carlos María | AR | 16 | Díaz Covarrubias, Juan | MX | 11 |
| 10 | Riva Palacio, Vicente | MX | Calcagno, Francisco | CU | 10 | |
| 11 | Gamboa, Federico | MX | 15 | Delgado, Rafael | MX | |
| 12 | Guerrero y Pallarés, Teodoro | CU | Mármol, José | AR | ||
| 13 | Rivera y Río, José | MX | 14 | Ocantos, Carlos María | AR | |
| 14 | Villaverde, Cirilo | CU | 13 | Cambaceres, Eugenio | AR | 9 |
| 15 | Auber de Noya, Virginia Felicia | CU | 11 | Paz, Ireneo | MX | 9 |
| 16 | Calcagno, Francisco | CU | Sicardi, Francisco | AR | 9 | |
| 17 | Delgado, Rafael | MX | Castera Cortés, Pedro | MX | 8 | |
| 18 | Díaz Covarrubias, Juan | MX | Guerrero y Pallarés, Teodoro | CU | 8 | |
| 19 | Holmberg, Eduardo Ladislao | AR | Holmberg, Eduardo Ladislao | AR | 8 | |
| 20 | Gorriti, Juana Manuela | AR | 10 | Payno, Manuel | MX | 8 |
478Compared to the list of authors with the most works, the top lists of the authors with the most editions differ less between the bibliography and the corpus. Only five authors instead of nine are not contained in the other list, respectively. This is because, by the number of editions, more of the well-known and successful authors enter the bibliography list, although they are not the ones that wrote most works. These are the Mexicans Ignacio Manuel Altamirano and Rafael Delgado and the Cuban author Cirilo Villaverde. Authors that newly enter the corpus top list are the Argentine José Mármol, the Mexican Manuel Payno, and the Cuban author Teodoro Guerrero y Pallaŕes. José Mármol is famous for just one novel, “Amalia”, which was very successful. Manuel Payno published three works, two of which were successes (“El fistol del diablo” and “Los bandidos de Río Frío”) and re-edited in his time. Teodoro Guerrero y Pallarés enters the list because he wrote many novels, of which several were published with more than one edition, especially “Anatomía del corazón”. New to both top lists is the Mexican Juan Díaz Covarrubias, author of three novels that were all re-edited. So in terms of quantity, the field of top authors shifts when considering the number of editions instead of the number of works, bringing the bibliography and the corpus closer together.
479Other important points to present about the authors in Bib-ACMé and Conha19 are their provenance, nationality, and belonging to a certain country because both resources include authors from Argentina, Cuba, and Mexico.376
480In Bib-ACMé, most authors are associated with Mexico, followed by Argentina. In Conha19, in contrast, there are more authors belonging to Argentina than to Mexico. However, the numbers for these two countries range between 37 and 46 %, so the difference is not too big. In both cases, there are fewer authors that are connected to Cuba, 14 % in the bibliography and 20 % in the corpus, meaning that Cuban authors are a bit overrepresented in the latter.
481The division into three countries is a simplification because authors were assigned to the countries based on several different criteria. They can, for example, have the nationality of the country, either because they were born there or naturalized at some point, or they are considered as belonging to the country because it was their primary place of residence and work and they published their novels there. A closer look into the nationalities, birth, and death places shows that also other countries beyond Argentina, Cuba, and Mexico are involved.377
482By nationality, most authors are Mexican, Argentina, and Cuban in the bibliography, and Argentine, Mexican, and Cuban in the corpus. Besides that, also authors with Spanish nationality play a role in both contexts. In the corpus, further nationalities are only represented by one author each (Chilean, Dominican, French, and Uruguayan). The nationality of one author in the corpus is unknown (C. M. Blanco, whose novel “Salvaje. Novela argentina” was published in Barcelona and Buenos Aires in 1891). In the bibliography, there are seven authors with Uruguayan nationality, two each with Chilean, Dominican, and French nationality, and further nationalities represented with just one author. In Bib-ACMé, the nationality of seven authors is unknown. Altogether, twelve different nationalities are involved.
483The picture is different when the authors’ countries of birth are considered. For most authors in the bibliography (44 %), the place of birth could not be verified. Otherwise, most authors included in Bib-ACMé are born in Mexico, followed by Argentina, Cuba, and then Spain and Uruguay. Interestingly, the proportion of authors born in Argentina (12 %) is only slightly higher than the proportion of authors born in Cuba (10 %). However, more authors were associated with Argentina because they were included in the source bibliographies, especially the comprehensive bibliography of the Argentine novel by Lichtblau, and because their works were published in Argentina, but there is not much knowledge about many of these authors. In the corpus, the order of countries of birth is the same as in the bibliography (Mexico, Argentina, Cuba, Spain, Uruguay), but the proportion of authors with unknown countries of birth is much less (13 %). This again illustrates that the corpus authors are mainly well-known writers or at least that their share is bigger than in the bibliography.
484The country of death is also unknown for most authors in the bibliography (48 %), followed by Mexico, Argentina, Cuba, and Spain. A country that gains a bit more relevance as a place of death is the USA, where six authors died. These are authors born in Cuba, Mexico, and the Dominican Republic. In the corpus, again, the place of death is known for many more authors (it is unknown for only 14 %). Besides that, the proportion of authors who died in Argentina and Mexico is equal, followed by Cuba, Spain, and the USA, where four of the authors died. The overviews of the relationships between authors and countries make clear that the Argentine, Cuban, and Mexican literatures, as understood in the context of this study, are not fixed and closed spaces, but that connections to other countries exist, as is probably the case for all “national” literatures.
485Another topic is the gender of the authors. In the bibliography, the great majority is male (353 authors, i.e., 92 %), and there are only 23 (6 %) female authors. In 7 cases (2 %), the gender of the author is unknown. In the corpus, the proportion of female authors is a bit higher (11 authors, i.e., 9 %), and there is only one author whose gender is unknown (the author of the novel “Salvaje”, called “C. M. Blanco”).378
486It is not only of interest to know how many authors of a particular gender there are but also for how many of the works they are responsible. In the bibliography, 756 works (91 %) are written by male authors, 58 works (7 %) by female authors, and 15 works (2 %) by authors of unknown gender. In the corpus, 229 novels (89 %) are written by male authors, 26 novels (10 %) by female authors, and one novel by an author of unknown gender. If one compares these numbers to the number of authors in general, it can be noted that, on average, female authors are slightly more productive than male authors.
487Finally, also the life dates are of interest to get a sense of which authors are included in the bibliography and the corpus. Unfortunately, they could only be verified for a subset of the authors.379
488The complete life dates, i.e., the years of birth and death, are only known for 63 % of the authors in the bibliography and for 88 % of the authors in the corpus. No life dates at all are known for 33 % of the authors in the bibliography and 8 % in the corpus. For 4 % of the authors in Bib-ACMé and 3 % in Conha19, only the year of birth or death is known. That much more is known about the life dates of the authors in the corpus than in the bibliography again shows that the latter covers more of the less canonized literary production. This state of knowledge has to be kept in mind for the following overviews, in which life dates are used to calculate how many authors were alive or active at a certain point in time and how old they were when they published their works.380
489In the bibliography, the first author was born in 1776. This is the Mexican José Joaquín Fernández de Lizardi. He was also the first author who died (in 1827). Lizardi is often considered the author of the first Mexican or even Spanish-American novel “El Periquillo Sarniento” (1816, MX). On the other hand, his novels are also described as forerunners of the nineteenth-century Spanish-American novel proper (Alegría 1959, 18–26Alegría, Fernando. 1959. Breve historia de la novela hispanoamericana. México: Ed. de Andrea.; Janik 2008, 34–36Janik, Dieter. 2008. Hispanoamerikanische Literaturen. Von der Unabhängigkeit bis zu den Avantgarden (1810–1930). Tübingen: Narr Francke Attempto.; Sánchez 1953, 111, 115–123Sánchez, Luis Alberto. 1953. Proceso y contenido de la novela hispano-americana. Madrid: Editorial Gredos.). Because its publication date lies outside the scope of this study, the novel “El Periquillo Sarniento” is not included here. In the bibliography, Lizardi is only represented with the novel “Don Catrín de la Fachenda”, which was first published posthumously in 1832 but is also not included in the corpus. The next author, included in both the bibliography and the corpus, is the Cuban Esteban Pichardo y Tapia, born in 1799. In the following decades, the number of births increases considerably. More than half of the authors in the bibliography and the corpus whose birth dates are known were born between the 1830s and the 1860s. The last authors were born in the 1880s. One of them is part of the corpus: the Argentine Enrique García Velloso, who was born in 1880. Considering the years of death, after Lizardi, the first authors died in the 1850s, and the last ones in the 1960s. The first author in the corpus who died was Juan Díaz Covarrubias, a Mexican writer who died in 1859 at the age of 21 in the civil war of the Reform (Yin 1992, 195Yin, Filippa B. 1992. “Díaz Covarrubias, Juan.” In Dictionary of Mexican Literature, edited by Eladio Cortés, 195–196. Westport, Connecticut; London: Greenwood Press.), and the last one was the Argentine Enrique Larreta, who died in 1960. Most authors died in the 1890s, 1910s, and 1920s. Without detailed biographic research, it cannot be said with certainty why there were fewer deaths in the 1900s than in the preceding decade and the following two decades. It may have had an influence that the 1900s were a politically and economically more stable decade than the others. All in all, the life dates of the authors comprise 190 years, from the 1770s to the 1960s, for a bibliography and corpus that is limited to 80 years. In such a broad range, several generations of authors are involved, and not all the authors experienced the same historical times. Nevertheless, there is a core of contemporaneity. Between the 1850s and the 1910s, more than half of the authors for whom birth and death dates are known were alive.381
490Another question is when these authors were not only alive but also active. “Activity” is interpreted here as the phase when the authors published new works, i.e., the years in which they actually published or in which they already had and still were to publish more works.382 Compared to the top period of authors alive, the most authors that were active at the same time are to be found later, in the 1880s and the 1890s. For the bibliography, the top is reached in the years 1886 and 1887, when 53 authors (22 % of all the authors with known life dates) were active at the same time. In the corpus, the top year is 1884, with 33 authors (31 %). It becomes clear that the bibliography and corpus are closer together in the early decades, meaning that the coverage of authors (at least of the ones with known life dates) is better in this phase. Although the corpus includes more authors that were active in the later decades, there are even more in the bibliography, showing that the overall number of active authors and works published increased considerably towards the end of the century.
491How old were the authors when they published works? This question brings the two perspectives of “authors alive” and “authors active” together.383 The median age of the authors when they published a novel is the same for the bibliography and the corpus and lies at 37 years. Considering that most authors were born in the 1850s, it makes sense that most of them were active in the 1880s. The youngest author at publication was Carlos María Ocantos, whose novel “El esclavo” was supposedly published when he was 14 years old (Lichtblau 1997, 744Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.). The oldest author was Vicente Fidel López, who published “La Gran Semana de 1810” and “La loca de la guardia” at 81 years. The average life expectancy of the authors in the bibliography was 66 years, and in the corpus, 65 years.384
492All in all, not many differences were found between the authors contained in the bibliography and those included in the corpus. About one-third of the authors in Bib-ACMé are also represented in Conha19. Most of the authors only published one work between 1830 and 1910, of which, in most cases, also only one edition was produced. This is probably not the impression one gets when reading literary histories, where the center of interest is often on the minority of more productive, well-known authors. These are a bit overrepresented in the corpus when the number of works and also editions are considered. However, there are some also lesser-known authors who wrote much, which are more present in the bibliography than in the corpus. Regarding the distribution of authors by country, there are no big differences between the bibliography and the corpus. In the latter, there are relatively more Argentine authors and fewer Mexican authors than in the bibliography. Furthermore, Cuban authors are a bit overrepresented in the corpus, although they are the smallest group. Additional countries play a role in the nationalities of the authors and as countries of birth and death, especially Spain, but they range below 10 % of the authors. Regarding gender, there are relatively more female authors in the corpus than in the bibliography, but the difference is only about 3 %. The life dates of the authors were also evaluated and not much difference was found between authors in Bib-ACMé and Conha19. Most authors lived between the 1850s and the 1910s, and most were active in the 1880s and 1890s. The average age of an author when publishing a work is the same in the bibliography and the corpus, and the age of death of the authors also only differs by one year.
493829 works are registered in the bibliography, of which 256 (31 %) are contained in the corpus. The previous chapter discussed how many works were published per author. In this chapter, the first focus is on the number of works published over time, using the publication years of the first known editions of the works.385
494First, it is analyzed how many works were published per year between 1830 and 1910. The first work in the bibliography is from the year 1832, and in the corpus, there are two works first published in 1839. The last works in both Bib-ACMé and Conha19 were published in 1910. Apart from the 1830s, when only a few works were published, almost all the years are covered in the bibliography. Exceptions are the years 1849, 1852, and 1867. As the numbers were generally low in the 1840s and the early 1850s, it is possible that no novels at all were published in 1849 and 1852. In the year 1867, however, it is surprising. It may be the case that the political situation in the three countries made it difficult for authors to write or publish novels in that year. During the time, Argentina was involved in the War of the Triple Alliance, Cuba stood at the beginning of a period of internal wars, and in Mexico, the emperor Maximilian was overthrown by liberal troops. However, verifying that this had an effect on the number of novels that were published would require more research into the personal circumstances of the authors and the history of the publishing sector. Other years that are not represented in the corpus are some of the years in the 1830s, 1845, 1850, 1853, 1863, and 1878. Apart from the 1830s, for which it is more difficult to access the few novels that were published, this is interpreted as the effect of random selection. The number of works published increased considerably towards the end of the century. From 1880 on, at least ten works were published per year.
495Summarizing the values for decades, the coverage of works in the corpus in relationship to the bibliography becomes clearer.386 From the 1850s to the 1890s, the share of works in the corpus is about one-third, which corresponds to the overall proportion of works included in the corpus. The 1860s are slightly overrepresented with 39 %. In the margins, i.e., the early and late decades, the numbers deviate more. The 1830s, 1900s, and 1910s are underrepresented in the corpus, and the 1840s are strongly overrepresented. Apart from the 1900s, such deviations are more likely in these decades because the overall number of works is much lower than in the central decades.
496Summarizing even more and comparing the period before 1880 to the period in and after that year,387 this results in a better representation of the earlier period. 37 % of the works in the bibliography that were published before 1880 are also contained in the corpus. In the later period, 28 % of the works in the bibliography are also part of the corpus. This means that the corpus contains proportionally fewer works in the period after 1880, although in total, more works were published in the later decades of the nineteenth century.
497Another perspective on the number of works over time is obtained by differentiating by country.388 When the development of the number of works published over the decades is observed that way, different patterns become visible. In Argentina, the number of works exploded in the 1880s. According to the bibliography, 90 works were published in that decade, compared to around 20 works each in the three decades before. Apart from the 1830s, for which only one work is included in the bibliography, all the decades are also represented in the corpus. For Argentina, of the central decades, the 1870s are overrepresented and the 1900s underrepresented. In Mexico, the number of works published rose earlier and not so sharply. Considerably more works were published from the 1860s onwards, and their number increased towards the end of the century, whereas in Argentina, the number decreased again after the 1880s. Regarding the decades with many works, the 1860s are overrepresented for Mexico in the corpus. As for Argentina, no work from the 1830s is included in the corpus. In contrast to Argentina and Mexico, the number of Cuban works published between 1830 and 1910 does not show significant growth. Actually, most works that are included in the bibliography were published in the 1850s (28 works), followed by the 1890s (21 works). Compared to Argentina and Mexico, more Cuban works were published in the early decades, from the 1830s to the 1850s. It is very probable that this different development of the number of published novels in the course of the nineteenth century is due to Cuba’s status as a colony, which only ceased in 1898, and which prevented the growth of the literature marked. On the other hand, Cuba was colonized early and had a close connection to its motherland Spain, which could explain why relatively more novels were published in the early decades by Cuban-Spanish than by Argentine and Mexican authors. However, the quality of the bibliographic sources used can also play a role, as discussed above in chapter 3.2.1. Comparing the overall number of works by country, most novels in Bib-ACMé and also in Conha19 are Mexican, followed closely by Argentine novels. The Cuban novels make up the smallest part, with 16 and 19 %, respectively.389
498Looking not at which countries the novels are generally associated with in the bibliography and the corpus but in which countries they were first published, the role of Spain becomes visible: 7 % of the novels in the bibliography and 9 % of the novels in the corpus were first published in that country.390 Apart from the lowest numbers, there is no difference between the bibliography and the corpus concerning the ranks of the countries where the novels’ first editions were published. Most novels were first published in Mexico, followed by Argentina, Cuba, Spain, France, and the USA. Comparing the numbers of the publication places to the general numbers by country, it becomes clear that not only part of the Cuban novels were first published in Spain, but also Mexican and Argentine novels.
499Comparing the works in Bib-ACMé and Conha19 revealed that both are proportionately quite congruent when the distribution of works over time and the share of works by country are considered. Nevertheless, on a level of detail, also some differences became visible. In the corpus, especially the 1860s are overrepresented, and the 1900s are underrepresented. As a result, the period before 1880 is covered to a higher degree in the corpus than the one after this year. Regarding the countries, there are relatively more Argentine and Cuban and fewer Mexican works in the corpus than in the bibliography, but these differences range only between 2 to 6 %. As to the overall distribution of works over time, almost all the years between 1830 and 1910 are covered in the bibliography and the corpus, with the exception of some early years from the 1830s to the early 1850s, plus the exceptional year 1867, in which no works were published. Especially from the 1880s onwards, the number of works published increased considerably. However, this development is not the same in all three countries. In Argentina, most works were published in the 1880s; in Mexico, the number of works grew already in the 1860s; and in Cuba, no significant growth over time can be recognized at all.
500Besides the metadata that can be evaluated for both the bibliography and the corpus, some informative aspects about the novels are only available for the corpus. They depend on more specific metadata that has only been collected for Conha19 or on the full texts of the novels that are only available in the corpus. Such aspects are analyzed in this chapter. Part of the metadata that was gathered for the corpus refers to technical and administrative aspects, such as the type of source medium, the kind of source edition, and the institution that held the source. Summaries of these data were already given in chapter 3.3.1 (“Selection of Novels and Sources”) above and are not discussed here any further.
501One metadata item that was only collected for the novels in the corpus is their status as high- or low-prestige novels.391 In Conha19, 174 novels (68 %) are classified as high prestige and 82 novels (32 %) as low prestige. There is no difference in the proportion of high- and low-prestige novels from Cuba, but from Mexico there are more high-prestige novels, and from Argentina more low-prestige ones.392 There are several probable reasons for this. Surely, the quality of the bibliographic sources used as a basis for selecting novels for the corpus is an influencing factor. The bibliography of the Argentine novel authored by Lichtblau is very comprehensive and also includes many authors and works that are not well-known. Furthermore, the state of digitization and access to digital sources plays a role. The collection of Argentine novels published on Wikimedia Commons by the Argentina Academy also contains many works written by lesser-known authors. Independently of the reasons, the corpus has a certain bias towards low-prestige Argentine and high-prestige Mexican novels.
502The analysis is now deepened by considering the distribution of novels by prestige over time.393 Over the decades, most low-prestige novels were included in the 1890s, 1880s, and 1860s. On the other hand, low-prestige novels are underrepresented in the 1840s, 1870s, and the 1900s. The decades 1830 and 1910 are not really informative because the number of works in them is so small. It makes sense that in the decades in which the overall production of novels increased considerably, more low-prestige novels were produced and were also selected for the corpus. Regarding the 1900s, they are, in general, underrepresented in Conha19394, so the probability of selecting high-prestige works is higher. The 1840s, in contrast, are generally represented quite well in Conha19395, so it can be assumed that there were not many works in that decade that are considered low-prestige today, or if there were, they are not known. Why low-prestige works are underrepresented in the 1870s is not clear. Summarized to the two periods before and in or after 1880, the proportion of low-prestige works is higher in and after 1880.
503Another metadata item that is only available for the corpus is the narrative perspective of the novels. In general, there are 44 novels (17 %) with a first-person narrator and 212 novels (83 %) with a third-person narrator, so the latter clearly prevails. Regarding the distribution of the narrative perspective by country, it is interesting that the proportion of Cuban novels is much lower for the novels narrated in the first person than for those narrated in the third person. A hypothesis is that the individual, personal perspective was not so suitable for novels published in the colony. The first-person novels are mainly Argentine, closely followed by the Mexican novels, and the third-person novels are above all Mexican.396
504When analyzed over time397, it becomes visible that the proportion of novels written in the first person was highest in the 1870s, 1890s, and 1880s. No first-person novel is included from the 1850s, and also the 1840s and 1900s are mostly represented with novels narrated in the third person. The drop of first-person novels in the 1900s is surprising because otherwise, they became more frequent after the middle of the nineteenth century. Again, this decade is generally underrepresented in the corpus, which might be a reason. Comparing the period before 1880 to the one in and after 1880 shows that narrations in the first person are relatively and absolutely more frequent in the latter period, although the difference between the two periods only amounts to 6 %.
505Further information that was collected for the novels in the corpus is the continent and country of the setting. 9 % of the novels are primarily set in Europe, and just one novel is set on another continent398, so the great majority of 90 % is set in America. Looking at the country of the setting, Mexico, Argentina, and Cuba are most frequent, corresponding to the countries of origin of the novels. Other places the novels are set in are the European countries Spain, Italy, France, Greece, Switzerland, the USA, and other South-American countries (Peru, Chile, Bolivia, Brazil, and Uruguay). Together, American countries other than Mexico, Argentina, and Cuba make up for 4 % of the cases.
506An evident question is if the preference for a European or American setting was influenced by the country of origin of the novels, i.e., if there is a difference between the Argentine, Mexican, and Cuban novels in this aspect. Analysis of the metadata shows that this is indeed the case.399 While the proportions of Mexican, Argentine, and Cuban novels set in America correspond largely to the general significance of these countries in the corpus, the numbers are quite different for the novels set in Europe. Here, the majority is Cuban and the minority Mexican, suggesting that Cuba’s status as a colony during most of the nineteenth century had an influence on the setting of the novels. In addition, the relationship between Argentina and Europe was closer than that between Mexico and Europe as regards the choice of setting for the fictional texts. However, in absolute numbers, only 24 novels are set in Europe, so these trends should also not be overinterpreted. Following the proportions of works set in Europe over the decades and comparing their share in the period before 1880 and in or after that year makes clear that the number of works set in Europe decreased over time. Moreover, at least in the corpus, the 1860s were already a decade in which an American setting was clearly preferred.400
507Besides the continent and country of the setting, also the time period covered by the novels is registered in the metadata. Three time periods are distinguished: contemporary, recent past, and past. For each novel, two values were encoded: the time period relative to the author’s birth year and relative to the year of the first known publication of the novel.401 From both points of view, a contemporary setting is the most frequent one: related to the authors’ birth years in 82 % and relative to the publication date in 73 % of the cases. Novels set in the past are the second most frequent group, with 13 % and 16 %, respectively. The recent past is treated in 4 % of the novels when the authors’ birth years are concerned and in 11 % of the works when the publication year is decisive. The differences between the two approaches show that more novels treat a period that is past in relation to the publication date but still part of the contemporary experience of the authors. Fewer novels treat a period that lies in a more distant past. In the following, only the approach of comparing the publication date to the time period covered by the novels is considered further.
508How do the proportions of the three time periods covered in the novels relate to the three different countries that the novels are associated with in the corpus?402 As can be seen, the Argentine and Mexican novels cover most of the contemporary perspective. As the general proportions of works by country were 42 % Mexican works, 39 % Argentine works, and 19 % Cuban works,403 a contemporary setting is a bit overrepresented in the Argentine novels and slightly underrepresented in the Mexican and Cuban novels. A setting in the past is overrepresented in Mexican and Cuban novels and underrepresented in Argentine novels. Here the differences range between 3 and 6 % of the novels. The preferences are most striking concerning a setting in the recent past. Here, Mexican novels are overrepresented by 8 % and Cuban novels by 10 %, while Argentine novels are underrepresented by 18 %. All in all, the past is more a topic in the Mexican and Cuban novels, and the recent past is relatively most important in the latter ones, while the contemporary perspective is favored in the Argentine novels. This might be explained by the fact that the colonial history of Cuba and Mexico is longer than that of the Argentine region. In the case of Cuba, another factor is the difficulty of broaching contemporary issues in a country that was still under the control of the mother country, which may have led to a preference for representing the recent past. On the other side, Argentine society and economy developed rapidly in the nineteenth century, which supplied much material for the novels treating the contemporary period.
509Did the preference for setting the novels in a certain time period change in the course of the nineteenth century? An analysis of the distribution of time periods per decade and a comparison of the period before 1880 to the one after that year suggests that there is no clear chronological trend but that there are some intermittent preferences instead.404 The contemporary period was always dominating as a setting for the novels. Interestingly, the past was favored more in the 1860s and then again in the 1900s. Leaving out the first and last decades with very few works, also the recent past reaches the top positions in these two decades. The lowest proportions of novels treating the past and recent past can be seen in the 1880s and 1890s. So a first trend of treating historical issues came up shortly after independence was reached in most Spanish-American countries, probably as a way of contributing to writing their own history in literary terms. Then, in the decades of significant social and economic development, contemporary issues were more relevant. A return to a greater interest in the recent and further past at the beginning of the new century marks a new phase.405 Condensing this development to the phase before and after 1880 results in relatively more novels treating the contemporary period in the latter and some form of the past in the former.
510A characteristic of the novels in the corpus that goes beyond metadata is the length of the texts. In the context of the definition of boundaries of the novel, the minimum length of novels was discussed in detail in chapter 3.1.1.4 above. Therefore, regarding the novels that were included in the corpus, the question remains how long these actually are in terms of the number of tokens.406 The shortest novel in the corpus has about 16,000 tokens, the longest one has about 331,000 tokens, and the median length is approximately 53,000 tokens.407 It is interesting that the medium length of the Spanish-American novels in this corpus corresponds almost to the minimum length for novels set by Forster to 50,000 words (Forster 2016, 17Forster, E. M. 1927. Aspects of the novel. New York: Harcourt, Brace & Company.), so the nineteenth-century Argentine, Mexican, and Cuban novels, as defined here, tend to be shorter than the typical English novel that Forster had in mind. 25 % of the novels are between 16,000 and 35,000 tokens long, the next 25 % between 35,000 and 53,000 tokens, the third quarter is between 53,000 and 96,000 tokens, and the last one between 96,000 and 331,000 tokens, so the spread of lengths increases considerably for the upper 50 % of the novels and the longest novels are clearly outliers.
511Analyzed by country, the distribution of lengths is very similar for the Argentine and Cuban novels but different for the Mexican novels.408 The median Argentine novel is 48,000 tokens long, and the median Cuban novel has 50,000 tokens, so they are both shorter than the overall median novel. The longest Argentine novel has 231,000 tokens, and the longest Cuban novel has 198,000 tokens. Compared to that, Mexican novels are longer. The medium Mexican novel is 67,000 tokens long, and the three longest novels with over 300,000 tokens are also Mexican. The three longest novels are historical novels, so it should be examined if there is a correlation between the length of the novels and their subgenre, which is done for thematic subgenres and literary currents in chapter 4.1.5.3 below. Testing for statistical significance, it turns out that the difference in length between the Mexican and the Argentine, as well as between the Mexican and the Cuban novels, is indeed significant.409
512How does the novels’ length develop over the decades?410 First, in the decades 1830 to 1850, the median length drops from 110,000 to 36,000 tokens. In the 1860s, it jumps to 87,000 tokens, and after that, it raises from 47,000 in the 1870s to 99,000 in the 1910s. The works in the 1830s and 1910s are very few, though. Regarding the median, it is especially interesting to see the exceptional decade of the 1860s. As was found out in the evaluation of the time periods of the novels’ settings, in this decade, representations of the past were relatively favored. In addition, they were preferred in Mexican novels, and these were more numerous in the 1860s than Argentine and Cuban novels.411 Together with the observation that the longest novels of the corpus are historical novels, this might explain why there were more long novels in this decade than in the others. A test for statistical significance reveals that the text lengths can be considered significantly different in the following constellations of decades: 1860s versus 1870s, 1860s versus 1880s, and 1880s versus 1900s.412 It is also noteworthy to see that the variability of the texts’ length (in terms of the spread of length in the two central quartiles) is lower from the 1870s to the 1890s than before and after that decade. In the last three decades of the nineteenth century, very long novels are the exception.413
513As already stated in the overview section on authors, an evaluation of the number of editions emphasizes the role that the works played in the (literary) society of their time and also how the works were anchored in time and place. As “expressions” and “manifestations” of the works, realizing and embodying their intellectual content (International Federation of Library Associations and Institutions (IFLA) 2009, 13International Federation of Library Associations and Institutions (IFLA). 2009. Functional Requirements for Bibliographic Records. Final report. https://repository.ifla.org/handle/123456789/811.), editions link the works to their socio-cultural, historical, and geographical background. In the section on works above, the first known editions served as placeholders to look at where and when the works were published. Obviouesly, editions also play a role beyond the first appearance of a work. In this chapter, all the editions that were collected in the bibliography Bib-ACMé are analyzed together.
514In total, 1,220 editions that were published between 1830 and 1910 are included in Bib-ACMé. All the editions of the works contained in the corpus were considered, even though the full texts usually rely only on one specific edition. However, as explained above in the sections on the assignment of subgenre labels (see chapter 3.2.3 for the bibliography and 3.3.4 for the corpus), all available editions were evaluated for generic signals in order to determine the subgenre of a work. This was done in terms of metadata and paratexts of the editions. As a result, the corpus covers 498 editions, which is 41 % of the editions in the bibliography. Assessing the number of editions is especially interesting when they are compared to the number of works. What changes with this other perspective?
515The number of editions per author was already shown in the overview chapter on authors above (chapter 4.1.2). Here, the number of editions per work is analyzed.414 In Bib-ACMé, most novels were only published in one edition (582 works, i.e., 48 %), followed by 161 works (13 %) with two, 54 works (4 %) with three, 17 works (1 %) with four and 15 works (also 1 %) with five or more editions. The work with the most editions (10) is “Amalia” (1855, AR) by José Mármol, followed by “Clemencia” (1869, MX) by Ignacio Manuel Altamirano and “Anatomía del corazón” (1856, CU) by Teodoro Guerrero y Pallarés with seven editions each. These three works were all first published early. The first two are famous representatives of the nineteenth-century novel of their respective countries, while the third one is rather nameless from today’s point of view. In the corpus, in comparison, works with just one edition are underrepresented (22 % of the works with only one edition in the bibliography), and works with more than one edition are overrepresented (42 %, 69 %, and 65 % of the works with two, three, and four editions in the bibliography, respectively). The numbers of editions show that the sample size of the corpus is larger in terms of editions than in terms of works, where it was about one-third, reconfirming that the corpus contains relatively more popular or successful works than the bibliography as a whole.
516In the following, the distribution of editions over time is analyzed from three perspectives: by years, decades, and the period before or in and after 1880.415 Some of the early years are not represented at all (1830, 1831, 1833, 1834, 1835, 1849, and 1852). These are the same years as in the case of works, except for the year 1867, which now has one edition of the work “Anatomía del corazón”. This work was first published in 1856 in Madrid and republished in La Habana in 1867, inter alia. The three years with the most editions are 1886, 1887, and 1903, which corresponds to the years with the most works.
517The distribution of editions over the decades is comparable to the development of the number of works, only that the absolute numbers are higher in the case of the editions. Their number increases steadily from the 1830s to the 1870s and then sharply in the 1880s, where it reaches the top and then remains high in the next decades. Apart from the 1830s with very low numbers, the share of editions in the corpus is a bit above average in the early decades up to the 1870s and below average in the 1880s, 1900s, and 1910 (when compared to the bibliography). This results in a higher representation of the period before 1880 in the corpus.
518These conditions are similar to the distribution of works over the two periods, which is unsurprising if almost 50 % of the novels only had one edition between 1830 and 1910. However, for the number of works, the difference between the period before 1880 and in or after 1880 amounted to 9 % and for editions only to 5 %, meaning that relatively more works with several editions published in or after 1880 are included in the corpus.
519Another point of interest is to see how many editions were published by country and also in which cities the editions appeared. In these analyses, editions for which several places of publication are given on the title pages are counted several times.416 In the bibliography, most editions are published in Mexico, followed by Argentina, and in the corpus, it is the other way around. In contrast to the corresponding overview for works, where only the places of the first publication were considered, for all the editions, the third most important country of publication was Spain and not Cuba, both in the bibliography and the corpus. This means that many works that were first published in Mexico, Argentina, or Cuba, were republished in Spain.
520The most important cities of publication were the three capitals Mexico (34 % of all the editions), Buenos Aires (33 %), and Havana (8 %). In the corpus, Buenos Aires outranks Mexico. Given that the corpus contains more works associated with Mexico (42 %) than with Argentina (39 %), this means that the Mexican works contained in the corpus were more often published elsewhere than Argentine works, be it in another Mexican city or in another country. Right after the three capitals, the Spanish cities Barcelona (6 % of the editions) and Madrid (4 %) follow, and Paris (3 %) occupies the sixth rank. These numbers and also the whole list of cities illustrate that the publishing of the novels was centralized to a high degree and that European metropolises also played a role in the distribution of the novels. On the other hand, there is also a long list of individual publication places, showing a greater diversity of local and foreign publishing activity, if not quantitatively, at least qualitatively. There are, for instance, 32 different Mexican, 11 Argentine, and 10 Cuban publication places.
521To summarize, comparing the number of editions in the corpus and the bibliography to the number of works contained in both, the corpus involves relatively more editions, meaning that the works in the corpus were republished more often than the average work in the whole bibliography. Relatively, the numbers of editions over time are comparable to the numbers of works. Regarding the number of editions, the period before 1880 is a bit better represented in the corpus than the period after that year, but the difference between the two periods is smaller than in the case of the works. Considering the countries and places of publication of the editions, Spain plays a bigger role when all the editions are considered and not only the first editions of the works. The main places of publication are the three capitals of the countries selected for the bibliography and corpus, followed by European cities and a whole range of other publication places of minor importance.
522This chapter gives overviews of the subgenres to which the novels in the bibliography and the corpus are assigned. According to the model of subgenre terms developed in chapter 3.2.3 above, a distinction is made between explicit subgenre signals that are directly mentioned in titles and other paratexts of the novels and implicit signals that were inferred from them. Furthermore, labels that are signaled (explicitly or implicitly) are differentiated from labels that were assigned to the novels by literary historians. In addition and cross to the above distinctions, the subgenre labels are organized into several semiotically justified levels (theme, current, identity, and several modes of the medial and syntactic realization and the communicational frame). If not otherwise stated, multiple assignments of subgenre labels are all counted in.
523In the bibliography, 622 novels (i.e., 75 % of all the novels) carry an explicit (sub)generic signal of any kind, while 207 novels do not carry any explicit signal at all. In the corpus, 204 novels (80 % of all the novels in the corpus) have an explicit signal. The explicit label “novela” is carried by 404 (49 %) of the novels in the bibliography and by 134 (52 %) of the novels in the corpus. How can this be interpreted? Either the novel, as defined here, is a genre that is so self-evident that its representatives do not need the explicit denomination to be recognized, or it is so vaguely defined that as many other texts are covered by it. However, as information about almost all the works in Bib-ACMé and Conha19 was retrieved from relevant bibliographies and literary histories of the novel, the former aspect is more plausible.417 In what follows, the proportions of works in the bibliography with and without the explicit label “novela” are analyzed by decade.418 Up to the 1870s, more than half of the works in the bibliography carry the label “novela”. From the 1880s on, this label becomes rarer, suggesting a change in the conventions of labeling the works over time.419 However, both types of works, those with and without the explicit label “novela”, were present in all the decades.
524In total, 108 different explicit subgenre labels are found in the bibliography. Although these labels are called “explicit” here, they do not correspond exactly to the historical denominations used to mark the novels because the values were normalized in order to be comparable. Part of this normalization is that compound labels were split up, and each part was marked up separately.420 The top 20 of these regularized explicit labels in the bibliography are analyzed here and compared to the corresponding labels in the corpus.421 The general label “novela” is the most frequent one. The other top explicit labels are of different kinds. Some labels are directly related to the themes of the novels and are recognizable as subgenres of the novel: “novela histórica” (on rank 2 in the bibliography), “novela de costumbres” (rank 5), “novela social” (rank 13), and “novela policial” (rank 17). Labels referring to the linguistic and cultural identity of the novels also recur in this top list: “novela original” (rank 3), “novela mexicana” (rank 4), “novela cubana” (rank 9), “novela nacional” (rank 11), “novela argentina” (rank 15), and “novela americana” (rank 16). Of the remaining labels, several are (not exclusively, but often) related to different kinds of historical novels: “episodios” (rank 6), “memorias” (rank 7), “leyenda” (rank 8), and “historia” (rank 12). The labels “escenas” (rank 18) and “cuadros” (rank 19) are often connected to novels of customs. Interestingly, also labels designating other genres, such as “drama” (rank 10), “cuento” (rank 14), and “ensayo” (rank 20), are among the top labels for the novel.
525For the corpus, the ranks of explicit labels are similar, but there are also a few differences.422 Labels that are in the top 20 for the corpus but not for the bibliography are “estudio” (rank 15), “novela realista” (rank 18), “crónica” (rank 19), and “novela militar” (rank 20). On the other hand, labels that are in the bibliography top 20 list but not in the corresponding corpus list are “novela nacional”, “novela policial”, “escenas”, and “ensayo”. When the first ranks of the bibliography and corpus lists are compared, differences are, for example, that the number of “novelas históricas” is almost equal to the “novelas de costumbres” in the corpus, whereas it is around twice as high in the bibliography. Furthermore, “novela cubana” is on rank 6 in the corpus compared to rank 9 in the bibliography.
526Analyzing the top explicit subgenre labels brings to light several characteristics of the novels in the bibliography and the corpus. First, the most prominent explicitly marked subgenre is the historical novel, both according to the number of occurrences of the literal label and also based on several other subgenre labels related to it, which leads to the conclusion that the most prominent subgenres are historical novels. Second, there was an evident need to explicitly mark the linguistic, cultural, or national identity of the novels. As there are so many different kinds of identity labels, it is of interest to check how many novels carried such labels. In the bibliography, 272 novels (33 %) had an identity label, and in the corpus, 100 novels (39 %). As with the general label “novela”, also here the question arises if the use of identity labels depends on the period of publication of the novels.423 A trend becomes visible over the decades, as the number of novels carrying identity labels decreases continuously. A third point that can be drawn from the top frequent explicit labels is which subgenres are more important in the corpus than in the bibliography. These are the novels of customs, realist, and naturalistic novels linked to the labels “novela realista” and “estudio” and also Cuban novels.
527If implicit signals are included in the evaluation, the range of subgenres broadens because some subgenres are never marked explicitly. This also means that the assignment of subgenre labels gets more interpretive. For 511 works (62 %) in the bibliography and 207 works (81 %) in the corpus, implicit signals were found.424 If this is added to the explicit information, subgenre signals were recognized for 738 novels (89 %) in the bibliography and 254 novels (99 %) in the corpus. In the following, the top 20 subgenre labels for Bib-ACMé and Conha19 are analzyed, taking explicit and implicit signals into account together.425
528When also implicit signals are included, more subgenres related to the themes of the novels and to literary currents enter the top positions: in the bibliography, rank 2 is still occupied by the “novela histórica” followed by the primarily thematic labels “novela sentimental” (rank 3), “novela social” (rank 6), “novela de costumbres” (rank 7), “novela política” (rank 14), “novela criminal” (rank 17), and the “novela de la ciudad” (rank 20). Labels relating to literary currents are “novela romántica” (rank 4), “novela naturalista” (rank 12), and “novela realista” (rank 15). This shift could be expected because the assessment of implicit signals requires an interpretation frame, and subgenres focusing on theme and literary currents are the dominant perspectives in literary histories.
529Comparing the top 20 signals of Bib-ACMé to Conha19, again, some subgenres gain more weight in the corpus: the “novela sentimental” moves from rank 3 to 2, the “novela de costumbres” from rank 7 to 4, the “novela gauchesca” enters the top list on rank 20, the “novela naturalista” from rank 12 to 8, and the “novela realista” from rank 15 to rank 10. The “novela romántica”, on the other hand, gets less important and moves from rank 4 to 6, the “novela histórica” switches from rank 2 to rank 3, and the “novela de la ciudad” is not part of the top list anymore.
530When only statements made by literary historians are evaluated, the picture changes even more. Literary-historical assignments were recorded for 433 works (52 %) in the bibliography and 224 works (88 %) in the corpus. That the proportion of works with literary-historical labels is much higher in the corpus is certainly because the corpus contains more works that are better known and researched. There are 34 different literary-historical labels in the bibliography and 32 different ones in the corpus. As with the explicit paratextual signals, also here, the labels were homogenized to be comparable and do not correspond to literal statements in every case.
531In the bibliography, the label most often assigned is “novela romántica”, followed by “novela histórica” and “novela realista”.426 Labels that were not included in the top ranks of generic signals, but are top literary-historical labels, are “novela indigenista”, “novela abolicionista”, “novela modernista”, “novela de aventuras”, “novela verista”, “crónica”, “novela científica”, and “novela satírica”. Here, different critical perspectives on nineteenth-century Spanish-American novels are introduced, for example, specific topics and socio-cultural concerns (“novela indigenista”, “novela abolicionista”) or particular literary currents (“novela modernista”, “novela verista”), but also general generic subcategories that are not specified culturally (“novela de aventuras”, “crónica”, “novela científica”, “novela satírica”).
532The top ranks of literary-historical labels in the corpus are of a similar kind but in part differently ordered. The “novela romántica” is also most important in the corpus. Labels with more weight than in the overall bibliography are “novela social”, “novela de costumbres”, “novela naturalista”, and “novela abolicionista”, for instance, and labels that are less relevant in the corpus are, for example, “novela histórica”, “novela realista”, “novela criminal”, and “novela gauchesca”. The different top ranks illustrate where there have been shifts in the composition by subgenre due to the selection of works for the corpus. Some were made on purpose, for example, the inclusion of more novels of customs as a counterbalance to the great majority of historical novels or a preferred inclusion of Cuban novels to strengthen the smallest country group. Others depend on the availability of the novels. Many crime and gaucho novels can be classified as low-prestige novels and are not yet readily available in digital format.
533The differences between explicit subgenre signals, implicit signals, and literary-historical subgenre assignments underline that the views on what a subgenre of the novel is differ considerably, depending on the practice and the purpose of the labeling. There are only some intersections. The labels assigned to the historical editions probably served a number of functions:
534Even though literary-historical approaches to subgenres aim to systematize the field, in sum, the resulting set of labels is still a conglomerate of different perspectives on the novels, even if to a lesser degree than the historical labels. This becomes very clear when the same novel is labeled with several terms at the same time. The works of the Mexican writer Victoriano Salado Álvarez, for example, have been classified both as historical and realist novels (Fernández-Arias Campoamor 1952, 84–85 Fernández-Arias Campoamor, José. 1952. Novelistas de Mejico: esquema de la historia de la novela mejicana (de Lizardi al 1950). Madrid: Ediciones Cultura Hispánica. ; Read 1939, 293–294Read, John Lloyd. 1939. The Mexican Historical Novel. 1826–1910. New York: Instituto de las Españas en los Estados Unidos.) and some works by the Cuban Cirilo Villaverde both as novels of customs and romantic novels (Remos y Rubio 1935, 166–180Remos y Rubio, Juan J. 1935. Tendencias de la narración imaginativa en Cuba. La Habana: Casa Montalvo-Cárdenas. https://dloc.com/UF00078289/00001/images.; Suárez-Murias 1963, 23–24Suárez-Murias, Marguerite C. 1963. La novela romántica en Hispanoamérica. New York: Hispanic Institute in the United States.). This makes it difficult for a stylistic analysis of subgenres that aims to select and compare subsets of novels from a corpus. Therefore, the explicit, implicit, and literary-historical labels have been sorted according to a system of discursive categories, as explained above in chapter 3.2.3, resulting in several sets of labels that belong to different discursive levels but whose comparison is more meaningful on each level. It has to be reminded, though, that this system is artificial. In what follows, overviews of the different sets of subgenre labels based on the discursive model of subgenre terms are given for the bibliography and the corpus. First, summaries of how many labels there are on which levels are presented.427
535How many different labels on the various discursive levels are there in the whole bibliography? In total, there are 124 different terms. Most of them belong to the thematic group (39 %), followed by the mode the novel is represented in linguistically or narratively (36 %), the cultural-geographical and linguistic identity of the novel (20 %), the medium that the novel uses (11 %), the intention of the author or narrator (10 %), the relationship between the novel and reality (8 %), the literary current of the novel (5 %), and the attitude the author or narrator has towards what is represented in the novel (4 %). The diversity of thematic labels is not surprising, and that there is only a small set of labels related to literary currents is expectable as the number of different currents is limited. The broad range of labels referring to the mode of representation and also to the identity was not expected, though, as these aspects are usually not focused on in studies of subgenres of the Spanish-American novel.
536How many different subgenre labels are there in Conha19? In the corpus, there are 90 different subgenre labels, which are distributed similarly over the different levels when compared to Bib-ACMé.428 44 % of the different labels are thematic, 36 % are related to the mode of representation, 14 % to the identity, 13 % to the medium, 10 % to the intention, 9 % to the mode of reality, 7 % to the literary current, and 3 % to the attitude.
537The significance of the different discursive levels changes to a certain degree if not the number of different labels in each category is considered, but the overall number of labels belonging to them. How often have such labels been assigned?429 In total, on the different levels, 3,193 labels were assigned to the novels in the bibliography and 1,317 to the novels in the corpus.430 Most labels are of the thematic type (38 %), followed by the mode of representation (23 %), literary currents (15 %), the mode of reality (10 %), identity (10 %), the attitude (2 %), medium (2 %), and intention (1 %). So in terms of quantity (instead of diversity), labels related to literary currents and the reality mode are more important, while labels associated with the mode of representation, with identity, the medium, intention, and attitude are less relevant. The picture is similar for the corpus, only that literary currents have a bit more weight than modes of representation.431 In Conha19, 40 % are thematic labels, 20 % are related to literary currents, 18 % to the mode of representation, 8 % to the identity, 8 % to the mode of reality, 2 % to the attitude, 2 % to the medium, and 1 % to the intention. Clearly, thematic labels are most important both when the number of kinds and the overall number of assignments is considered.
538The impression that the overall top lists of labels give is also confirmed when one differentiates between different sources of labels. All in all, there are 108 different explicit subgenre labels in the bibliography and 34 different literary-historical labels. The corpus includes 70 different explicit labels and 32 different literary-historical labels. This means that the diversity of explicit labels doubles the diversity of literary-historical labels in the corpus and is three times higher in the bibliography. Regarding the overall number of labels, 1,669 explicit labels and 1,120 literary-historical labels were assigned to the works in the bibliography, and 564 explicit and 686 literary-historical labels were assigned to the works in the corpus. So on average, a literary-historical label is assigned more often than an explicit label.432 The following table 23 summarizes the importance of the different discursive levels for explicit versus literary-historical labels in the bibliography.433
| Rank | Different explicit labels | Amount explicit labels | Different literary-historical labels | Amount literary-historical labels | ||||
|---|---|---|---|---|---|---|---|---|
| 1 | mode.representation |
43 | mode.representation |
707 | theme |
25 | theme |
558 |
| 2 | theme |
37 | theme |
363 | current |
6 | current |
385 |
| 3 | identity |
25 | identity |
302 | mode.representation |
5 | mode.reality |
121 |
| 4 | mode.medium |
14 | mode.reality |
203 | mode.reality |
4 | mode.attitude |
35 |
| 5 | mode.intention |
13 | mode.medium |
48 | mode.intention |
2 | mode.representation |
10 |
| 6 | mode.reality |
9 | mode.intention |
28 | mode.attitude |
2 | mode.intention |
7 |
| 7 | mode.attitude |
4 | current |
11 | mode.medium,
identity |
1 | mode.medium,
identity |
2 |
| 8 | current |
2 | mode.attitude |
7 | - | - | - | - |
539When differentiating by the type of source (explicit versus literary-historical labels), thematic labels are also generally important. Regarding the overall number of labels, the mode of reality also has some importance for both explicit and literary-historical labels. The relevance of the other levels depends more on the provenance of the labels. For explicit labels, the mode of representation and identity are prominent, and for literary-historical labels, in particular, the literary currents. The ranks do not change for the corpus, apart from minor shifts in the last positions.434 Regarding the importance of the linguistic and cultural-geographical identity of the novels, it has to be said that this aspect is, of course, also a topic in the critical discourse about the novels, but in a different way than in the historical practice of labeling the works. For literary-historical studies, usually, the linguistic and cultural-geographical frame is set from the beginning on. Either it concentrates on one national space, e.g., “the Mexican novel”, or on Spanish America or Latin America as a whole and then differentiating the novels by country. However, usually, no difference is made between one work or the other and the attribution to the cultural-geographical space is made based on general extra-textual parameters. On the other hand, in literary histories, works are also reviewed in terms of how their content reflects local or foreign realities, but usually in more general terms and without explicitly categorizing novels in that way. Furthermore, the question of the own and the foreign is discussed more in aesthetic categories.435
540So far, the discursive model has served to give a general overview of what kind of subgenre labels are relevant in Bib-ACMé and Conha19. Proceeding to the individual levels and the actual labels, it becomes clearer what these subgenres are and which ones dominate from a quantitative point of view. The different levels are presented here in the order of their relevance for analyses of the novels in the corpus from a quantitative point of view. Starting with the thematic labels, of all the works in the bibliography, 695 (84 %) have such a label. In the corpus, all the works have been assigned at least one thematic label. There are 48 different thematic labels in the bibliography, of which 18 are assigned to at least 10 works.436 In the bibliography and in the corpus, as well, four thematic subgenres are predominant: the sentimental novel, the historical novel, the social novel, and the novel of customs. Especially in the corpus, also the political novel is significant. Comparing bibliography and corpus, the order and ratio of the top thematic subgenres are different. In Conha19, the social novel and the novel of customs are relatively more important, and the sentimental and historical novels are less relevant. However, the absolute amount of these four subgenres is more balanced in the corpus than in the bibliography.
541An analysis of the sources for the top 18 thematic labels shows the different statuses they have as explicit historical subgenres, implicitly signaled subgenres, and literary-historically discussed subgenres.437 As can be seen, the historical novel and the novel of customs are the most important historically explicit subgenres, followed by the “leyenda” and the “novela policial”. Especially the sentimental novel is implicitly signaled. All four top subgenres play an important role as literary-historical subgenres. Although this list of thematic labels is already the result of a process of systematization, two kinds of one-to-many relationships persist: the same label can also play a role on other discursive levels (the “novela histórica”, “leyenda”, and “novela contemporánea”, for example, are also among the labels referring to the relationship between the novel and reality) and each novel cannot just carry one, but several thematic labels. The latter is very often the case.438 In the bibliography, 16 % of the novels do not have any thematic label, 45 % have just one, 23 % have two, 11 % have three, and 5 % have more than three thematic labels. In the corpus, all the novels have thematic labels: 38 % have just one, 33 % have two, 18 % have three, and 11 % have more than three different thematic labels. The difference between the bibliography and the corpus shows that the more is known about the works, the more differentiated (and less clear) their categorization is in terms of subgenres. Besides the one-to-many relationships, i.e., one work to many thematic subgenre labels, there are also relationships of overlap or inclusion among the different thematic labels. For example, the “novela abolicionista” can be considered a special type of social novel, and the “leyenda” is associated with historical content just as the “novela histórica”.439 Relationships of this kind also become visible in the most frequent combinations of thematic subgenre labels, which are listed in table 24 below.440
| Rank | Bib-ACMé | Conha19 | ||
|---|---|---|---|---|
| Labels | Number of assignments | Labels | Number of assignments | |
| 1 | novela de
costumbres, novela social |
58 | novela de
costumbres, novela social |
48 |
| 2 | novela histórica,
novela sentimental |
51 | novela
sentimental, novela social |
31 |
| 3 | novela sentimental, novela social | 41 | novela de costumbres, novela sentimental | 30 |
| 4 | novela de
costumbres, novela sentimental |
37 | novela histórica,
novela sentimental |
26 |
| 5 | leyenda, novela histórica |
29 | novela de
costumbres, novela sentimental, novela social |
16 |
| 6 | novela histórica,
novela política |
18 | novela de
costumbres, novela histórica |
14 |
| 7 | novela de
costumbres, novela histórica |
16 | novela de costumbres, novela política |
12 |
| 8 | novela de
costumbres, novela sentimental, novela social |
16 | novela histórica,
novela política |
10 |
| 9 | novela histórica, novela indigenista |
15 | novela política, novela social |
9 |
| 10 | leyenda, novela sentimental |
13 | novela abolicionista, novela social | 8 |
542The most frequent combination of thematic subgenre labels both in the bibliography and the corpus is “novela de costumbres” and “novela social”. Most top combinations are very frequent in both Bib-ACMé and Conha19, even if the ranks are not exactly the same. Combinations that are only in the top ten of the bibliography are highlighted in blue, and the ones that are only in the top list of the corpus are highlighted in orange. As can be seen, combinations including the “leyenda” and “novela indigenista” have more weight in the bibliography and combinations including the “novela política” and the “novela abolicionista” have more weight in the corpus. Clearly, combinations of the “novela sentimental” with other types are the most frequent ones that are not characterized by semantic overlap.
543Quantity distributions as the ones described for thematic subgenre labels here (a few frequent groups and many infrequent ones) and complexities (multiple assignments and interrelationships) have consequences for a digital quantitative analysis that aims to analyze novels in terms of subgenre categories. First, for very small groups, it is hardly possible to achieve general results as they will be influenced very much by the particular characteristics of the few individual works that form the group. Furthermore, groups of very different sizes cause problems when evaluating the performance of a categorization task. In the case of a large majority, good results could simply be achieved by always choosing that group. To avoid that, the groups to compare would have to be balanced down to the smallest size by undersampling. Another strategy is oversampling, where instances of the smallest group are duplicated, which again can cause problems of overfitting and a lack of generalizability.441 This study will concentrate on the largest groups of novels that are represented in the corpus to avoid these problems as far as possible. In the case of thematic subgenres, these are sentimental, historical, and social novels, novels of customs, and political novels.
544One way to solve the problem of multiple assignments is to decide on primary labels. For thematic labels and those relating to literary currents, this was done by choosing the label
545The process of choosing a primary label changes the order of the top thematic subgenres both in the bibliography and in the corpus.442 In Bib-ACMé, the historical novel becomes more important than the sentimental novel, and in Conha19, also the historical novel rises from the fourth to the top position and changes place with the social novel. This shows that both the sentimental and the social are often secondary thematic aspects in the novels, but at the same time, they can also be primary concerns. The primary labels can be used as target values in a standard categorization task, keeping in mind that part of the works has secondary labels when evaluating the results. Another possibility to handle multiple assignments of subgenre labels on the same discursive level is to include them all in the analysis. For a categorization task, this would mean allowing multiple target values, as, for example, in a multi-label classification.443 In both cases, one has to be aware of using subgenre labels that stem from multiple sources and that have been assigned to the works by people with different perspectives on them and different interests in them. The goal of such a categorization can only be to examine to what extent the collective labelings actually reflect characteristics of the texts, and to find out to which traits of the texts they correspond. If literary-historical sources are included, these already introduce an element of systematization, so the digital text analysis then aims to analyze in what way this system matches the one found based on a computational treatment of the texts. The collectivity of labelings also applies to explicit historical labels when the whole set of novels is concerned, and to a lesser degree also per work, for example, when there is a label mentioned on a title page and the same or another one in a foreword or introduction written by someone who is not the author or editor of the work. Usually, though, historical labels are not multiple because they stand for a will to mark a novel as a representative of a certain subgenre and do not aim to describe the text systematically in all its aspects. Still, cases of multiple assignments also exist for historical labels, especially on different discursive levels, but also on the same ones. An extreme case is the novel “Los bandidos de Río Frío” (1892, MX) by Manuel Payno which has the subtitle “Novela naturalista, humorística, de costumbres, de crímenes y de horrores”, including two thematic labels (“novela de costumbres”, “novela de crímenes”), two labels of intention (“novela humorística”, “novela de horrores”) and one label indicating the literary current (“novela naturalista”). Another combination that occurs three times in the bibliography is that of “novela histórica” and “novela de costumbres”.444
546Going on to another level of subgenre labels, the ones related to literary currents, 405 works (49 %) in the bibliography and 201 works (79 %) in the corpus have such labels, so compared to thematic labels, the coverage of works is lower in both the bibliography and the corpus. This is mainly because the assignment of a work to a literary current is, above all, a critical task, so there are fewer sources than for thematic labels, as the latter draw from explicit and implicit signals and literary-historical sources alike.
547To how many works were the labels related to literary currents assigned in Bib-ACMé and Conha19?445 In the whole bibliography, there are only six different labels of literary currents. The ranks of the subgenre labels related to literary currents are the same for the bibliography and the corpus. Of the works that are associated with a literary current, most were labeled as “novela romántica”, followed by “novela realista” and “novela naturalista”. Three other subgenre labels related to literary currents occur but do only play a minor role from a quantitative point of view: “novela modernista”, “novela verista”, and “novela clasicista”. Comparing Bib-ACMé and Conha19, realist and naturalistic novels are relatively more important in the corpus than in the bibliography. Regarding the sources for the labels related to literary currents, literary-historical sources and implicit signals play the most important role.446
548As with thematic subgenres, multiple assignments also occur with literary currents. All the novels that were labeled as naturalistic novels were also marked as realist novels here because Naturalism is considered a current that evolved from and is closely related to Realism, and there are literary-historical sources for Spanish-American novels that do not differentiate clearly between the two. On the other hand, realist novels are not automatically also considered naturalistic novels, so the label “novela naturalista” is a more specific marker. Furthermore, there are eight novels in the bibliography, seven of which are also in the corpus, with the labels “novela romántica” and “novela realista” in combination.447 Three novels in the bibliography and two in the corpus are labeled both as “novela romántica” and “novela naturalista”.448 Concerning the multiple labels for literary currents, it must be remarked that it was not always easy to evaluate the literary-historical sources because the influences of several different literary currents in the works are often mentioned. Very differentiated descriptions are not fully represented in the subgenre labels. Instead, the main labels that were mentioned in the literary-historical sources were collected, for instance, the heading of a chapter in which a novel is included or the dominant literary current to which it is attributed in the source.449 Multiple labels were only assigned where different literary historians classified a novel differently or where works are clearly and repeatedly described as representatives of several currents.450
549As the literary currents are related to literary periods, looking at the publication dates of the novels that were labeled as belonging to a certain current can contribute to clarifying the question of when the different currents dominated and replaced each other. To this end, the distribution of works in the bibliography over the years per current is analyzed here, considering the publication date of the first known edition.451 The analysis confirms several aspects that have been highlighted in literary-historical literature regarding the periodization of Spanish-American novels belonging to specific literary currents. First, it can be confirmed that different currents that followed each other temporarily in Europe were in vogue simultaneously in Spanish America. For instance, the majority of the naturalistic novels were published at the same time as the realist novels, approximately between 1880 and 1900.452 Furthermore, the novela modernista came up approximately at the same time as the other currents of the late nineteenth century, around 1890. That the Romantic novel was a phenomenon that persisted during the whole century is also confirmed by evaluating the publication dates of the novels that have been labeled as romantic.453 The earliest works classified as novela romántica were published in 1836, and the latest one in 1905.454 The majority of the romantic novels was published between 1860 and 1886, though. The simultaneous publication of romantic and realist novels can also be attested.455 Moreover, the 1880s, which have been described as a turning point regarding the prevalence of literary currents (Rössner 2007, 200Rössner, Michael. 2007. Lateinamerikanische Literaturgeschichte. 3rd ed. Stuttgart, Weimar: J.B. Metzler.; Varela Jácome [1982] 2000, sec. 3Varela Jácome, Benito. (1982) 2000. Evolución de la novela hispanoamericana en el siglo XIX (en formato HTML). Alicante: Biblioteca Virtual Miguel de Cervantes. https://www.cervantesvirtual.com/nd/ark:/59851/bmct14z8.), can be confirmed as the decade in which the proportions of romantic novels versus novels of other literary currents shifted. However, based on Bib-ACMé, this shift can be dated more precisely here. Three-thirds of the romantic novels were published up to 1886, and three-thirds of the realist and naturalistic novels from 1888 and 1887 onwards, respectively. So instead of the year 1880 itself, 1887 is the year with a quantitative move from romantic to post-romantic currents.
550Concerning categorization tasks, the literary-historical labels are suitable for standard classification because the number of different classes is manageable, and apart from the realist-naturalistic relationship, multiple labels are the exception. At least the groups romantic versus realist-naturalistic are both represented with many members. One useful application would be to train a model with the novels in the corpus that have labels related to literary currents and use the model to also label the 55 works for which no such label was found.
551The next level of subgenre labels analyzed is related to the mode of representation. In Bib-ACMé, 556 works (67 %), and in Conha 19, 188 works (73 %) have a label related to the representational mode. Compared to the previously examined levels, in Bib-ACMé, these are fewer works than those with thematic labels but more than with labels related to literary currents. For Conha19, the proportion of works with a label related to the mode of representation is comparable to those with a label related to literary currents but less than the proportion of works with thematic labels. In the bibliography, 45 different labels belong to this level. Of these, 17 are assigned to at least five works.
552The distribution of the top labels on this discursive level is quite different from the one of literary currents and themes, though, because the general label “novela” is by far dominating.456 It is assigned to 49 % of the works in the bibliography and to 52 % of the works in the corpus. In the bibliography, also the labels “memorias” (assigned to 7 % of the works), “episodios” (7 %), “drama” (3 %), and “historia” (3 %) have a certain, although minor importance. In the corpus, labels that are assigned to at least 3 % of the works are “episodios”, “drama”, “memorias”, “cuento”, “historia”, and “cuadros”, but compared to the bibliography, “memorias” and “episodios” are underrepresented.
553The sources for the labels referring to the representational mode are almost exclusively explicit historical signals.457 Only the terms “memorias” and “crónica” were also part of the literary-historical discussion of the novels.
554On this level of subgenre terms, multiple assignments occur as well. In the bibliography, 123 works – i.e., 15 % of all the works in the bibliography and 22 % of the works with labels on this level – have combinations of several labels related to the mode of representation. In the corpus, there are 42 works with more than one label of this kind, which corresponds to 16 % of all the works in the corpus and 22 % of the corpus works with labels on this level. The top 5 combinations in the bibliography and the corpus are summarized in table 25.458
| Rank | Bib-ACMé | Conha19 | ||
|---|---|---|---|---|
| Labels | Number of assignments | Labels | Number of assignments | |
| 1 | novela,
memorias |
39 | novela,
memorias |
6 |
| 2 | novela,
episodios |
33 | novela,
episodios |
5 |
| 3 | novela,
episodios, memorias |
19 | novela,
cuadros |
4 |
| 4 | novela,
historia |
14 | novela,
crónica |
3 |
| 5 | novela,
historia, episodios |
7 | novela,
historia |
3 |
555In the bibliography, even the triple combinations “novela-episodios-memorias” and “novela-historia-episodios” are found repeatedly because they occur in series of historical novels, in particular the “Episodios nacionales mexicanos” by Enrique Olavarría y Ferrari. In the corpus, on the other hand, the combinations “novela-cuadros” and “novela-crónica” are more important.
556All in all, only the presence or absence of the label “novela” is meaningfully analyzable with a quantitative approach. Beyond that, the wide range of different labels related to the mode of representation lends itself more to a qualitative analysis of the respective novels.
557In total, there are ten different subgenre labels in the bibliography that involve the relationship of the text to reality. In Bib-ACMé, 279 works (34 %) have such a label, and in Conha19, 95 works (37 %), so this discursive level is quantitatively less relevant than thematic labels, labels related to literary currents, and labels related to the mode of representation.
558As with subgenre labels related to the mode of representation, also the labels related to the mode of reality are quantitatively dominated by a single label, the “novela histórica”.459 In Bib-ACMé, 29 % of all the works have that label, and in Conha19, 32 %. In the bibliography, also the “leyenda” plays a role, as there are 44 works with that label, which corresponds to 5 % of all the works. On the other hand, in the corpus, the label “leyenda” is underrepresented. There are only a few instances of the other labels associated with the mode of reality. In addition, the variety of labels in this group is much smaller than for the mode of representation.
559The sources for the different labels related to the mode of reality are mainly explicit signals, but for the historical novel also implicit signals and literary-historical sources are important. Other labels that are a subject of discussion in literary histories are the “novela científica” and the “novela de misterio”.460
560Clearly, in the novels, the historical perspective is the most important aspect of the relationship between the text and reality, at least when subgenre labels are evaluated. On this discursive level, only the opposition of historical versus non-historical novels is suited for a comparative, quantitative analysis of subgenres.
561In the bibliography, there are 25 different subgenre labels related to linguistic, geographical, and socio-cultural identity. These were assigned to 273 works (33 %) in Bib-ACMé and 101 works (39 %) in Conha19 so that the share of works having such a label is comparable to the ones with a label related to the mode of reality. Nevertheless, the variety of identity labels is larger, and this level is less dominated by a single label.461
562The most important identity label is the general term “novela original”, carried by 113 (14 %) of the works in the bibliography and 36 (also 14 %) of the works in the corpus. It is followed by the labels related to the three selected countries (“novela mexicana”, “novela cubana”, “novela argentina”), by other general labels (“novela nacional”, “novela regional”), and by labels referring to the American continent (“novela americana”, “novela criolla”, “novela india”). Among the various identity labels of minor importance, there are several related to the countries’ capitals (“novela bonaerense”, “novela porteña”, “novela habanera”)462, to specific regions or cities in Mexico or Cuba (“novela yucateca”, “novela suriana”,463 “novela tapatía”,464 “novela de Tabasco”, “novela camagüeyana”), and to Mexican indigenous people (“novela mixteca”, “novela azteca”). Furthermore, there are references to European regions and culture (“novela romana”, “novela franco-argentina”, “novela siciliana”, “novela kantabro-americana”, “novela andaluza”). Comparing the bibliography and the corpus, the label “nacional” is underrepresented in the corpus, while the labels referring to the three countries of Argentina, Mexico, and Cuba are overrepresented. Apart from the “novela regional”, the sources of all the identity labels are explicit signals.465
563Combinations of identity labels are not very frequent. Only the label “episodios nacionales mexicanos”, containing both the identity label “nacional” and “mexicano”, occurs 24 times in the bibliography and two times in the corpus. The label “novela original” is also combined with other identity markers, but only a few times. There are two “novelas cubanas originales”, one “novela americana original”, and one “novela mexicana original”, both in the bibliography and the corpus.466
564In a quantitative approach, the subgenres related to the linguistic, geographic, and socio-cultural identity could be analyzed in the following setups:
565It is suggested here that one could concentrate on the most frequent identity label, “novela original”, and analyze the other labels as groups combining several individual labels that refer to a similar spatial context. In the corpus, a group of 36 “novelas originales”, 67 novels with a label referring to the American context, and 30, 22, and 9 novels with a label related to the Mexican, Cuban, and Argentine context, respectively, can be compared to the other novels in the corpus not carrying such labels.469
566Fourteen different subgenre labels in Bib-ACMé refer to a medial aspect of the novel. In the bibliography, only 47 novels (6 %) carry a label of this group, and in the corpus, only 23 novels (6 %), which is marginal from a quantitative point of view.
567In the bibliography, the three most frequent medial labels are “escenas” (12 novels), “cuadros” (11 novels), and “páginas” (8 novels).470 In the corpus, they are “cuadros” (8 novels), “páginas” (3 novels), and “esbozos” (also 3 novels). Some of the subgenre labels related to medial aspects are connected to novels of customs but also to social, realist, and naturalistic novels, as in the following titles:
568Others are associated with sentimental novels, for example, “Amalia. Páginas del primer amor” (1891, MX) by José Rafael Guadalajara or “Páginas íntimas” (1895, MX) by Manuel Blanco. However, there are also historical or political novels with labels referring to a medial aspect, for instance, “Campaña y Guarnición. Escenas de la vida militar” (1892, AR) by E. Mayer, “El Señor Gobernador. Breves apuntamientos sobre cosas nacionales del siglo pasado” (1901, MX) by Manuel H. San Juan, or “Vía Crucis. Páginas de ayer” (1910, CU) by Emilio Bacardí Moreau. The sources of the labels associated with medial aspects are almost exclusively explicit signals.471
569Because the frequency of these labels is low, especially in the corpus, they are not examined further in a quantitative setup but only considered for interpreting the results of other analyses.
570Subgenre labels related to the attitude the author or narrator has towards what is presented in the novel are not frequent. In the bibliography, five different labels of this level were found. In Bib-ACMé, they are assigned to 57 (7 %), and in Conha19, to 32 (13 %) of the works.472
571The main subgenre in this group is the political novel, which is at the same time a thematic subgenre label. In the bibliography, there are 51 political novels, and in the corpus, 28. Besides the political novel, also the “novela satírica” is a label that has been assigned to novels by literary historians, but only four times in the bibliography and three times in the corpus. The other three labels, “reseña”, “novela festiva”, and “elegía”, all go back to explicit signals and occur only once each. This group of labels is not analyzed further because of its minor importance.
572The last group of subgenre labels considered here are the ones related to the intention the author or narrator pursues with the novel. In the bibliography, there are 13 different labels of this kind. In Bib-ACMé, 34 works (4 %), and in Conha19, 15 novels (6 %) carry an intention label, making this discursive level the least important in quantitative terms.473
573In the bibliography, there are four labels related to the intention that are assigned to at least five works, each: the “novela moralista” (13 works), “estudio” (7 works), “novela humorística” (6 works), and “novela didáctica” (5 works). In the corpus, “estudio” is the most frequent with five works, and the other labels only occur three times or less. The “novela moralista” and the “novela didáctica” are subgenres that are a topic in literary histories, but the other labels all have explicit or implicit signals as their source. Roughly, the different labels of this group can be classified into labels of entertainment (“novela humorística”, “novela cómica”, “entretenimientos”, “novela curiosa”, “juguete”, “comedia de carácter”, “novela de horrores”) and instruction (“novela moralista”, “estudio”, “novela didáctica”, “novela de propaganda”, “lecturas”, “novela enciclopédica”). Because this last group of subgenre labels is small, it is not examined further in the following analyses.
574Reflecting upon the empirically driven discursive model of subgenre labels that was used here to organize the subgenres contained in the bibliography and the corpus and which served to get an overview of their quantitative distributions, it can be concluded that the model is helpful in enhancing the comparability of subgenre labels. Generic labels usually refer to certain semiotic or discursive levels of a literary work, which can be quite different, for example, the spatial context versus the syntactical realization of a work, and which cannot be compared directly in a useful way.
575The specific model was created based on the metadata collected for Bib-ACMé and Conha19 and helped determine which discursive levels are relevant from a quantitative point of view. Applying it to the metadata and evaluating the resulting quantities clarifies which levels have a certain weight, either regarding the variety of labels or the number of labels assigned to the novels. The relevance of some levels was expected because they are traditionally a focus of critical concern: thematic labels and labels related to literary currents. Other levels – the mode of representation, the mode of reality, and identity – resulted in having a certain quantitative significance, as well. This highlights perspectives on subgeneric terms that have not been discussed widely so far and that are mainly derived from explicit historical subgenre signals. It has to be analyzed if and to what extent the historical practices of assigning such labels to the novels actually correspond to textual patterns. In addition, some levels are dominated by individual subgenre labels, which trigger the overall quantitative importance of the respective level, for example, the general term “novela” on the level of the representational mode or the “novela histórica” on the level of the reality mode. All in all, it became clear that compared to the overall variety of subgenre labels, relatively few of them are very frequent.474
576In Bib-ACMé, 89 labels, which corresponds to 72 % of all the different labels in the bibliography, are only assigned to up to 9 works. In Conha19, this is true for 73 labels, which is 81 % of all the different labels in the corpus. In the bibliography, only 13 labels are assigned to 50 works or more.475 Regarding the sources of labels, there are 108 different explicitly signaled labels and 34 different literary-historical labels. All these numbers are based on normalized terms, so variances in spelling, formulation, and syntactic constructions are not causing the broad range of subgenre labels. Following these numbers, it can be assumed that in the historical practice of explicitly labeling novels, in particular, creativity and the emphasis on individuality are important factors besides the wish to mark a work as belonging to some established or widely practiced subgenre. In literary-historical approaches, on the other hand, subgenres are studied independently of their quantitative weight in the whole production of novels. In comparison, a digital quantitative approach to the subgenres sets different focuses of analysis, or rather, it is only usefully applicable to a subset of the whole range of generic signals and classifications.
577Some aspects of the nature of generic terms that complicate classificatory and comparative studies of subgenres are not solved by applying the discursive model. Actually, the semiotic and discursive models of generic terms are above all descriptive models and do not claim to tackle these issues:
578When classificatory tasks are designed based on the subgenre labels in the bibliography and the corpus, which have a collective background, are potentially semantically multifaceted, historically bound, and neither exhaustive nor unique, and when these tasks are based on how the labels are ordered in the discursive model of subgenre terms, this constitutes a simplifying choice of perspective on a more complex system of generic relationships. To conclude this section of metadata analysis of the subgenres, only the constellations of labels selected for further analysis are presented in more detail, i.e., differentiating the overviews also by country, time period, and related to corpus-specific metadata and characteristics of the texts. This is done in the following subchapters.
579In the following, the two discursive levels of subgenre labels that were chosen for text analysis are analyzed further on the metadata level: primary thematic subgenres and primary literary currents. In the text analysis part, the setups for thematic labels are further reduced by concentrating on the three most frequent subgenres (novela histórica, novela sentimental, and novela de costumbres), but in the following section, also the less frequent ones are examined in terms of metadata.
580This chapter analyzes the proportions of novels with a particular primary thematic subgenre label in Bib-ACMé and Conha19. Here, only the top primary thematic subgenres are analyzed in detail, summarizing the remaining ones as “other”. Primary thematic subgenres are considered “top” if they cover at least 5 % of the works in the corpus. Although the proportion may be higher in the bibliography, the coverage in the corpus is decisive because, in the end, only the full text of the novels in the corpus is analyzed. First, the general proportions of novels having a certain primary thematic subgenre label in the bibliography and the corpus are assessed.476 This general overview serves as a reference point for the overviews differentiating by further parameters such as country, time period, etc. In Bib-ACMé, 16 % of the works do not have any thematic subgenre label, whereas in Conha19, all the works were labeled thematically. In both resources, historical novels are most frequent, followed by sentimental novels. In the corpus, novels of customs, social, and political novels have more weight than in the bibliography.
581Next, the primary thematic subgenres are analyzed by the three countries Mexico, Argentina, and Cuba.477 As for historical novels, in the bibliography, they are overrepresented in the Mexican works (38 %). In the Argentine novels, and even more in the Cuban ones, historical novels are underrepresented (19 % and 12 %, respectively). In the corpus, the distribution of historical novels is more balanced by country. However, even there, the Mexican works have a greater proportion of historical novels (32 %) than the Argentine (23 %) and Cuban ones (20 %). Sentimental novels are slightly underrepresented in the Mexican and Argentine works contained in Bib-ACMé (19 %, respectively), and clearly overrepresented in the Cuban works (33 %). Also for this subgenre, the distribution is a bit more balanced in the corpus. The novels of customs are proportionally overrepresented in the Cuban works in the bibliography and also in the corpus. Social novels are above average in Argentine novels and below average in novels of other countries, both in Bib-ACMé and Conha19. Finally, in the bibliography, political novels are a bit overrepresented in the Argentine works and underrepresented in the Mexican and Cuban works, slightly in the first and more in the latter case. In the corpus, in contrast, there are relatively more political novels from Mexico, while the Argentine novels correspond to the average, and for Cuba, there are no political novels at all. So regarding the distribution of primary thematic subgenres by country, the differences between Argentine, Cuban, and Mexican works that are visible in the bibliography are, for the most part, also reflected in the corpus, where they are balanced out a bit. In summary, there are more historical novels from Mexico, more sentimental novels and novelas de costumbres from Cuba, and more social novels from Argentina. In the following, the distribution of primary thematic subgenres is given per decade, for Bib-ACMé and Conha19, respectively.478
582The most important point to conclude for the bibliography is that all of the top primary thematic subgenres occur in almost all of the decades. The political novel is missing in the 1830s and 1840s, and the social novel in the 1840s. In the corpus, there are some more decades without works of individual subgenres, especially the first and last decades. There is only one novel of customs from the 1830s and one novel of a different subgenre. There are only three novels from the 1910: one political novel, one social novel, and one historical novel. In the more central decades, no political novel is included in the 1840s, 1860s, and 1870s. No social novel is present in the 1840s and 1870s. In contrast, historical novels, sentimental novels, and novels of customs are represented in all the central decades of the corpus.
583Regarding the relative amount of different subgenres over the decades, in the bibliography, the proportion of historical and sentimental novels is higher up to the 1860s. After that, especially the social novel gets more significant. When compared to the bibliography, in the corpus, especially the 1860s stand out as a decade with an over-proportional number of historical novels and the 1890s with an above-average number of social novels. The change of proportions of primary thematic subgenres over time becomes clearer if the two periods before 1880 and in or after the year 1880 are compared.479
584In Bib-ACMé, in particular, the number of sentimental novels is lower after 1880 (17 % instead of 28 % before), and the number of social novels higher (14 % instead of 6 %). The political novel, which is in general not very frequent, also raises from 1 % of the works before 1880 to 4 % after that year. Furthermore, the share of works without any thematic subgenre label is considerably higher in the later period (19 % instead of 10 %). On the other hand, the differences between the proportion of historical novels and novels of customs are not very big between the two periods (4 % in the case of the historical novels and 3 % for the novels of customs). In general, and regardless of the shifts of proportions, the absolute number of novels of all the primary thematic subgenres is higher in the second period than in the first one.
585In Conha19, in contrast, the absolute number of sentimental novels and novels with other subgenres drops for the period after 1880. On the other hand, the relative increase of social and political novels is even higher than in the bibliography. There is almost no change in the proportion of novels of customs between the two periods, but the relative importance of the historical novel drops more in the corpus than in the bibliography. It can be assumed that the change of proportions of the various thematic subgenres over time reflects the preferences of the different literary currents, which overlap and succeed each other during the nineteenth century. The romantic current is apparently more closely related to semantic and historical themes, and the realist and naturalistic novels to social and political topics. However, the historical novel persists as an important subgenre throughout the whole century, and also the novel of customs remains relevant. It is striking that the only two thematic subgenres that are frequently explicitly named in the novels’ subtitles, the novela histórica and the novela de costumbres, are the ones that are less subject to change in terms of relative quantities over time, which means that they are less bound to the dominant literary currents than the other thematic subgenres.
586In what follows, the distribution of primary thematic subgenres is analyzed in relationship to corpus-specific metadata and text characteristics, namely the prestige of the texts, the narrative perspective, the continent and time period of the setting, and text length. The first of the corpus-specific aspects to be analyzed is the prestige of the texts.480 Historical novels are equally present both in high- and low-prestige novels. The sentimental novels, in contrast, are underrepresented among the high-restige novels and overrepresented in the low-prestige ones. Interestingly, of the novels of customs, relatively more are classified as high- than as low-prestige. The social novels are slightly overrepresented in the high-prestige group and the political novels in the low-prestige one. Especially in the latter case, the difference is not considered significant because of the comparatively low number of political novels in the corpus. It can be concluded that one of the primary thematic subgenres, the sentimental novel, is clearly marked as having a low-prestige branch, but none of the other subgenres sticks out as a particular high-prestige subgenre.
587Considering the narrative perspective, the great majority of historical novels are written in the third person. Social novels also primarily have a third-person narrator. The first-person narrator is most frequent in sentimental novels but also overrepresented in the group of political novels. In the novels of customs, both narrative perspectives are almost equally in use. It is noticeable that 20 % of the novels with a first person narrator have a primary thematic subgenre that is part of the “other” group, so apparently, this perspective is favored in some of the subgenres that are less frequent.481
588For the continent of the setting, there are also correlations with some of the primary thematic subgenres.482 Almost half of the novels set in Europe (46 %) are sentimental novels. Novelas de costumbres rarely have a European setting – they make only up 4 %. The political novels are exclusively set in America. There are social novels set on both continents, but also for that subgenre, the American setting is more prominent. Only the proportion of historical novels is almost the same for the American and the European setting. A hypothesis that follows from this is that European models of sentimental novels were more often just copied and that models of other subgenres were more often adapted and appropriated to reflect the local circumstances, or even that they developed more into independent varieties of the subgenres.
589Correlations between the different primary thematic subgenres and the time period of the setting become visible, as well.483 Obviously, most of the novels set in the past are historical novels (85 %), and there are no primarily sentimental or political novels in this group at all. Most of the novels set in the recent past are also historical novels (68 %), but here there are also some representatives of the other subgenres, in particular sentimental novels and novels of customs. Novels with a contemporary setting are led by the sentimental subgenre, novelas de costumbres, and social novels. However, also 7 % of the novels with a contemporary setting are primarily classified as historical novels, which shows how widely the concept of historicity was interpreted in the novels.
590Analyzing the lengths of the works of different primary thematic subgenres reveals that all the groups overlap.484 There are short novels among all the subgenres, and differences become only visible regarding the median and the variance of length. The longest novels are historical novels, followed by novels of customs and sentimental novels. Apart from the outliers, the subgenres with the highest median length are historical novels (89,000 tokens) and social novels (57,000 tokens), and the ones with the lowest sentimental novels (40,000 tokens) and political novels (43,000 tokens). The novels of customs lie in between with a median of 48,000 tokens, so the median sentimental and political novels are less than have as long as the median historical novel.485 A test for significance shows that the difference in length is significant for the historical versus all other types of thematic subgenres, but not for the other pairs of subgenres.486 Analyzing the two central quartiles, the variety of length is greatest for historical novels (50,000 to 139,000 tokens) and novels of customs (34,000 to 94,000 tokens) and lowest for social novels (37,000 to 76,000 tokens). The ratio of variances and, thereby, the difference in statistical variance between selected pairs of subgenres is greatest for the historical versus the political novel, the historical versus the social, and the historical versus the sentimental novel and lowest for the sentimental novels when compared to the novels of customs.487 As with the development of the number of works associated with the primary thematic subgenres over time, also in terms of text length, the two explicit subgenres, novela histórica and novela de costumbres, stick out as the subgenres with the longest novels on the one hand (considering the outliers and upper fences) and the greatest variety of length on the other hand (in terms of the ranges of the two central quartiles). It can be hypothesized that these are signs of long-lived subgenres for which there is historical variability and for which experimentation to the extremes has taken place. When statistical differences in the distributions of lengths are considered, the historical novel is the one that is significantly longer than the other types of thematic subgenres and, at the same time, the one with a comparatively bigger variance in text length.
591In this chapter, the primary literary currents to which the novels in the bibliography and the corpus were assigned are analyzed.488 In the bibliography, the literary current is only known for half of the works (49 % or 405 novels). Normally, this information is available from literary-historical accounts of the novels and not from explicit historical subgenre labels. As many of the novels in the bibliography have not been the focus of critical literary-historical work, this information is missing. In the corpus, the number of novels for which the literary current is known is much higher (79 % or 201 novels), which again shows that the corpus represents works that are better known and more canonized than the works in the whole bibliography.489 Here, only the primary literary currents assigned to the novels are analyzed. Secondary literary currents are not taken into account here. Examples are novels that are borderline cases or mixtures of romantic and realist novels but also all naturalistic novels that can as well be understood as realist novels in a general sense.
592In the bibliography, the largest group of novels by literary current are the romantic novels, with 32 % or 263 novels. This is also the case in the corpus, where the romantic novels have a share of 45 % or 116 novels. In the bibliography, the amount of realist and naturalistic novels is equal (8 % or 66 novels each), while in the corpus, there are a bit more naturalistic works (18 % or 45 novels) than realist ones (14 % or 35 novels). Other literary currents only have a minor quantitative importance in both the bibliography and the corpus. Compared to the bibliography, the relationship between romantic novels on the one side and realist and naturalistic novels on the other is more balanced in the corpus. However, it is difficult to say if this turns the corpus further away from the population of novels or not because the literary current is unknown for so many novels in the bibliography.
593When the proportions of literary currents are viewed by country, some differences become visible.490 In Bib-ACMé, the share of novels for which the literary current is unknown is similar in the three countries, but in the corpus, it is highest for the Cuban novels and lowest for the Mexican ones, with the Argentine novels in-between. The higher number of unknown cases for Cuba reflects that apart from a few very well-known works, novels from that country appear to be less studied. Regarding the distribution of the different literary currents by country, in the bibliography, approximately one-third of the novels are romantic ones, also by country. In Conha19, however, the proportion of romantic novels is bigger for Mexico (55 %) than for the other two countries. Most realist novels come from Mexico, in the bibliography, and also in the corpus. The naturalistic novels have the most weight in Argentina, both in Bib-ACMé and Conha19.
594Next, the distribution of the novels’ primary literary currents over time is analyzed, considering the number of works per decade in the bibliography and the corpus, respectively.491 What becomes clearly visible is that the romantic novel is a phenomenon that persisted throughout the whole nineteenth century. It was the dominant current up to the 1870s and only gradually gave way to the other currents in the following decades. The first realist and naturalistic works are found in the 1860s and 1870s, but it was from the 1880s onwards that these two currents gained more weight. If one compares the bibliography and the corpus, the proportions are similar in both, only that there are relatively more realist and naturalistic novels in the corpus. If only the relationship between realist and naturalistic novels is examined, the latter are a bit overrepresented in the corpus in the 1890s and 1900s. Considering the period before and after 1880,492 the dominance of the romantic novel in the early period again stands out, both in Bib-ACMé and Conha19. Moreover, even after 1880, the number of romantic novels is higher (in the bibliography) or comparable (in the corpus) to the amount of either realist or naturalistic works. Concerning the number of works for which the literary current is unknown, it is very high in the bibliography for the period after 1880, amounting to 59 % of all the novels. In the corpus, the proportion of works with unknown currents is more balanced before and after 1880. As was seen before in chapter 4.1.3.1, where the general number of works was assessed independently of the subgenres, the number of works doubled from the 1870s to the 1880s. For the 1880s and 1890s, the corpus contains approximately 30 % of the novels that are registered in the whole bibliography, but for the 1900s, only 20 %. So the high proportion of novels after 1880 in Bib-ACMé for which the literary current is unknown shows that there is a mass of works that is still mostly unexplored.
595We now turn to the analysis of the corpus-specific metadata, starting with the proportions of high- and low-prestige novels in Conha19 for the different literary currents.493 The most striking difference is the higher proportion of novels without a literary current label in the low-prestige group, which is at 34 %, compared to 16 % in the high-prestige group. This result is mainly due to the way that the prestige of the novels was determined. Only works of which at least one new edition was published between 1960 and 2020 were considered high-prestige novels. The high proportion of novels without known literary current in the low-prestige group is just another perspective on them as a group of texts which has been largely forgotten or has not been investigated in the last 60 years.494
596The next aspect that is analyzed is the kind of narrator that the novels related to the different literary currents have.495 In general, the third-person narrator is much more frequent in the corpus than the first-person narrator: there are 44 novels (17 %) with a first-person narrator and 212 novels (83 %) with third-person narrator. Interestingly, the proportion of realist novels in the first-person narrator group is considerably higher than in the third-person group. On the other hand, naturalistic novels are overrepresented in the third-person group, and also the romantic novels have a higher proportion in the latter one. In his overview of the history of Latin-American literature, Dill introduces the realist novel as follows: “Die Realität wurde nicht costumbristisch-dokumentarisch kopiert, vielmehr mit literarischer Inszenierung ein Ähnlichkeits- oder Realitätseffekt (effet du réel) durch einen heterodiegetischen Erzähler erzeugt, der dem impliziten Leser die neue Gesellschaft und adäquate Verhaltensweisen modellierte” (Dill 1999, 159Dill, Hans-Otto. 1999. Geschichte der lateinamerikanischen Literatur im Überblick. Stuttgart: Reclam.). So the third-person narrator is usually seen as typical for the realist novel, but the overview of the novels in Conha19 suggests that there is a subgroup of realist novels narrated in first person and that the choice of this narrative perspective is a factor that differentiates the realist from the naturalistic novel, where the third person is proportionally more important. Checking which ones are the realist novels with a first-person narrator reveals that they belong to several different thematic subgenres: the sentimental novel, the historical novel, the novel of customs, and the political novel, so one specific type of thematic subgenre is not responsible for the number of realist novels with first-person narrator. In addition, they were written by different authors from the three countries.496
597The next property to be analyzed is the continent of the novels’ setting.497 Comparing the proportions of novels with an American and European setting reveals that the romantic and also the realist novels are preponderant for the American setting. Naturalistic novels have a similar proportion in both groups, which means that the European setting is relatively more important in them when compared to romantic and realist novels. Apparently, the French origin of the naturalistic current had an influence on the choice of the setting in some cases. Nevertheless, the numbers of the continent of the setting must be interpreted with caution because the great majority of the novels are set in America (90 %, 231 novels) and only a few in Europe (9 %, 24 novels).498 Furthermore, the numbers for Europe are biased because the proportion of novels for which the literary current is not known is considerably higher than in the case of an American setting. Here there is a correlation with the countries of origin of the novels because knowledge about the literary current is missing for many Cuban novels, and novels from Cuba are also the ones that have a European setting more often than novels from Argentina or Mexico.
598How does the time period of the setting relate to the literary currents? Clear tendencies are visible in this respect:499 the romantic novel has high proportions in all three categories but is overrepresented in the groups of novels with a setting in the past or recent past. The realist novel primarily has a contemporary setting or one in the recent past, and the naturalistic novel is, above all, set in the present. That the romantic novel is inclined towards the past is in line with the fact that the historical novel was a very popular thematic subgenre in that current. However, the results also show that the romantic novel is a multi-faceted phenomenon because all the different time periods of the setting are covered by it to a significant extent. That the naturalistic novel primarily has a contemporary setting confirms its role as the type of novel that served to depict the process of social, economic, and technological modernization going on in the Spanish-American countries in the last decades of the nineteenth century. In terms of text style, the preferences for certain time periods of the setting that the novels associated with the different literary currents have might influence, for example, the usage of temporal expressions or verb forms, which is an aspect that needs to be investigated further.
599Finally, the differences in text length between the novels of the three main literary currents are analyzed.500 The romantic novels have a median length of 66,000 tokens, the realist novels of 56,000, the naturalistic novels of 51,000, novels with other literary currents of 62,000, and novels with an unknown literary current of 42,0000 tokens.501 Of most interest are the differences between the romantic, realist, and naturalistic novels because the group of novels with another literary current only consists of 5 novels, and the “none” group is probably mixed. A test for significance shows that the differences in length between the romantic, realist, and naturalistic novels are not statistically significant, though.502 Even if the differences in median text length are not significant, the group of romantic novels has a bigger variance in length than the other two currents, which are more similar regarding the variation of the novels’ length.503 That the length of romantic novels varies more is plausible because the group of romantic novels in the corpus is bigger (116) than that of the realist (35) or naturalistic (45) novels, but it can also be a sign of the variability of romantic novels in themselves. Romantic novels can be part of several distinct thematic subgenres, of which, for example, historical novels can be very long and sentimental novels are usually shorter. In addition, romantic novels spread over the whole nineteenth century, whereas the realist and naturalistic novels were concentrated in the decades 1880 to 1910. The general comparison of text length by decade that was made in chapter 4.1.3.2 above showed that the variability of text length was lowest from the 1870s to the 1890s, and very long novels were the exception in these decades. This suggests that the form of the novel in terms of length was more stabilized in the last decades of the nineteenth century. In Spanish America, romantic novels participated in all the phases that the novel as a genre underwent in the nineteenth century, so they were variable, whereas the realist and naturalistic novels were anchored in a more precise literary-historical moment. That the variance of the length of the three major currents is smallest for the naturalistic novels can be interpreted as a sign for the relatively uniform and defined form of the novels participating in that subgenre.
600Finally, the results of the metadata analysis on the novels in the bibliography and the corpus will be briefly summarized and evaluated here in overview. All in all, the proportions of works in the corpus and the bibliography are very similar in most aspects. In the corpus, some balancing can be noted, for example, concerning the distribution of subgenres in general or by country. This means that the corpus deviates from the distributions in the bibliography to mitigate certain tendencies of imbalance and to achieve a dataset that is more suited for an analysis of subgroups, even if it doesn’t represent the proportions of the sampling frame closely. In addition, there are effects that are due to the fact that the sources for the corpus are limited because specific works are difficult to access in digital format. As a whole, the corpus is not entirely balanced in all its aspects. Its closeness to the distributions of subgroups in the bibliography is bigger than their balance in terms of similar numbers in the corpus itself, for example, by subgenre. The overviews of the subgenres selected for analysis highlighted which metadata and also textual factors are connected to the subgenres. They pointed out some interdependencies (e.g., regarding narrative perspective or text length). Some influencing factors only became visible from a single perspective, whereas others manifested themselves repeatedly, such as the very long Mexican historical novels, for instance.
601Such an analysis of metadata in connection with the subgenres is of interest in itself, but it also provides useful background knowledge for further textual analysis to be able to evaluate possible biases in the results. Especially, differences between the works of the three countries and also some chronological trends became visible. When conducting analysis on the texts, it must be kept in mind that the sampling frame and also the corpus are not entirely balanced datasets – instead, there are many different factors influencing each other and some asymmetries that are already characteristic of the underlying set of novels. In the next chapter, the textual features used for text analysis and the methods used to categorize the novels by subgenre are presented.
602In this chapter, text analyses are carried out with the novels of the corpus based on two different sets of text features. The first set consists of general features derived from the most frequent words in the corpus, and the second set consists of topic features created with topic modeling. In chapter 4.2.1, it is explained what the two main types of features are and how they were created. In the second part of this chapter (4.2.2), two different methods are used to categorize the novels. First, statistical classification is employed to classify the novels by subgenre. Three thematic subgenres (novela histórica, novela sentimental, and novela de costumbres) as well as three literary currents (novela romántica, novela realista, novela naturalista) were chosen for the analysis as the quantitatively most relevant groups in the corpus. The classification methods that were used and the results of the analysis are discussed in chapter 4.2.2.1. A family resemblance analysis is realized in chapter 4.2.2.2, and a proposal is made for how the calculation of text similarities, network analyses, and community detection can be used to that end. In the discussion of the results, selections must be made as the amount of data that results from all the different analyses is huge. The overall results are presented in every case, but the study of individual subgenres and novels is only deepened in some cases.
603Two main types of features were selected as a basis for the genre categorization tasks: general and semantic features. The general features include different sets of tokens that are most frequent in the corpus (words, word n-grams, and character n-grams). They are called “general” here because, in their basic forms, these features are not filtered based on their linguistic characteristics, which means that all types of tokens are included independently of specific grammatical or semantic properties that they might have. The second feature group is called “semantic” because the feature sets are built on lexical units and on tokens that convey meaning by the way they occur together in the texts. In particular, the method of topic modeling is used. The general features are presented in chapter 4.2.1.1, and the semantic features are outlined in chapter 4.2.1.2.
604In digital literary and stylometric studies, the features that are termed “general” here are commonly understood as “stylistic” features in a narrow sense, meaning that they are suitable to differentiate between different writing styles of authors, periods, or genreswithout being too closely connected to the contents of the texts. This is especially the case when the number of most frequent items chosen is limited, for example, to a few hundred, so that mainly function words are included (Burrows 2002, 268Burrows, John. 2002. “‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship.” Literary and Linguistic Computing 17 (3): 267–287. https://doi.org/10.1093/llc/17.3.267.; Juola 2006, 33–34Juola, Patrick. 2006. Authorship Attribution. Boston, Mass.: Now Publishers.; Stamatatos 2009, 539–542Stamatatos, Efstathios. 2009. “A Survey of Modern Authorship Attribution Methods.” Journal of the American Society of Information Science and Technology 60 (3): 538–556. https://doi.org/10.1002/asi.21001.).504 For the purpose of text classification, the use of such features is often considered a good baseline against which other approaches can be compared because they have often been tested and proved successful for a variety of tasks, also for the classification of texts by genre (Hettinger et al. 2016 Hettinger, Lena, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2016. “Classification of Literary Subgenres.” In DHd2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts. Universität Leipzig 7. bis 12. März 2016, 160–164. Duisburg: nisaba verlag. https://doi.org/10.5281/zenodo.4645368.). In this dissertation, the general features are used for both reasons, to cover elements of style in the narrower sense and to use the results based on this feature type as a starting point for the evaluation of other feature types. However, precisely because general features in the high-frequency spectrum are usually only weakly semantically loaded, their interpretation can be more difficult than for inherently semantic features.
605The semantic features were chosen as an alternative that is easier to inspect and that can be linked to expectations about known subgenres of the novel, especially the thematic ones. A love theme, for example, is assumed to occur in sentimental novels and also often in the ones belonging to the romantic current. Historical novels are expected to include topics related to political events or military confrontations, and novels of customs descriptive topics that represent different spheres of life.505 These examples show that hypotheses about connections between specific subgenres of the novel and different kinds of semantic characteristics of the texts are easily formulated. The usage of semantic text features aims to make it possible to check whether or not such assumptions hold when a large number of texts is analyzed quantitatively, but it also enables the discovery of unexpected correlations. Although semantic features are more closely related to the contents of the texts than general token-based features, they can still be considered stylistic features in a wide sense because how a theme is developed in terms of topics in a text is a stylistic choice. This becomes clear when the relationship between the general literary concept of theme and the specific textual topic features is analyzed. In text-centered approaches, “theme” is usually defined as a non-surface element characterizing the underlying semantics of a narrative literary text and as an element that can be connected to linguistic manifestations in the text.506 Topic features, in contrast, serve to directly measure characteristics of the textual surface. These cues can subsequently be used to make inferences about higher-order semantic structures of the texts, which can be interpreted in terms of generic facets. So the literary theoretical concepts and the Natural Language Processing terms are different in the way the texts are approached. The NLP concepts have a more direct relationship to text style, as it is understood here.507
606This raises the question of how a common conceptual ground can be found for the literary-theoretical and the NLP terms. Here, no direct and specific digital modeling and formalization of literary theoretical concepts is intended. Such a mapping of concepts to the requirements of formal text analysis would need an extensive discussion of the formalization procedures and also the development of entirely new tools or at least advanced adaptations of existing ones.508 Instead, for the purpose of this dissertation, the problem is approached by assuming a loose connection between literary theoretical terms and existing terms employed in text mining, which is established by clarifying the differences and similarities. This is discussed in chapter 4.2.1.2 for the relationship between literary themes and topics. In the same way, only loose hypotheses are formulated regarding the relationships between definitions of subgenres of the novel and characteristics of the textual surface. The subgenres are not defined formally and are not directly linked to linguistic properties in a top-down approach. The main reason for this reserve to explicit modeling is that the assignment of the novels in the corpus to the subgenres has not been done on the basis of specific, unambiguous definitions but instead by collecting and interpreting generic signals and attributions of different kinds and provenience. A connection between the textual patterns found and the literary conceptions of the subgenres is explored ex-post, based on the analyses results. That way, mappings between textual evidence and generic categorizations emerge from mainly exploratory procedures and can be described as stylistic cues, stylistic traits, and generic facets.
607In the context of the analysis of subgenres of the novel conducted here, the cues are the feature values that turn out to be distinctive for a particular textual category, but the generic facets are not predetermined. Instead, in the case of classification, the cues are interpreted in terms of the subgenre labels that are associated with the text category to look for generic facets. In the analyses of family resemblance structures, it is examined to what extent the cues characterizing the text types found with different feature sets are related to the subgenres at all – on the different discursive levels that these are defined on. In parallel, connections to other determining textual and contextual factors are checked, e.g., the narrative perspective, the country of origin, or the period of publication. So instead of building a direct chain from theories about the subgenres and their properties to expected stylistic characteristics of the texts, the empirical findings are interpreted regarding their relationship to the subgenre labels and other influencing factors (which could turn out to be relevant facets). The hypothesis that is tested is of a very general kind: “the cues are generic”, meaning that it is tested whether there is a statistically relevant correlation between subgenre labels and the distinctive features of text categories.
608Several sets of general features were prepared. They can be distinguished by the unit that is counted, by the number of most frequent items taken into account, and by the kind of normalization applied to the resulting counts. The values that were selected on these three levels are summarized in table 26.
| Level | Selected values | |
|---|---|---|
| token unit | basic units | words, word 2-grams, word 3-grams, word 4-grams, character 3-grams, character 4-grams, character 5-grams |
| character n-gram subtypes | “all”, “word” (mid-word, multi-word), “affix-punct” (prefix, end-punct) | |
| frequency range (MFW) | 100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000 | |
| normalization | tf, tf-idf, z-scores | |
609Regarding the token units, words are the classical option for
a “bag” representation of the texts, which is needed as a basis for most
machine learning algorithms (Müller and Guido 2016, 330Müller, Andreas C., and Sarah Guido. 2016.
Introduction to Machine Learning with Python: a Guide for Data
Scientists. Sebastopol, CA: O’Reilly.; Scikit-learn developers
2007–2023dScikit-learn developers. 2007–2023d. “Feature
extraction, sec. The Bag of Words representation.” Scikit-learn.
https://web.archive.org/web/20230304131525/https://scikit-learn.org/stable/modules/feature_extraction.html.). For a bag-of-words model, the text is tokenized into
individual units, which are then counted. As a result, a corpus is
represented by the token counts for each document. In such a model, the
order of the units does not play a role anymore. By using word n-grams,
i.e., sequences of n words, as the basic unit, the relevance of word order
can be reintroduced into a bag-of-words model to a certain extent. Word 2-
to 4-grams were chosen to test different ranges of word sequences. While
word 2-grams are most frequent in the whole corpus, 3- and 4-grams are
closer to whole phrases and are more special features that might be relevant
for the distinction of subgenres. Diminishing the unit to character
sequences, on the other hand, has several other advantages. First, it makes
the model less dependent on the exact spelling of the words. In a word-based
approach, a difference in spelling results in different features. In a
character-based approach, the words are split into several sequences anyhow
so that the effect of orthographic differences in specific parts of the
words is smaller. For the corpus at hand, this is of interest because some
spelling errors persist as a result of the text digitization process.509 Second, character n-grams that
include blank space and punctuation marks cover aspects of the text string
that are not captured by the classical bag-of-words approach, where words
are usually split at blank spaces and punctuation marks are ignored. Third,
character n-grams can be modeled so that they cover specific linguistic
substructures of a morphological, thematic, or stylistic nature. Here, both
general character n-grams (called “all” in the above table) and specifically
modeled ones (called “word” and “affix-punct”) are used. How the different
types of character n-grams are generated is illustrated with an example
sentence given in example
49.510
«Espero que algún día, vos amaréis también mis rosas blancas».
610The general approach, which is implemented, for example, in the Python library scikit-learn (Scikit-learn developers 2007–2023fScikit-learn developers. 2007–2023f. “sklearn.feature_extraction.text.CountVectorizer.” Scikit-learn. https://web.archive.org/web/20230304130529/https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html.), uses all types of characters in the string and yields the following 3-grams for the example sentence: “«Es”, “Esp”, “spe”, “per”, “ero”, “ro_”, “o_q”, “_qu”, “que”, “ue_”, “e_a”, “_al”, “alg”, “lgú”, “gún”, “ún_”, “n_d”, “_dí”, “día”, “ía,”, “a,_”, “,_v”, “_vo”, “vos”, etc.511 As Sapkota et al. state, such general character n-grams are very effective for text classification, for example, by author. However, because of the mixed nature of the n-gram types, it is not clear why they are so useful: “Character n-grams are the single most successful feature in authorship attribution [...], but the reason for their success is not well understood. One hypothesis is that character n-grams carry a little bit of everything: lexical content, syntactic content, and even style by means of punctuation and white spaces [...]. While this argument seems plausible, it falls short of a rigorous explanation” (Sapkota et al. 2015, 93Sapkota, Upendra, Steven Bethard, Manuel Montes-y-Gómez, and Thamar Solorio. 2015. “Not All Character N-grams Are Created Equal: A Study in Authorship Attribution.” In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 93–102. Denver, Colorado: Association for Computational Linguistics. http://dx.doi.org/10.3115/v1/N15-1010.). The authors of the cited paper test this hypothesis by designing different types of character n-grams and by using each type separately in authorship attribution tasks to see which kinds of n-grams are successful. They use three types of super categories: n-grams covering morpho-syntactic features (affix-like n-grams, called “affix”), thematic content (word-like n-grams, called “word”), and style (punctuation-based n-grams, called “punct”). The n-gram types associated with the three super categories are called “prefix”, “suffix”, “space-prefix”, and “space-suffix” for the affix group, “whole-word”, “mid-word”, and “multi-word” for the word group, and “beg-punct”, “mid-punct”, and “end-punct” for the punctuation-based group.512 Sapkota et al. (2015, 96–98Sapkota, Upendra, Steven Bethard, Manuel Montes-y-Gómez, and Thamar Solorio. 2015. “Not All Character N-grams Are Created Equal: A Study in Authorship Attribution.” In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 93–102. Denver, Colorado: Association for Computational Linguistics. http://dx.doi.org/10.3115/v1/N15-1010.) found out that the affix-like n-grams are most successful in their single-domain authorship attribution task. For cross-domain authorship attribution, also the punctuation-based features are very strong.513
611The subtypes of n-grams that are modeled here are based on the propositions of Sapkota et al., but because the issue is subgenre classification and not authorship attribution, the selection of n-gram subtypes is led by hypotheses about the features’ relevance for this categorization task. Here, the subtypes “mid-word” and “multi-word” are selected and combined into a word-based character n-gram feature set (called “word”). It aims to cover aspects of the thematic content that is supposed to be different from subgenre to subgenre. Furthermore, the subtypes “prefix” and “end-punct” are used in a set combining morpho-syntactic and stylistic characteristics (called “affix-punct”). Its goal is to test whether the differences between the subgenres may also be captured with features that are not primarily content-based.514 The main reason for not only using general character n-grams is that they are dominated by blank spaces and the short most frequent words in different variants if only a certain number of top most frequent items is used (see table 28 below illustrating the resulting top most frequent tokens for different types of the general features). The intuition is that these features can hardly be interpreted in terms of the different subgenres. Regarding the chosen range of character numbers, it was decided to use 3-, 4-, and 5-grams because 3-grams are the minimum that is needed to be able to construct the different character n-gram subtypes, and 4-grams have been successfully used in subgenre classification before (Hettinger et al. 2016 Hettinger, Lena, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2016. “Classification of Literary Subgenres.” In DHd2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts. Universität Leipzig 7. bis 12. März 2016, 160–164. Duisburg: nisaba verlag. https://doi.org/10.5281/zenodo.4645368.). The 5-grams are included as an alternative candidate. Examples of the n-gram subtypes are listed in table 27, using the above-mentioned example sentence for their creation.
| Group | Subtype | Subtype definition | Examples (for 3-grams) |
|---|---|---|---|
| word | mid-word | “a character n-gram that covers n characters of a word that is at least n + 2 characters long, and that covers neither the first nor the last character of the word”515 | spe per lgú mar aré réi amb mbi bié osa lan anc nca |
| word | multi-word | “n-grams that span multiple words, identified by the presence of a space in the middle of the n-gram” | o_q e_a n_d s_a s_t n_m s_r s_b |
| affix-punct | prefix | “a character n-gram that covers the first n characters of a word that is at least n + 1 characters long” | esp alg ama tam ros bla |
| affix-punct | end-punct | “a character n-gram whose last character is punctuation, but middle characters are not” | ía, as» |
612The examples highlight the differences between the character n-gram subtypes. The most evident one is that the number of resulting n-grams varies. The general approach using all types of character n-grams for the example sentence results in 60 3-gram tokens. In contrast, there are only 13 mid-word, eight multi-word, six prefix, and two end-punct tokens, so depending on the rules set up for the character n-gram subtypes, the feature space is reduced considerably because only some types of words or cross-word sequences meet the conditions.
613Besides the different token units, the frequency ranges were chosen so as to cover stylistic features in the narrower sense with only a small number of most frequent words but also a mix of function and content words with several thousand most frequent words. Three types of normalization were chosen for the token counts: term frequency (tf), term frequency – inverse document frequency (tf-idf), and z-scores. The raw, absolute counts are computed as a basis for the normalization steps but are not directly used in the categorization because they depend heavily on the length of the texts, which varies considerably.516 The term frequency is a relative frequency balancing out the effects that different text lengths have. It is calculated by dividing the absolute number of occurrences of a term t in document d by the frequency of the term t’, which is the term with the maximum frequency in d (see formula 1).
614For tf-idf, the tf-scores are weighted by the inverse document frequency, which is defined as the logarithm of the number of all documents divided by the number of documents that contain the term t. This normalization takes into account the structure of the whole corpus: terms that occur in many documents of the corpus are considered less important than terns that only occur in a few documents. This gives the function words, which are likely to occur in all documents, a weaker weight compared to the more specific content words. Here, the tf-idf-scores were calculated with the Python library scikit-learn, which uses a specific implementation of this weighting scheme (see formulas 2 and 3).517
615The third kind of normalization used, the z-scores, also involve the relationship between the different documents in the corpus, but in a different way than the tf-idf-scores. A z-score measures the number of population standard deviations by which the value of a score is above or below the population mean. This results in positive values for scores that are above the mean, zero values for scores that are equal to the mean, and negative values for scores that are below the mean. The population values are calculated by determining the standard deviation and mean for each feature in the corpus (see formula 4).
616Like tf-idf-scores, z-scores upgrade the importance of terms that are not so frequent relative to the ones that are very frequent, but in the case of z-scores, it is not decisive in how many of the documents in the corpus they occur. In addition, the range of the resulting values is different than for tf and tf-idf because z-score zero values indicate that a term frequency is equal to the population mean but not that the term in question has a frequency of zero in the document. Instead, terms that do not occur at all in documents get negative z-score values. This different treatment of zero values can have consequences when the texts are categorized.
617Furthermore, z-scores themselves do not take into account the effects of different text lengths by computing relative values per document as in tf and tf-idf. By applying the z-score transformation to absolute values, text length effects would only be controlled indirectly and only to a certain extent because the spread of the absolute values in the corpus is factored in through the standard deviation. A term with a higher standard deviation is penalized by the denominator in the formula if it is above the mean and revalued if it is below the mean. However, very long texts would tend to get higher z-score values. In addition, it would not be clear if higher z-score values are due to text length or to above-average uses of a term. It does therefore make sense to apply the z-score-normalization on top of tf-values, which is done here. By considering several normalization strategies in the feature sets, these can be compared to see which effect they have on the kind of features that turn out to be relevant for the categorization. While tf and tf-idf-scores are generally used in document classification, z-scores have especially been used in the context of authorship attribution (Burrows 2002Burrows, John. 2002. “‘Delta’: a Measure of Stylistic Difference and a Guide to Likely Authorship.” Literary and Linguistic Computing 17 (3): 267–287. https://doi.org/10.1093/llc/17.3.267.; Evert et al. 2017Evert, Stefan, Thomas Proisl, Fotis Jannidis, Isabella Reger, Steffen Pielström, Christof Schöch, and Thorsten Vitt. 2017. “Understanding and explaining Delta measures for authorship attribution.” Digital Scholarship in the Humanities 32 (Supplement 2): ii4–ii16. https://doi.org/10.1093/llc/fqx023.; Müller and Guido 2016, 338–340Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.). In sum, the combinations of parameters for the general features listed above result in 390 different MFW-based feature sets.518
618The bag-of-words representations of the novels were created on the basis of full-text files that were extracted from the linguistically annotated TEI files.519 This was done to be able to remove tokens that were annotated as proper nouns, such as person and place names, from the files. This preprocessing step is considered important because especially the names of the protagonists can have distorting effects on the lists of MFW, as they occur very often. By taking out these named entities, of course, conclusions of the form “the female name ‘Blanca’ is overrepresented in sentimental novels” or “the place name ‘Madrid’ is mentioned above-average in Cuban novels” cannot be drawn anymore. Instead, the features are intended to lead to insights into more general linguistic-stylistic characteristics of the texts. In addition to the replacement of proper nouns, a list of stop words was created, consisting of the lists of proper names and place names that were compiled for the spell check of the text files.520 The stop word list is used by scikit-learn’s CountVectorizer (Scikit-learn developers 2007–2023fScikit-learn developers. 2007–2023f. “sklearn.feature_extraction.text.CountVectorizer.” Scikit-learn. https://web.archive.org/web/20230304130529/https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html.) in the process of creating the bag-of-words models that are based on word units.521 The stop word list was applied to the full texts in a customized manner before the character n-gram features were created.522 The combination of entity removal and stop word list has two advantages. A stop word list alone would not work to detect proper names that also have a general meaning in the language, and there are a lot of such names in Spanish, for example, “Blanca” (white), “Clemencia” (mercy), “Rosa” (rose), “Gloria” (fame), “Hidalgo” (nobleman), “Salvador” (saviour), “Gil” (silly), “Cortés” (polite). On the other hand, the stop word list can compensate for some errors of the named entity recognition.
619Several visualizations were created to characterize the
resulting feature sets.523 It is, for example, useful to know if a
feature set is sparse, i.e., if many of the features have mostly zero values
or if almost all the features are present in all instances of the corpus. It
is also of interest to know how much the feature values vary. Both these
characteristics have an influence on how well specific categorization
methods work and if further steps of preprocessing are needed before the
feature sets can be used for categorization.524
Figure 36 shows how the overall
proportion of zero values increases from 100 to 5,000 MFW from less than 1 %
to one-third of all the values.525
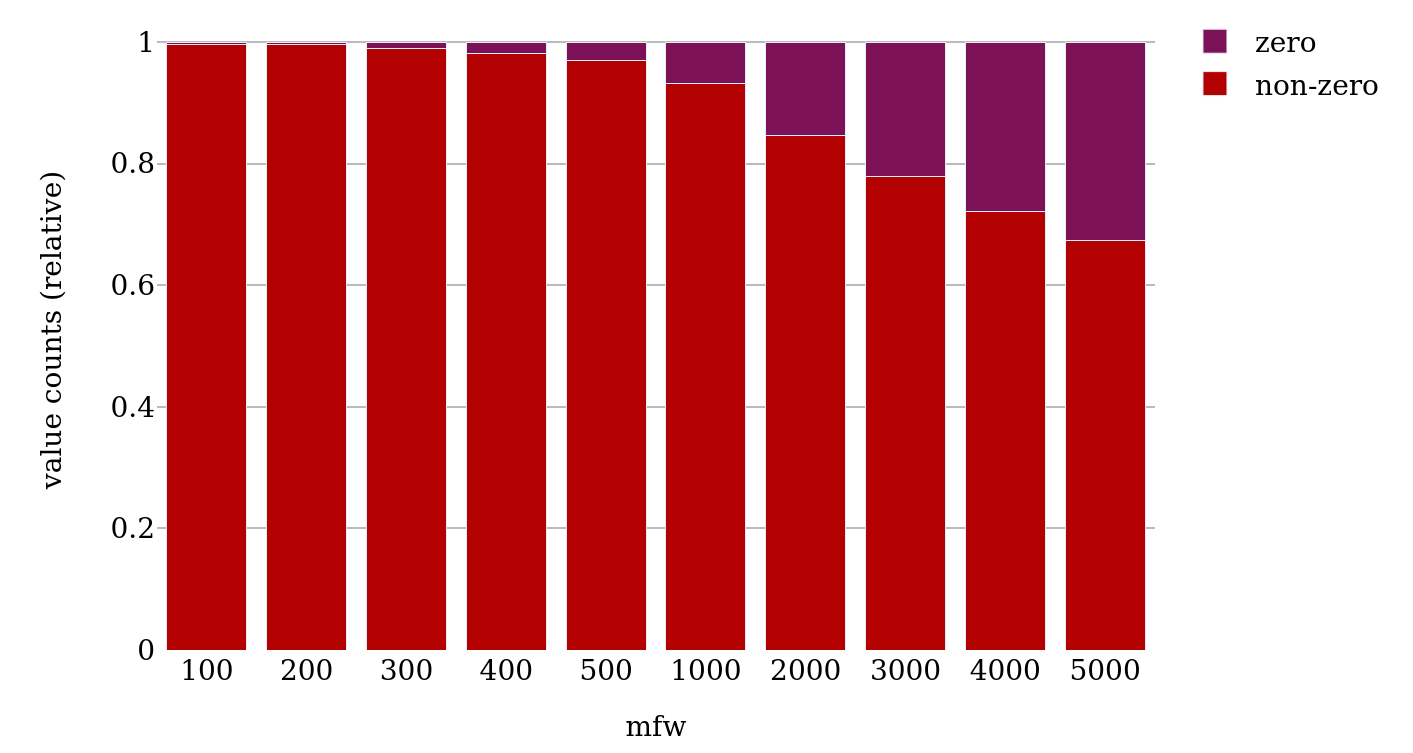
620Looking in more detail into how many features have how many
zero values in figures 37 and
38, it can be seen that the
zero values in MFW100 stem from a few features only, of which one has over
40 zero values. 94 % of the features are never zero. In contrast, in
MFW5000, only 7 % of the features are never zero. The form of the histogram
shows that there are many features that are zero in about half of the texts.
For the frequencies between 100 and 5,000 MFW, the overall proportion of
zero values lies between these extremes, and the bulk of features has zero
values in an increasing part of the corpus.
621Character n-grams are much more stable regarding the proportion of zero values than words. For example, there are no zero values for the 100 most frequent character 5-grams. For the 5000 most frequent ones, the amount increases only to 1 %. For word n-grams, on the other hand, the proportions of zero values increase abruptly from the 3-grams on. The 100 most frequent word 2-grams, for instance, have less than 1 % of zero values. In contrast, the 100 most frequent word 3-grams have 11 %, and the word 4-grams 43 %. The 5000 most frequent word 2-grams have 32 % of zero values, the word 3-grams 57 %, and the word 4-grams 82%.526
622In the following figures
39 to 42, it is illustrated for MFW1000 how the different
normalization strategies reduce the variance of the feature values. For
absolute values, the variances range between 6 and 2,976, for tf-scores
between 0.001 and 0.150, for tf-idf-scores between 0.0006 and 0.0581, and
for z-scores between 0.999999999999998 and 1.000000000000002, so the
absolute values of variance are smallest for the tf- and tf-idf-scores, but
the range of variance is smallest for the z-scores.527 In addition, the
distribution of the variances changes from a right-skewed distribution for
the tf- and tf-idf-scores to a left-skewed distribution for the z-score
values, for which the variance is expressed in relative terms and,
therefore, more balanced for the different frequency ranges of the features.
With z-scores, most features vary to a similar degree, and only a few
features are more consistent throughout the texts in the corpus. A
hypothesis of the effect that these differently normalized features have on
classification tasks is that less frequent features will have a higher
probability of being selected as important features if the variances of the
features are more balanced.528
623The top 10 features for different frequency sectors and token units are listed in table 28 to get a sense of the kind of features contained in the matrices of the most frequent items.
| Frequency sector (MFW) | Token unit | Tokens |
|---|---|---|
| 1–10 | word | de el la que y a en se los no |
| 101–110 | word | esto habían allí hay desde todas amor vez toda mucho |
| 501–510 | word | alto última voluntad pensar dirigió delante_de alegría siquiera además pasos |
| 1001–1010 | word | daban no_obstante basta tranquilo hablando vivo mozo batalla cólera poco_a_poco |
| 4091–5000 | word | injusticia apoyada sensaciones bendito cuadra insignificante personalmente distinción significa fijo |
| 1–10 | word 2-gram | de_el a_el de_la a_la en_el en_la de_los de_su que_se lo_que |
| 101–110 | word 2-gram | como_si si_no todas_las por_su pero_no sobre_el y_le por_los a_una la_joven |
| 501–510 | word 2-gram | calle_de dijo_que como_los una_palabra era_de sobre_las mi_madre sobre_los el_primero que_tiene |
| 1001–1010 | word 2-gram | de_otro tenía_que en_toda el_instante sus_hijos con_lo ver_lo hombres_de preguntó_el dueño_de |
| 4091–5000 | word 2-gram | esos_hombres eso_y mañana_de sin_querer en_ti qué_había dando_se sus_soldados paz_y amigo_el |
| 1–10 | char 4-gram | _de_ _el_ que_ _que _la_ _en_ _con _se_ o_de a_de |
| 101–110 | char 4-gram | ada_ _cua más_ as_d a_ca a_y_ o_co ue_l _más e_qu |
| 501–510 | char 4-gram | es._ as._ ar_e _cam adre ía_d ue_c _ni_ no_p nte, |
| 1001–1010 | char 4-gram | o,_q s,_a _tem an_c s,_l olvi s,_q uego aber ber_ |
| 4091–5000 | char 4-gram | neci pitá siti rmas ría, lia_ rici no_f _obr vend |
| 1–10 | char 4-gram (word) | o_de a_de s_de e_la de_l e_el de_e a_el ente ando |
| 101–110 | char 4-gram (word) | el_a ones enta n_qu os_e ue_n ntra o_nha ar_s mbre |
| 501–510 | char 4-gram (word) | nera ar_d otra ra_p o_re s_ve es_l s_el ende echa |
| 1001–1010 | char 4-gram (word) | nqui dich ía_q casi sibl feli l_mi alid uant dici |
| 4091–5000 | char 4-gram (word) | rcan masi idam clas ifes mbia pica e_be mó_e uili |
| 1–10 | char 4-gram (affix-punct) | ente ando para ment esta ento ante como habí cont |
| 101–110 | char 4-gram (affix-punct) | ismo hast pera ensa algu acio ales hora prim vida |
| 501–510 | char 4-gram (affix-punct) | grad inad cura cult rinc ingu vers engo camp oras |
| 1001–1010 | char 4-gram (affix-punct) | sueñ dorm fere ritu alud denc creí pend saca lara |
| 4091–5000 | char 4-gram (affix-punct) | dudo line aza. nel, mutu sinu genu oso; iro, decr |
624For the word unit, the frequency range 1–10 contains exclusively function words (propositions, conjunctions, articles, and pronouns) and the particle “no”. In the range 101–110, the nouns “amor” and “vez” enter the list, and there are several verbs and adverbs with general meanings. Range 501–510 contains more specific nouns (“voluntad”, “alegría”, “pasos”), semantically more specific verb forms (“pensar”, “dirigió”), and adjectives (“alto”, “última”). On the positions 1001–1010 and 4091–5000, there are nouns with quite specific meanings (“mozo”, “batalla”, “cólera”, “injusticia”, “sensaciones”, “cuadra”, “distinción”), verbs with more different tenses (gerund: “hablando”, imperfect: “daban”, participle: “apoyada”), and also adjectives and adverbs with increasingly specific meanings (“tranquilo”, “bendito”, “insignificante” and “no_obstante”, “poco_a_poco”, “personalmente”). The word lists from the different frequency sectors show how the feature space gets more complex in terms of the grammatical forms of words that are included and also regarding the semantic specificity of the words as more most frequent items are included.
625In the word 2-grams, function words dominate the most frequent tokens in all frequency ranges. On positions 1–10, the 2-grams consist entirely of function words. In the range 101–110, the particle “no” (“si_no”, “pero_no”), a noun (“la_joven”), and an adjective (“todas_las”) appear as one part of the word combinations. The first verbs are visible in the range 501–510 (“dijo_que”, “era_de”, “que_tiene”). A 2-gram without function words appears in the 4091–5000 most frequent items (“sin_querer”). So due to the combination of two words, the semantic specificity of individual words increases later than for the one-word unit. As for the character n-grams, it is directly visible that the most frequent items of the classic n-grams contain many combinations of white spaces and short function words (e.g., “_de_”, “o_de”, “a_de”). Nouns and verbs can be recognized from the 501–510 MFW group onwards (“adre”, “olvi”, “aber”, “rmas”). The special types of n-grams – the ones only including mid- and multi-word n-grams (“word”) and the ones consisting only of prefixes and word endings with punctuation marks (“affix-punct”) – are more homogeneous throughout the different frequency ranges.
626The general features presented here are open with regards to the grammatical and semantic characteristics and have the advantage that they cover a broad spectrum of the linguistic material in the full-text basis, the extent of which depends on the chosen frequency range and token unit. Therefore, they lend themselves well to exploratory analyses. A disadvantage coming along is that these features can be difficult to interpret. In the high frequency ranges, this is because semantic elements are scarce, and in the broader frequency spans, it is because of the heterogeneity of the features. The preparation of the semantic features that are used as a counterweight and an alternative to these general features is outlined in the next chapter.
627The method used to determine thematic elements in the texts is topic modeling, a text-mining method that is unsupervised and not deterministic. Unsupervised means that the set of topics is not predefined but emerges from the text collection that is analyzed. A method that is not deterministic does not produce the same output every time it is run, even if the start conditions are fixed, which means that an element of randomness is involved in the process. The goal of topic modeling is to uncover hidden semantic relationships between the words used in the documents of a large text collection and thereby determine what the texts in the collection are about.529 The semantic relationships between the words are described as hidden because a topic model involves the basic units corpus, document, word, and topic, of which the first three – in their input version – are predefined structures and processable parts of the text collection’s initial state. The topics, on the other hand, constitute a medium layer between the words and the document, or the words and the corpus. The topic layer is inferred from the distributional characteristics of the words in the documents with a probabilistic approach but is not inherently manifest in the text strings and their structural organization. The basic idea comes from the field of distributional semantics and was pointedly put by J. R. Firth already in 1957: “You shall know a word by the company it keeps!” (Firth 1968, 179Firth, John Rupert. 1968. “A synopsis of linguistic theory 1930–1955.” In Selected Papers of J. R. Firth 1952–1959, edited by F. R. Palmer, 168–205. Bloomington, London: Indiana University Press.).530 The essence of the quote is that words that repeatedly precede and follow a particular word of interest in a defined textual context contribute to its meaning so that words that occur in the same contexts tend to have similar meanings. This distributional hypothesis is also the theoretical basis for topic modeling.531 Words that occur in the same context in many documents of a text collection are grouped together into topics because it is assumed that their meanings are related.532
628In the topic modeling approach, the terms “word”, “document”, “corpus”, and “topic” have specific meanings. Words correspond to tokens that the text is split into and the tokens that are selected for the topic modeling analysis. They can but need not concur with words in a linguistic sense, depending on how the tokens are defined. Often a list of stop words is applied before the topic model is built so that not all the words that are part of the initial text string stay in the resulting model. The goal is to remove words that carry little semantic value, such as function words, in order to get topics that consist mainly of content words whose distributional relationships are easy to interpret as being of a semantic kind. The term “document” has different meanings, depending on the level on which it is used in a topic modeling workflow. In the narrow sense, “document” is defined as a structure resulting from the topic modeling process. In a wider sense, though, “document” also has a special meaning as an input structure for the topic modeling algorithm. To be able to differentiate between these different uses of the term “document”, they are distinguished here by indexing the term. For the purpose of this dissertation, documentS means the original source document in the form of a continuous text string of characters, documentIn-1 is the input document that the topic modeling algorithm gets, documentIn-2 is the input document that the topic modeling algorithm creates internally and uses as a basis for the modeling process, and documentOut is the output document resulting in the final topic model.
629DocumentsIn-1 are the text units
that constitute the contextual frame in which the co-occurrence of the words
is analyzed and counted. They can but need not correspond to entire
documentsS of a text collection such as books
or articles. Alternatively, they can be combinations of documentsS or subparts of them. In practice, the size of the
documentsIn-1 for topic modeling is often
chosen with the aim of balancing the length of the text units and optimizing
them for the algorithm to produce good results. Usually, very long texts and
texts with a significant variance in length, such as novels, are segmented
into smaller units.533 For a topic
model, the documentsIn-1 are not kept as sequences
of words, punctuation marks, and blank spaces. Instead, internally, they are
converted to a collection of word counts following the bag-of-words
approach, the documentsIn-2, as demonstrated with
the sentence in example
50 and the resulting word count matrix in table 29.
El 4 de mayo de 1840, a las diez y media de la noche, seis
hombres atravesaban el patio de una pequeña casa de la calle de
Belgrano, en la ciudad de Buenos Aires.
| 4 | 1840 | a | atravesaban | calle | casa | ciudad | de | diez | el | en |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 7 | 1 | 2 | 1 |
| hombres | la | las | mayo | media | noche | patio | pequeña | seis | una | y |
| 1 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
630In the example, the proper names “Belgrano” and “Buenos Aires” are treated as stop words and are not included in the word count matrix. Furthermore, all the tokens are converted to lowercase before counting them. Punctuation marks and blank spaces are removed, and the order of the words is suspended. Already in this single sentence, the counts give an impression of the kind of words that dominate from a quantitative point of view: “de” (7), “la” (3), and “el” (2), which are all function words. Table 30 shows how the matrix is further reduced if the sentence is preprocessed by only selecting the lemmas of nouns.
| calle | casa | ciudad | hombre | mayo | noche | patio |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
631It becomes clear that the decisions on how to preprocess the texts significantly influence what a word and a documentS become in the topic modeling. In the case of lemmatization, also morphological information is lost, and by selecting only one type of word category, the initial sentence is reduced to content buzzwords. Furthermore, it is not only the structure inside of sentences that is reduced. The sentences themselves and higher-order structures inside of the documentsS are also not preserved.
632In the context of topic modeling, also the term “corpus” has several meanings if both the input and output states of the model are considered. As for the documents, I differentiate between corpusS as the collection of documentsS, i.e., the original full-text files, corpusIn-1 as the collection of documentsIn-1, that is, the set of full-text snippets that the topic algorithm receives as an input and that already can have been preprocessed by stop word removal, linguistic annotation and selection, or chunking. The corpusIn-2 is the collection of documentsIn-2, which is a matrix of terms and their counts per document.534 Finally, there is also a corpusOut, which is part of the final topic model.
633The term “topic” is only defined on the output level, as this structure does not exist on the input levels and is found by the algorithm. Technically, a topic is a probability distribution over words. For each word that is part of the corpusIn-2’s vocabulary535, a probability value indicates how important it is for the topic at hand (Steyvers and Griffiths 2007, 2Steyvers, Mark, and Tom Griffiths. 2007. “Probabilistic Topic Models.” In Handbook of latent semantic analysis, edited by Thomas K. Landauer, Danielle S. McNamara, Simon Dennis, and Walter Kintsch, 427–448. Mahwah, NJ: Lawrence Erlbaum Associates. https://web.archive.org/web/20220927113904/https://cocosci.princeton.edu/tom/papers/SteyversGriffiths.pdf.). Table 31 illustrates the structure of topics by showing the 15 top words of two different topics that are part of a topic model created for the corpus Conha19.536
| Topic 77 | Topic 10 | ||||
|---|---|---|---|---|---|
| Word | Probability | Count | Word | Probability | Count |
| amor | 0.09260 | 8839 | bandido | 0.05592 | 763 |
| corazón | 0.06372 | 6082 | jefe | 0.02844 | 388 |
| alma | 0.03663 | 3496 | ladrón | 0.02375 | 324 |
| pasión | 0.02052 | 1959 | robo | 0.01752 | 239 |
| felicidad | 0.01882 | 1796 | policía | 0.01708 | 233 |
| palabra | 0.01761 | 1681 | crimen | 0.01700 | 232 |
| ser | 0.01235 | 1179 | compañero | 0.01634 | 223 |
| sentimiento | 0.01187 | 1133 | bandolero | 0.01158 | 158 |
| flor | 0.01173 | 1120 | lugar | 0.01099 | 150 |
| mirada | 0.01113 | 1062 | justicia | 0.00880 | 120 |
| pensamiento | 0.01009 | 963 | sociedad | 0.00777 | 106 |
| placer | 0.00950 | 907 | camarada | 0.00770 | 105 |
| esperanza | 0.00819 | 782 | silencio | 0.00770 | 105 |
| cielo | 0.00777 | 742 | comandante | 0.00696 | 95 |
| ángel | 0.00776 | 741 | camino | 0.00660 | 90 |
634An important insight is to realize that each topic consists of all the words in the corpus vocabulary and that the differences between the topics are the result of the different weights that the words have in each topic. When humans interpret topics, usually, they only examine a certain number of words – those with the highest probability. The semantics of the topics emerges from the combination of high-probability words. A human inspector can evaluate the semantic relationships between the terms and label the topics with titles. A topic title can consist of individual words but also descriptions. In the above example, topic 77 could be entitled “love” or “love and feelings” and topic 10 “crime” or “crime and society”. Computers can also evaluate the resulting topics by calculating the similarity and semantic relationships of the most important terms in each topic by using external semantic resources, for example, word embeddings,537 word nets,538 or dictionaries. Computers could also label topics, for example, by finding superordinate terms. Nevertheless, for creating the topics, no explicit semantic knowledge is necessary because the algorithm bases the assumptions on the relationships between the terms in a topic only on statistical, distributional patterns. Another advantage of topic modeling is that polysemy is not problematic. As every word occurs in every topic, the same word can be important in several topics where its meaning is determined by the surrounding words. In the table, the “probability” column indicates how probable a word is in a specific topic, and the “count” column shows how often a word has been assigned to a topic across all documents. When the counts are compared, the love topic is more important in the corpus than the crime topic because the number of tokens assigned to it is higher. In total, the love topic has 95,452 token assignments, and the crime topic has only 13,644.539 Inside each topic, the probabilities indicate the relative importance of each word. In the love topic, the first words have higher probabilities than the first words of the crime topic. However, the differences between the probabilities decrease for the lower word ranks, which means that the love topic is more dominated by a few very important words than the crime topic.
635In the topic model output, the documentOut is a probability distribution over topics. For each topic that was defined for the corpus, a probability value is given for every document, and topics with higher probabilities are considered especially relevant for the document in question. It follows from this that the corpusOut is a matrix of probability distributions over topics. The structure of three example documentsOut is given in table 32, showing the probabilities of five selected topics of the model.540
| Document number | Document name | Topic 0 | Topic 1 | Topic 2 | Topic 10 | Topic 77 |
|---|---|---|---|---|---|---|
| 0 | nh0217§0030.txt | 0.04178 | 0.00009 | 0.00003 | 0.00362 | 0.00029 |
| 1 | nh0107§0052.txt | 0.00002 | 0.00384 | 0.00004 | 0.00004 | 0.00406 |
| 2 | nh0103§0012.txt | 0.00002 | 0.00010 | 0.00004 | 0.00005 | 0.14777 |
636Here, the names of the documents are a combination of the novels’ identifiers in Conha19 (“nh0217”) and the numbers of the text segments that served as documentsIn-1 (“§0030”). To be able to evaluate the probabilities of the topics in the entire novels, the values for the individual segments have to be aggregated again, for example, by using average probabilities. The different probability values show how important the topics are in the documentsOut. Regarding the love topic (topic 10) and the crime topic (topic 77), the table shows that the segment of the first document in the list (“nh0217§0030”) has a higher probability for the love topic than the other two segments from other documents and the third segment (“nh0103§0012”) has a higher probability for the crime topic than the preceding ones. The identifier “nh0217” belongs to the novel “El espejo de Amarilis” (1902, MX) by Laura Méndez de Cuenca and “nh0103” to the novel “El mendigo de San Ángel” (1865, MX) by Niceto de Zamacois. The first one is a novel of customs involving romantic plot elements, and the latter is a historical novel. The results of the topic model seem reasonable, since a prominent love topic can be expected in a novel with a romantic plot, and it is also plausible that the crime topic would carry greater weight in a historical novel.
637The topic model was created with the tool MALLET (McCallum 2002McCallum, Andrew. 2002. “MALLET: A Machine Learning for Language Toolkit.” Accessed November 13, 2020. http://mallet.cs.umass.edu.), in which the topic modeling algorithm Latent Dirichlet Allocation (LDA) is implemented (Blei, Ng, and Jordan 2003Blei, David M., Andrew Y. Ng, and Michael I. Jordan. 2003. “Latent dirichlet allocation.” Journal of Machine Learning Research 3: 993–1022. https://web.archive.org/web/20230310095853/https://dl.acm.org/doi/pdf/10.5555/944919.944937.; Blei 2012Blei, David M. 2012. “Probabilistic Topic Models.” Communications of the ACM 55 (4): 77–84. https://doi.org/10.1145/2133806.2133826.). Other mathematical and technical approaches to topic models exist, but LDA is the most prominent current technique and is widely used.541 LDA is based on a generative model, assuming the documents are generated based on the topics. The method works by choosing a distribution over topics for each document and subsequently choosing a topic from this distribution for each word in each document. Finally, a word is chosen from the topic’s distribution over words. The process starts with an initial distribution542 and approximates it to the data by iterating over the words in the corpus.543 The most important parameter that needs to be set for the algorithm is the number of topics to model.
638For humanists who want to evaluate results obtained from topic modeling or who are interested in using the method to produce their own results, it is fundamental to recognize the different meanings of the basic terms word, document, corpus, and topic in the context of topic modeling compared to the context of thematic analyses based on linguistic and literary theories. In the “Reallexikon of German Literary Studies”, for instance, the term “Thema” is defined as “Die einem Text zugrundeliegende Problem- oder Gedankenkonstellation” (Schulz 2007, 634Schulz, Armin. 2007. “Thema.” In Reallexikon der deutschen Literaturwissenschaft, edited by Harald Fricke, 634–635. Vol. 2. Berlin, New York: De Gruyter.), which means the central topic or subject of a text and corresponds roughly to the English term “theme”. This sense of topic is different from the topicsTM resulting from topic modeling544 in that it is defined on a more abstract level. The underlying theme of a text can be interpreted from its linguistic material but does not necessarily have to be directly present in terms of formulations using the word or words that describe the theme. For example, one could think of a short story describing a romantic dinner and containing dialogues of a couple, but in which the word love is never used. Nevertheless, a reader could conclude that the central topic of the story is just love.
639The topicsTM, on the other hand, are closer to the textual surface. A topic model captures how topics are realized in text segments. However, to find one or several central themes of a text, the topicsTM need to be interpreted on a more general level.545 A term that is better suited to be related to the topicsTM is the text-linguistic term thematische Entfaltung. It focuses on how the theme or central topic of a text is unfolded in the overall content of the text. Brinker, Cölfen, and Pappert (2014, 57–80Brinker, Klaus, Hermann Cölfen, and Steffen Pappert. 2014. Linguististische Textanalyse. Eine Einführung in Grundbegriffe und Methoden. 8th ed. Berlin: Erich Schmidt Verlag.) define the thematic unfolding as a combination and linkage of relational and logical-semantically defined categories that express the relationship of partial topics present in individual parts and substructures of the text to its central topic. They mention justification and specification as examples of such relational categories. Obviously, the same central topic can be unfolded in different ways. Brinker, Cölfen, and Pappert also define a set of basic forms of thematic unfolding: descriptive, narrative, explicative, and argumentative thematic unfolding.546 Brinker, Cölfen, and Pappert stress that the thematic unfolding is influenced significantly by communicative and situational factors, such as the intention or purpose of the communication, which leads to several different possibilities of unfolding the same central topic. However, little is known about the factors which have an effect on the exact unfolding. From the point of view of digital literary studies and especially stylistics, this means that also stylistic intentions can have an influence on the thematic unfolding, or, looked at from another perspective, that the exact thematic unfolding can be interpreted as an intended or unintended stylistic effect. The distribution of topicsTM in the documentsOut of a topic model could be interpreted as the result of thematic unfolding. On the level of the corpusOut, the specific set of topicsTM can be understood as resulting from the thematic unfolding across all documents in the text collection. The thematic unfolding itself, as defined by the combination of relational and logical-semantical categories, though, is located on a more abstract level, which is intermediate between the topicsTM and the theme of the text. Brinker, Cölfen, and Pappert point out that the theme or central topic of the text is the shortest possible summary of the textual content and that only a reader’s interpretation can achieve this reduction:
Man muss sich überhaupt darüber im Klaren sein, dass die textanalytische Bestimmung des Themas primär auf interpretativen Verfahren beruht; es kann hier keine ‘mechanische’ Prozedur geben, die nach endlich vielen Schritten automatisch zur ‘richtigen’ Themenformulierung führt. [...] Die Bestimmung des Themas ist vielmehr abhängig von dem Gesamtverständnis, das der jeweilige Leser von dem Text gewinnt. Dieses Gesamtverständnis ist entscheidend durch die beim Emittenten vermutete Intention bestimmt, d. h. durch die kommunikative Absicht, die der Sprecher / Schreiber mit seinem Text nach der Meinung des Rezipienten verfolgt. (Brinker, Cölfen, and Pappert 2014, 53–54Brinker, Klaus, Hermann Cölfen, and Steffen Pappert. 2014. Linguististische Textanalyse. Eine Einführung in Grundbegriffe und Methoden. 8th ed. Berlin: Erich Schmidt Verlag.)
640Regarding the possibilities of a mechanical (or computational) method to determine the theme of a text, I take a more moderate position. Even if a reader is indispensable as the last instance of interpretation, formal methods can be used to evaluate how a theme is thematically unfolded in a text. Furthermore, the basic types of thematic unfolding have been taken up by Schöch and Rißler-Pipka in a topic modeling analysis of literary texts. In a contribution to a conference panel on drama analysis, Schöch and Rißler-Pipka analyzed the distribution of argumentative, narrative, descriptive, and discursive topics in 1,100 novels, 800 dramatic texts, and 1.8 million Wikipedia articles in French to see if the proportions of topic types vary by genre.547 Moreover, different forms of thematic unfolding are also studied in computational studies in general.548 These approaches perform much of the text-analytical determination of topics and theme and push the role of a human reader or a human interpreter of analytical results to a higher level.
641Whatever the relationship between literary-theoretical and linguistic terms that cover content-related aspects and topicsTM, so far, the systematic analysis of content has not been a key concern in literary scholarship:
’Inhaltsanalyse’ (engl. content analysis) ist eigentlich kein literaturwissenschaftlicher Begriff. Diese [in den Sozialwissenschaften verbreitete] hier stark vereinfacht beschriebene, mit diversen Kontrollverfahren zur Einhaltung von Intersubjektivitätsmaßstäben begleitete, insgesamt sehr aufwändige und inzwischen bei der Texterfassung, -bearbeitung und -auswertung weitgehend computergestützte Vorgehensweise ist lieraturwissenschaftlichen Umgangsformen mit Texten fast völlig fremd. Allenfalls in der Computerphilologie [...] zeigt man sich mit ihnen vertraut. (Anz 2007, 55Anz, Thomas. 2007. “Inhaltsanalyse.” In Handbuch Literaturwissenschaft. Gegenstände – Konzepte – Institutionen, edited by Thomas Anz, vol. 2, Methoden und Theorien, 55–69. Stuttgart, Weimar: J.B. Metzler.)
642As Anz points out, systematic content analysis has a longer tradition in the social sciences than in literary studies. According to him, the core interest of literary studies is much more the specific literary function of the texts, which manifests itself in particular linguistic and structural forms (Anz 2007, 57Anz, Thomas. 2007. “Inhaltsanalyse.” In Handbuch Literaturwissenschaft. Gegenstände – Konzepte – Institutionen, edited by Thomas Anz, vol. 2, Methoden und Theorien, 55–69. Stuttgart, Weimar: J.B. Metzler.). In this regard, the method of topic modeling, with its dependence on the textual surface, is closer to the concern of literary scholarship than content analysis because it allows us to examine the relationships between content and form more directly. In computational literary studies, topic modeling has indeed been taken up with interest and applied to a variety of literary texts with success (see, among others, Jockers 2013Jockers, Matthew L. 2013. Macroanalysis. Digital Methods & Literary History. Topics in the Digital Humanities. Urbana, Chicago, and Springfield: University of Illinois Press.; Rhody 2012Rhody, Lisa M. 2012. “Topic Modeling and Figurative Language.” Journal of Digital Humanities 2 (1). https://web.archive.org/web/20230316135657/https://journalofdigitalhumanities.org/2-1/topic-modeling-and-figurative-language-by-lisa-m-rhody/.; Schöch 2017cSchöch, Christof. 2017c. “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.” Digital Humanities Quarterly 11 (2). https://web.archive.org/web/20230211105751/http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html.). Literary scholars that used topic modeling soon discovered that the relationships between the terms in the topics are not necessarily content-related and do not even need to be of a semantic nature. When applied to literary texts, topic modeling can also discover rhetoric structures and elements of discourse (Jannidis 2016, 27Jannidis, Fotis. 2016. “Quantitative Analyse literarischer Texte am Beispiel des Topic Modeling.” Der Deutschunterricht 68 (5): 24–35.).549 That such structures were especially noticed when topic modeling was applied to literary texts shows that the method, which originally aimed at enabling content analysis, has been developed and optimized on the basis of non-literary text types. It also indicates that the distributional hypothesis could be understood in a wider sense as not only applying to semantic relationships but also to discourse relationships. However, to what extent non-thematic topics can be produced also depends on the kind of preprocessing applied to the texts. If only nouns are processed, it is more probable that the words in the topics are held together by semantic, thematic, and content-related connections.
643For the analysis of subgenres of the novel pursued here, this traditional way of using topic models is intended. Therefore, the linguistically annotated version of the novels is used, and only noun lemmas are selected, aiming at semantic and content-related topics. This way of preprocessing the texts has also been applied in other digital literary studies that used topic modeling for genre distinction and categorization.550 Primarily stylistic aspects, on the other hand, are intended to be covered by the general, most frequent words-based features, so that the noun-based topics function as a counterpart and as semantic features. As for the general features, also for the topics, several feature sets were prepared using different parameters, as summarized in the following table 33.
| Parameter | Selected values |
|---|---|
| Number of topics | 50, 60, 70, 80, 90, 100 |
| Optimization interval | 50, 100, 250, 500, 1000, 2500, 5000, None |
644The first parameter that was varied is the number of topics. Here, a range of 50 to 100 topics is considered reasonable for the corpus with 256 novels. In his study of French classical drama, Schöch (2017cSchöch, Christof. 2017c. “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.” Digital Humanities Quarterly 11 (2). https://web.archive.org/web/20230211105751/http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html.) used 60 topics for a collection of 391 novels. Schöch, Henny et al. (2016Schöch, Christof, Ulrike Henny, José Calvo Tello, Daniel Schlör, and Stefanie Popp. 2016. “Topic, Genre, Text. Topics im Textverlauf von Untergattungen des spanischen und hispanoamerikanischen Romans (1880–1930).” In DHd 2016. Modellierung, Vernetzung, Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts, 235–239. Leipzig: Universität Leipzig. https://doi.org/10.5281/zenodo.4645380.) used 70 topics for a corpus of 150 Spanish and Spanish-American nineteenth-century novels, and Hettinger et al. (2016 Hettinger, Lena, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2016. “Classification of Literary Subgenres.” In DHd2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts. Universität Leipzig 7. bis 12. März 2016, 160–164. Duisburg: nisaba verlag. https://doi.org/10.5281/zenodo.4645368.) found the best performance for classifying 628 German novels with 100 topics. In general, a lower number of topics produces more general results, and a higher number covers more specific thematic aspects of a text collection.
645The second parameter that was selected for variation here is the optimization interval, that is, the interval at which the Dirichlet hyperparameters for the LDA model are optimized during the iterations of the topic modeling process. The two hyperparameters, alpha (α) and beta (β), influence the form of the topic probability distribution over words and the document probability distribution over topics, respectively. The lower the parameters are, the more the resulting distribution is concentrated on single values. Otherwise, it is more even. It follows that a lower alpha value leads to topics with a few dominant and many unimportant words and a lower beta parameter to documents that are dominated by a few topics rather than by a larger number of roughly equivalent topics. In the MALLET implementation of LDA, which was used here,551 the parameter optimize-interval indirectly influences the form of the two types of distribution. A lower rate of optimization results in more even distributions and a higher value in more skewed ones. By not setting this parameter at all, no hyperparameter optimization is performed, which leads to even probability distributions (McCallum 2018bMcCallum, Andrew. 2018b. “Topic modeling.” MALLET: A Machine Learning for Language Toolkit. https://web.archive.org/web/20201112052435/http://mallet.cs.umass.edu/topics.php.; Wallach, Mimno, and McCallum 2009Wallach, Hanna M., David Mimno, and Andrew McCallum. 2009. “Rethinking LDA: Why Priors Matter.” Advances in Neural Information Processing Systems 22: 1973–1981. https://web.archive.org/web/20230316142452/https://mimno.infosci.cornell.edu/papers/NIPS2009_0929.pdf.). Schöch (2016Schöch, Christof. 2016. “Topic Modeling with MALLET: Hyperparameter Optimization.” The Dragonfly’s Gaze. https://web.archive.org/web/20230316145457/https://dragonfly.hypotheses.org/1051., 2017cSchöch, Christof. 2017c. “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.” Digital Humanities Quarterly 11 (2). https://web.archive.org/web/20230211105751/http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html.) has analyzed how different optimization intervals influence the results for subgenre classification in French novels and drama.552 The range of intervals that has been selected here varies from 50 to 5,000 and also includes None. With a fixed number of 5,000 iterations, this results in 50, 20, 10, 5, 2, 1, and no optimizations.
646As to the preprocessing of the texts, the following procedure was followed: first, the linguistically annotated versions of the TEI corpus files were used to extract the noun lemmas for each novel and to create full-text files only containing the nouns. As for the general features, also here proper names were excluded.553 Then, the novels are segmented into chunks of 1,000 tokens, which are fed into the topic modeling workflow. A stopword list consisting of the 50 most frequent nouns and of proper names and place names was created and used by MALLET.554 For text segmentation, modeling, and post-processing of the results, the tool tmw (Topic Modeling Workflow) was used. Tmw was developed by Christof Schöch and Daniel Schlör in the context of the CLiGS project. It is a set of python scripts that especially supports the pre- and post-processing of the texts that are used for the topic modeling. It also includes a set of functions to visualize the topic modeling results. Its development is organized in a GitHub repository (see Schöch and Schlör 2017Schöch, Christof, and Daniel Schlör. 2017. “tmw – Topic Modeling Workflow.” GitHub. Accessed November 14, 2020. https://github.com/cligs/tmw.).555 The tmw scripts have been slightly adapted to create the topic models used here. Mainly the routines for calling the core functions were changed.556 An important feature of tmw is the text segmenting procedure. Before the novels are processed with MALLET, they are split into segments of a defined length,557 so that the topic models are created for the segments, not the entire texts. In the post-process step, tmw recombines the segments of the novels and calculates average probability values. The segmenting step is considered important to counter the effects of different text lengths, and the recombination of the segments is necessary to be able to interpret the results per novel. Finally, because topic modeling is not deterministic, five different models were produced for each parameter constellation.558 Through the different combinations of topic modeling parameters and the repetitions of the modeling process, 240 different topic models were created for the whole corpus.
647As for the MFW-based features, also for the topics, some
general characteristics of the feature sets are evaluated here. Unlike for
MFW, the number of zero values is not relevant for the topics, though, as no
zero values were found in the whole set of topic models created for the
corpus of Spanish-American novels. This means that each topic has at least
some probability in each document, even if it is very small.559 Another aspect of the models that was
evaluated is the coherence of the topics. The tool MALLET includes a set of
diagnostic measures which can be saved as an additional output of the topic
modeling process and can be used to assess the formal quality of the topic
models. One of the measures is the coherence metric, which evaluates whether
the words in a topic actually occur together in the texts of the corpus.
This is examined by taking each pair of top words in a topic and calculating
“the log of the probability that a document containing at least one instance
of the higher-ranked word also contains at least one instance of the
lower-ranked word” (McCallum
2018aMcCallum, Andrew. 2018a. “Topic model diagnostics.”
MALLET: A Machine Learning for Language Toolkit.
https://web.archive.org/web/20200221035417/https://mallet.cs.umass.edu/diagnostics.php.). The resulting scores are negative, and values closer to
zero mean that words co-occur more often. For the models at hand, the number
of top words was set to 50. As the coherence measure depends on the top
words, it is expected that lower numbers of top words lead to coherence
scores that a closer to zero than the scores for models with a higher number
of top words. However, as the number of top words is the same for all the
models here, the resulting coherence values can be compared. A summary is
given in figure 43.
648For the figure, the mean coherence of all the topics in a
topic model was calculated. This was done for each combination of the number
of topics and optimization intervals. As there are five different models for
each setting, their mean coherences were averaged. The results show two
trends. First, the coherence of the topics tends to decrease with an
increasing number of topics, and second, the coherence also decreases when
the optimization intervals are bigger (so that the hyperparameters are
optimized less often). What can also be seen is that the values drop more
for bigger optimization intervals than for higher numbers of topics. It
makes sense that less optimization leads to topics that are “further away”
from the actual distribution of words in the corpus so that the topics tend
to be more abstract. It is more difficult to explain that higher topic
numbers produce less coherent topics. A hypothesis for this is that with
more topics, many of them are more special, so it is less probable that
texts containing some top words of a topic also contain all the others.
Interestingly, though, the coherence values go up again from 90 to 100
topics for the lower optimization intervals. Regarding the usage of the
topic models for subgenre categorization, the coherence values are of
interest in two ways. One is the question of whether models with more
coherent topics are better feature sets for classification, and the other is
whether a better formal coherence of the topics also facilitates their
interpretation as features related to the subgenres. Four example topics are
shown in figure xxx to get an impression of the kind of topics that are part
of the different models.

649Each word cloud depicts one topic and includes its 40 most important words. The top left topic stems from a model with 50 topics and an optimization interval of 50, and the top right from a model also with 50 topics but without hyperparameter optimization. The bottom left topic is part of a model that has 100 topics and an optimization interval of 50, and the bottom right topic was produced in a model also with 100 topics but without hyperparameter optimization. With optimization, the topics can be ranked because they can have different overall probabilities in the corpus. The tenth most important topic was selected from the two models with optimization (as indicated by the first number in parentheses after the topic number). Although the overall number of topics is different in the two models, the tenth topic is similar in both. Without optimization, all the topics in the model have the same weight in the whole corpus, so of the two models without optimization, two topics with similar words were selected. The two topics to the left can be interpreted as representing a ball. In the top left topic, the three most important words are “baile”, “salón”, and “amor”, and in the bottom left one, “baile”, “salón”, and “brazo”. The other words in the topics are also related to a ball situation and cover music, dance, social life and conversation, and dresses. The main difference between the topic from the 50-topics model and the one from the 100-topics model is that in the former, words about love and family relationships are more prominent (“amor”, “mamá”, “novio”, “corazón”, and “papá”), suggesting that here the ball situation is connected with central plot elements, whereas the latter has a stronger focus on the ball as a social event and seems to be more descriptive, and hence more specialized (“brazo”, “traje”, “movimiento”, “efecto”, “concurrencia”, “reunión”). The two topics to the right can be interpreted as covering travel to or in a city. In the topic from the 50-topics model, the three most important words are “coche”, “carruaje”, “ciudad”, and the three top words in the topic from the 100-topics model are “coche”, “carruaje”, and “cochero”. As in the case of the ball topics, also here the first topic includes some top words which add elements from another type of situation. The word “hotel” is more important in that topic than in the second one, and there are the words “mesa”, “juego”, “jugador”, “reloj”, and “oro”, which seem to describe a situation at a gaming table. Such a subtopic is not noticeable in the second topic. Overall, from the point of view of a human interpreter, all four topics stemming from models that were created with different topic modeling parameters have good quality and are semantically coherent, with differences only on the level of detail. Interestingly, the two topics from the 100-topics model give a more coherent impression than the two topics from the 50-topics model, which is contrary to the outcome of the MALLET diagnostics and shows that the degree of formal coherence does not necessarily coincide with the semantic coherence that can be observed in the topics by a human interpreter. In any case, topics as semantic features are mostly easy to interpret, so it can be expected that the feature sets resulting from topic modeling are useful for gaining new insights into the subgenres of the novel.
650Two types of categorization methods are used to analyze the novels of Conha19. These are based on the sets of general features (most frequent words), and of semantic features (topics) that were presented in chapter 4.2.1 above. As a first step, a classification is applied. It aims primarily to select the best feature set of each type (general and semantic). It also has the purpose of examining how well the novels can be classified by subgenre at all. This is done in chapter 4.2.2.1. As a second step, a family resemblance analysis is conducted in chapter 4.2.2.2, which is based on text similarity calculations and rankings, network analysis, and community detection. This specific combination of techniques is proposed here as one possible implementation of the family resemblance concept. In contrast to the classification, the family resemblance analysis does not start from predefined subgenre labels. It is an open and exploratory technique that uses the similarities between the texts of the novels – as represented in the feature sets – to group them. Only afterwards are the resulting families of texts compared to the subgenre labels and other metadata categories. By using the kind of feature sets that were successful also in the classification tasks, the family resemblance analysis starts from a reliable basis regarding the relevance of the features for categorization by genre. On the other hand, the influence of other contextual and textual factors, such as authorship, time period, country, narrative perspective, or setting, on the resulting categories, can be better explored in a bottom-up approach, i.e., in a feature-based categorization approach without prior labeling of the texts. The family resemblance analysis also has the advantage that the categories are constituted based on a network of relationships between individual texts. It does not presuppose that every feature is present in every text in the same way. Partial overlaps in the feature distributions are enough to connect the texts. Like that, texts can be distinct in detail but similar in general and still be grouped together. This is a second kind of openness of the family resemblance method compared to classification. The details about the two methods are discussed in the respective subchapters, including the algorithms and implementations used to apply them.
651In the bibliography and the corpus, all kinds of subgenre labels were collected for the novels and sorted according to a discursive model for subgenre terms. A quantitatively relevant selection of them was analyzed on a metadata level in chapter 4.1.5.3 (“Subgenre Labels Selected for Text Analysis”). In this chapter on categorization, further selections are made for constellations of subgenres that are analyzed on the textual level. There are several reasons for the selections. First, critical literature is only available for some of the discursive levels of subgenre terms and only for some of the subgenres on those levels. The existence of critical approaches to the subgenres is important in order to be able to formulate hypotheses based on previous knowledge and research results. In addition it shows which subgenres have been at the center of interest of literary scholars. Referring back to the existing discourse on subgenres of the novel in literary scholarship increases the chance that the quantitative text analytical approaches also find a response there. Furthermore, there is the chance that previous results are confirmed or critically examined from a different methodological standpoint. On the other hand, discursive levels of subgenre terms and specific types of subgenres that have not been the focus of literary scholars yet can be a new ground that is worth exploring with the help of digital text analysis. As formulated in the chapter on the features (see chapter 4.2.1 above), in these cases, the main hypothesis to be checked is whether there is any detectable and significant relationship between the subgenre labels and the texts. Here, the focus is on the quantitatively and qualitatively most relevant and critically established subgenres from the levels of theme and literary current. As thematic subgenres, the three subgenres with the most frequent primary labels in the corpus have been selected: historical novels, sentimental novels, and novels of customs. For the literary currents, romantic, realist, and naturalistic novels are compared.
652With this selection, two levels of the discursive model of subgenre terms are covered, and different types of label sources are included. The labels related to theme and literary current are critically established, preferably based on interpretations made by other scholars who have classified the novels in question. If no such classifications were available, the labels were assigned by the author of this study based on explicit and implicit subgenre signals that were collected and encoded in detail for the novels in the corpus.560 Another aspect that has been pointed out here is that one novel can have several different subgenre labels, even on a single discursive level. As a simple approach to model multiple subgenre terms of the same kind, one primary label was selected for the levels of theme and literary current, marking the remaining ones as secondary. In the classification analysis, these primary labels are employed. Another option would have been to conduct a multilabel classification, allowing one text to pertain to several different subgenres at once. A text analysis considering this more complex and, at the same time, diffusing modeling of subgenre assignments is left as a future task. Furthermore, the textual analysis of the difference between critically established thematic labels, on the one hand, and purely explicit and historical thematic labels, on the other hand (i.e., above all the novelas históricas and the novelas de costumbres), is not conducted here. It is assumed that such an analysis will bring to light different nuances of the historical and the current contemporary conceptions of the subgenres, and to capture these on the level of the texts is considered an advanced task for the future. However, as the metadata about the subgenre terms and their assignment to the novels has been captured on all these levels, the information can still be used to analyze their impact as influencing factors on the results of the text analysis, together with the other metadata categories. It can be expected that a reduced setup of subgenre comparisons leads to clearer results and facilitates their interpretation, especially when an open approach such as the family resemblance analysis is used. As there are no simple measures to evaluate the categories emerging from a network-based approach yet, a manual inspection of the results and underlying feature distributions is indispensable in that case.561
653The method which is used here to group the novels into discrete classes of texts is statistical classification, as it is defined and implemented in the context of machine learning. According to Alpaydin, machine learning is
programming computers to optimize a performance criterion using example data or past experience. We have a model defined up to some parameters, and learning is the execution of a computer program to optimize the parameters of the model using the training data or past experience. The model may be predictive to make predictions in the future, or descriptive to gain knowledge from data, or both. (Alpaydin 2016, 3Alpaydin, Ethem. 2016. Machine Learning: The New AI. Cambridge, Mass.: The MIT Press.)
654Machine learning is applied in cases in which it is very difficult or not possible to know the rules that connect a certain type of data to a characteristic that is attributed to this data. In the case of genres, this means that there are texts about which we have some knowledge: we know, for example, which words are used in the texts, how they are organized syntagmatically, to which grammatical categories they belong, and so on. On the other hand, we know that certain texts belong to specific genres because it is indicated in the paratexts of their publication, because the books they are published in are offered in a genre-specific section of a bookstore, because some literary scholar has said that they belong to a genre, etc. We may have some ideas about how the input characteristics of the texts are related to the output labels, but we do not know enough to be able to design corresponding algorithms for the computer that could convert the input (the features) to the output (the category labels) in a direct way.
655In machine learning, the computer uses the data that has been labeled with some output value to learn the rules from it. This is done by using a model of a predefined type (for example, a linear model aiming to describe connections in the data with linear relationships), and adapting and optimizing this model by setting its parameters in a way that fits the data and their labels best. The goal of training such a model is to be able to automatically label new cases of the data by applying the trained model to them, i.e., to make predictions. In the case of genre, this would mean being able to assign a genre label to a new, unknown text by handing it to the computer. As Alpaydin states, another goal can be to inspect which part of the data the computer used to make the predictions to learn something about the rules that connect the input data to the output labels. For the genres, this would mean reproducing which features of the texts, for example, the frequency of a certain word or the distribution of word categories, really are relevant for the decision to assign the texts to certain genres.562
656Approaches in machine learning are broadly classified into unsupervised and supervised learning methods. In an unsupervised case, knowledge is extracted from the data without information about some output value or category. The data may, for example, be grouped based only on how the features are distributed. In a supervised approach, on the other hand, a specific outcome is known for a given input. Classification belongs to the latter group because the goal is to find a model for the relationships between the input data and the output class labels (Müller and Guido 2016, 27, 133Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.).
657Usually, the aim of a trained machine learning model, or more specifically, a classifier, is not just to be able to treat the data from which it has learned. Instead, it should be a general model, in the sense that it can differentiate between instances of the classes independently of the specific data set. For the corpus of nineteenth-century Spanish-American novels at hand, for instance, this implies that a classifier trained to recognize the difference between historical and non-historical novels should be able to make correct predictions for another corpus. A different corpus may be built using the same population of nineteenth-century Spanish-American novels as represented in the bibliography but selecting different authors and works. This would mean that the classifier can tell us something about the general difference between historical and non-historical novels of that period and cultural-geographical context, and not just about how the genre novela histórica is realized in the specific works in the selected corpus. By training a classifier not just on nineteenth-century but also on twentieth-century novels, one could create a model that is independent of the time period and learn a more abstract data-based concept of the historical novel. Similarly, also the cultural-geographical and linguistic context could be broadened or narrowed down, for example, to only learn about the historical novel in Mexico. As in literary studies in general, these examples show that also in digital literary studies applying machine learning and classification, the design of the corpus is decisive for the kind of conclusions that can be drawn from the text analysis results.563
658To be able to build a model that is general for the selected context, a supervised machine learning task is usually performed in several successive steps. First, part of the data is used as a training set to build the model and find the best parameters for it. Another part of the data is kept as a validation set to be able to check how well the model performs if it has to classify data on which it has not been initially trained. Subsequently, the model is refined by adjusting its parameters so that it performs best on the validation set. That way, the validation set becomes part of the training process of the model. By repeating the process of splitting the data into different training and validation sets (cross-validation), the effect of random chance in selecting a specific training set can be reduced. The parameters of the model should be fit in a way that makes the model neither too specific for the data (overfitting) nor too general (underfitting) (Alpaydin 2016, 39–41). If, for example, a model is built with the goal of differentiating between historical and sentimental nineteenth-century Spanish-American novels, but the training set is dominated by a certain type of historical novel, then it would be disadvantageous if the model learns too many details about the special types of historical novels when compared to sentimental novels. Such special types of historical novels are, for example, novels that were part of large series of historical novels published by a few Mexican authors, such as the “Episodios nacionales mexicanos” (1902–1903, MX) by Victoriano Salado Álvarez, or the “Leyendas históricas de la independencia” (1886–1913, MX) by Ireneo Paz. If other types of historical novels are presented to the model as a test case, it could happen that the specialized model is not able to classify them correctly. This could happen, for instance, if an individual Argentine or Cuban novel dealing with the conquest or colonial times is presented to a model trained with Mexican historical novels. Such a model would be overfitting. Conversely, if a model does not predict the classes of the data it was trained on well, it has probably learned too little about the data structures representing the classes and is underfitting. Finally, a fully trained and validated model can be used with a third part of the data, the test set, which has not been part of the training cycle at all.
659Obviously, not just the type of model and the selection of the best parameters for it are decisive for the quality of a classification task, but also how – based on what data – the instances of the classes are represented in the machine learning process. The selection of the text features for genre classification should be based on good hypotheses about their relevance for the problem. Here, it was decided to use the most frequent words and topics as two comparatively generic types of features to classify the nineteenth-century Spanish-American novels by subgenre. Both types of features have already been used successfully in the classification of literary genres and other text types. Hettinger et al. (2016 Hettinger, Lena, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2016. “Classification of Literary Subgenres.” In DHd2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts. Universität Leipzig 7. bis 12. März 2016, 160–164. Duisburg: nisaba verlag. https://doi.org/10.5281/zenodo.4645368.), for instance, used the 3,000 most frequent words, the 1,000 most frequent character 4-grams, and topic models to classify a corpus of German nineteenth-century novels by subgenre. They achieved accuracy scores between 70 and more than 90 %, depending on the feature set used and on the constellation of subgenres. Schöch (2017cSchöch, Christof. 2017c. “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.” Digital Humanities Quarterly 11 (2). https://web.archive.org/web/20230211105751/http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html.) classified French dramas of the Classical Age and Enlightenment by subgenre, using a set of topic models with varying parameters. In Schöch’s study, the accuracy reached between 70 and 87 % for different numbers of topics, optimization intervals, and classifiers. Schöch also tested to classify the dramatic subgenres based on the most frequent words. He found the best results with 3,500 MFW and a z-score transformation of the word frequencies.
660Although the most frequent words and topics are quite different types of features, both cover much of the underlying textual material. The hypotheses that the distributions of most frequent words and topics in the texts can be related to subgenre distinctions are fairly general.564 By testing different sets of the two types of features, the results of the classification can help to refine the hypotheses about the features’ relevance to capture the differences between the subgenres.565
661Regarding the type of model used for the classification, it was decided to compare three different kinds of classifiers: k-Nearest Neighbours (KNN), linear Support Vector Machine (linear SVM), and Random Forest (RF). By comparing the results of different classifiers, it can be assessed if the different feature sets work well or not with all of them or if this depends on the kind of classifier. The importance that single features have in the classification process can also be checked by comparing their relevance in different models. In general, many different algorithms for supervised machine learning with many variants exist.566 A type of classifier that has repeatedly shown very good results for the classification of literary texts is the linear SVM (Bei 2008Bei, Yu. 2008. “An Evaluation of Text Classification Methods for Literary Study.” Literary and Linguistic Computing 23: 327–343. https://doi.org/10.1093/llc/fqn015.; Hettinger et al. 2015 Hettinger, Lena, Martin Becker, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2015. “Genre Classification on German Novels.” In Proceedings of the 26th International Workshop on Database and Expert Systems Applications (DEXA), 249–253. Valencia. https://doi.org/10.1109/DEXA.2015.62., 2016 Hettinger, Lena, Isabella Reger, Fotis Jannidis, and Andreas Hotho. 2016. “Classification of Literary Subgenres.” In DHd2016. Modellierung – Vernetzung – Visualisierung. Die Digital Humanities als fächerübergreifendes Forschungsparadigma. Konferenzabstracts. Universität Leipzig 7. bis 12. März 2016, 160–164. Duisburg: nisaba verlag. https://doi.org/10.5281/zenodo.4645368.; Schöch 2017cSchöch, Christof. 2017c. “Topic Modeling Genre: An Exploration of French Classical and Enlightenment Drama.” Digital Humanities Quarterly 11 (2). https://web.archive.org/web/20230211105751/http://www.digitalhumanities.org/dhq/vol/11/2/000291/000291.html.). This algorithm has been described as giving good results for high-dimensional data sets and also for data sets that are sparse (Müller and Guido 2016, 69Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.). These are both typical characteristics of features that are extracted from texts, which might explain why SVMs work so well for literary text classification. The KNN algorithm is comparatively simple and can be considered a baseline option against which the results of the other classifiers can be checked. It is not expected to work well with high-dimensional and sparse datasets, though. RF classifiers do not tend to work very well with such data either (Müller and Guido 2016, 37, 46, 90Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.). Nevertheless, they are widely used and approach the data in an entirely different way than SVMs, so that it is worth testing them as an alternative algorithm. Furthermore, the dimensionality and sparseness of the different feature sets prepared for the corpus varies, as was shown in the chapters 4.2.1.1 and 4.2.1.2 above. A set with a lower number of topics or less MFW might also work well with KNN or RF.
662The three chosen algorithms depend on different parameters that need to be set before the models are trained with data. Because much variance is already introduced here by selecting different feature sets and different types and constellations of subgenres that are to be analyzed, it was decided not to vary the model parameters systematically for all settings but to conduct preliminary tests with selected feature sets and subgenres. The parameters that turn out to be good choices in this preparatory step are chosen and fixed for the subsequent experiments. In the following table 34, the parameter values that were tested are given for the three classifiers in question.567
| Classifier | Parameter | Parameter values |
|---|---|---|
| KNN | n_neighbors | 3, 5, 7 |
| KNN | weights | uniform, distance |
| KNN | metric | Manhattan, Euclidean |
| SVM | C | 1, 10, 100, 1000 |
| RF | max_features | sqrt(n_features), log2(n_features) |
663KNN classifies new data by looking for the nearest data points for which the class is known (the neighbors). The class to which most of the nearest neighbors belong is assigned to the new data. For this algorithm, three parameters are varied: the number of neighbors taken into consideration for the classification decision, the method applied to weight neighbors, and the distance metric used to calculate how far the neighbors are away from the data point in question. A uniform weight means that all neighbors have the same influence on the decision, whereas a distance-based weight means that neighbors that are nearer are weighted higher than neighbors that are further away (Müller and Guido 2016, 37–38Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.; Scikit-learn developers 2007–2023jScikit-learn developers. 2007–2023j. “sklearn.neighbors.KNeighborsClassifier.” Scikit-learn. https://web.archive.org/web/20230304131239/https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html.). The difference between the Manhattan and the Euclidean distance is that the former sums up the differences between every feature for the two texts that are compared, and the latter uses the direct distance of the two feature vectors (Evert et al. 2017, ii7Evert, Stefan, Thomas Proisl, Fotis Jannidis, Isabella Reger, Steffen Pielström, Christof Schöch, and Thorsten Vitt. 2017. “Understanding and explaining Delta measures for authorship attribution.” Digital Scholarship in the Humanities 32 (Supplement 2): ii4–ii16. https://doi.org/10.1093/llc/fqx023.).568
664As a linear SVM belongs to the class of linear models, it uses a linear function of the input data to make predictions about new data. In such a function, a weight (coefficient) is determined for each feature, and the prediction can be understood as “a weighted sum of the input features” (Müller and Guido 2016, 47Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.).569 If it is smaller than zero, the negative class is predicted; otherwise, the positive class is. That way, the linear function that is learned defines a decision boundary for the classification. The most important parameter to vary in an SVM is the C parameter, which regularizes the learning process. The higher the value of C is, the more the model tries to learn a function that fits the training data in the best possible way, and a lower C means that the model tries to find low coefficients (Müller and Guido 2016, 58–60Müller, Andreas C., and Sarah Guido. 2016. Introduction to Machine Learning with Python: a Guide for Data Scientists. Sebastopol, CA: O’Reilly.). The C parameter is thus directly connected to the question of over- and underfitting. As SVMs are sensitive to different feature scales, for this classifier, all the feature sets except the ones based on z-scores were further processed by rescaling them to a range of 0 to 1.570
665Random Forests use an ensemble of decision trees to make
predictions. Decision trees learn a set of rules involving if-else
questions. The rules are processed hierarchically until they lead to final
decisions (Müller and Guido
2016, 72Müller, Andreas C., and Sarah Guido. 2016.
Introduction to Machine Learning with Python: a Guide for Data
Scientists. Sebastopol, CA: O’Reilly.). The advantage of random forests over simple decision
trees is that they are less likely to overfit because each tree in the
collection differs from the others, and the effects of overfitting can be
reduced by averaging the results. To achieve that the trees are different,
randomness is introduced into the learning process by selecting varying data
and features for each decision tree.571 Each node in the decision process uses a subset of the
features (Müller and Guido
2016, 85–86Müller, Andreas C., and Sarah Guido. 2016.
Introduction to Machine Learning with Python: a Guide for Data
Scientists. Sebastopol, CA: O’Reilly.). The max_features parameter controls how
many of all the features are made available to each decision node in the
trees.
666Table 35 lists the selected feature sets and subgenre constellations that were tested in the preliminary study with different classifier parameters, to be able to decide on which ones to use for the subsequent classification tasks. The various combinations result in 88 different settings.
| General features | Topic features | |||
|---|---|---|---|---|
| MFW | Token units | Normalization | Topics | Optimization interval |
| 100 1000 5000 |
word word 3-grams character 3-grams |
tf-idf z-scores |
50 100 |
100 1000 |
| Subgenre constellations | ||||
| novela histórica versus others | ||||
| novela romántica versus others | ||||
| novela sentimental versus novela de costumbres | ||||
| novela realista versus novela naturalista | ||||
667An important point when selecting the training and test data for the classification is the size of the different classes, that is, the number of novels in each class. Because the number of novels for each subgenre differs in the corpus, undersampling is used here as a strategy to balance the classes. This means that the number of instances of each class is set to the size of the smallest class. There are, for example, 116 romantic novels and 85 non-romantic novels in the corpus. With undersampling, the subgenre constellation “novela romántica versus other” is performed with a set of 85 romantic novels, which are selected randomly from all the romantic novels, and 85 non-romantic novels. The undersampling process is repeated ten times for each setting to make sure that the random selection does not have too much influence on the results. For the topic models, all five models that were produced for each combination of topic modeling parameters are used, and the resulting scores are averaged.
668In the parameter study, grid search classifications are performed for each type of classifier, with the different classifier parameters and for each feature and data combination. A grid search consists in creating a grid of parameter values, for example, the different values for the number of neighbors and metrics for KNN, and running a set of classifications to find out which combinations of the parameters work best. A method that facilitates this procedure in the context of Machine Learning is scikit-learn’s GridSearchCV, which was used here (Scikit-learn developers 2007–2023iScikit-learn developers. 2007–2023i. “sklearn.model_selection.GridSearchCV.” Scikit-learn. https://web.archive.org/web/20230304131032/https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html.). The method includes the possibility of performing cross-validation. Here, 10-fold cross-validation was used, meaning that each combination of parameters is tested in ten different splits of training and test data.572 Part of the results that Scikit-learn’s GridSearchCV function returns are the ranks of the different parameter values resulting from average test scores over all folds. Here the results of the parameter study were evaluated by counting how often each parameter value had the first rank, that is, how often it led to the best mean accuracy test score.573 That way, the test scores themselves are not considered, so rather than finding the parameter values which lead to the highest scores for specific data and feature combinations, it was analyzed which values yield the best score most often for all the different settings. The goal was to find parameter values that are generally a good choice so that they could be used for all the following analyses. However, as the classifications were performed separately with the two main feature types (general, MFW-based features versus topics),574 different parameter values were chosen for them whenever the results of the parameter study suggested that. The main reason for keeping the main types of feature sets separate is to allow for their interpretation in terms of different levels of text style.
669The results of the parameter study for the KNN classifier are
summarized in figures 45 to
47 for the three parameters n_neighbors,
weight, and metric. Concerning the number of
neighbors that are decisive for the classification, all three candidates (3,
5, and 7) reached the first rank almost equally often. A number of 7
neighbors is a bit better than fewer ones (for MFW and for topic features),
so this number was used in all the following experiments. Why could a higher
number of neighbors be advantageous? One hypothesis is that the novels’
individual feature distributions must be checked against several neighboring
ones to be able to decide on the subgenre, which means that resemblances to
several works are more relevant than the similarity to a few works that
represent the subgenre in a homogeneous way.
n_neighbors (KNN).
weights
(KNN).
670Regarding the method used for weighting the influence of the neighbors on the classification decision, distance-based weights work better than uniform weights for both feature types, only slightly in the case of MFW and a bit more for topics, as figure 46 shows. Even in this case, the difference between both types of weighting is not striking. A hypothesis to explain the tendency towards distance-based weighting is that the novels rather form classes on relationships of similarity between individual works than on uniform similarities to several other works.
671The difference in performance between the parameter values is
clearest for the metric, as shown in figure 47. The Manhattan distance works best in more than half of
the cases. Both for MFW and even more for topics, the Manhattan distance
reaches the top mean accuracy test score more often than other metrics. This
shows that measuring the distance between the feature vectors as they are in
the different dimensions (with tf-idf or z-scores) works better than
measuring the distance between the vectors in one step. So distances between
individual features play an important role in the classification by
subgenre. To summarize, for KNN, the parameters are set to 7 neighbors,
distance-based weights, and Manhattan metric.
metric
(KNN).
672For the SVM classifier, only the C parameter was tested. The
results in figure 48 show that
the value 1 works best for topics. For MFW, a value of 100 leads to the best
mean score more often than other values, but the differences are small. As a
lower value of C means that the coefficients for the linear model are
preferably lower so that the model is less specialized on the data it is
trained on, the models that are built with it are more general, which, in
principle, is good. A hypothesis to explain that a lower value of C is much
better with topic features and not so decisive with MFW is that topics are
primarily content-related. When the topics are too specific, they might not
be characteristic of the subgenres of the novel but rather of individual
texts. Primarily stylistic features, on the other hand, are more flexible
when a classifier uses them to build models for subgenres. Because of these
results of the parameter study, in the following analyses, the C parameter
is set to the value 1 for the topic features and to the value 100 for
MFW-based features.
C
(SVM).
673For the third classifier, RF, it was tested whether the
maximum number of features used in each tree is better determined by taking
the logarithm to the basis 2 or the square root of the overall feature
number. The results in figure
49 indicate that the square root is more successful for both MFW and
topic features, so this parameter value is used for RF in the following.
With the square root, the number of features chosen is higher than with the
logarithm. In addition, it increases faster with an increasing number of
features, so using more of the features that are available is especially
useful when decision trees are built based on MFW, but also when they are
built based on topics.
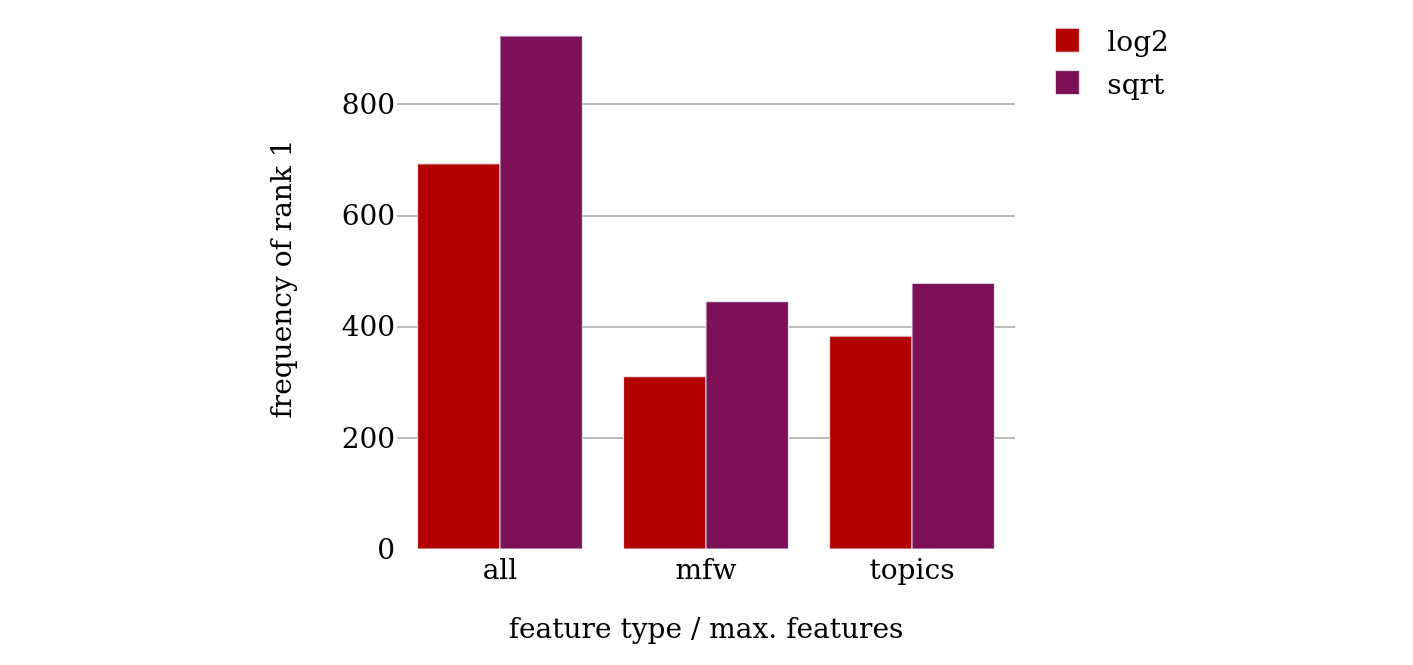
max_features (RF).
674A conclusion to be drawn from the different results of the parameter study for the three classifiers and their respective parameters is that the choice of the parameter values does not make all the difference for the classification results. All of the parameter values reached rank 1 for several data and feature sets, but some are more successful in the majority of cases. By fixing the values for subsequent analyses, a common basis is found for comparing classification results for different subgenres and feature sets, even if this means that for some constellations, the results could still be improved by adjusting the parameters individually.
675Before the classification results are presented in the
following subchapters on thematic subgenres (4.2.2.1.1) and literary currents (4.2.2.1.2), the general
classification workflow is outlined here. In a first step, the discursive
level on which subgenres are analyzed is chosen (i.e., theme or
current). Then the individual subgenres which are contrasted
on each level are selected, for instance, novela histórica
versus novela sentimental or novela histórica
versus all other novels. To keep the evaluation of the classification
results simple and comparable, only two classes are used each time. For
these, the data is selected so that the classes have the same size. As said
before, the data selection process is done randomly and repeated ten times
to make sure that the results do not depend on the specific selection. If
the two classes always have the same size, the classification baseline can
be set at 50 % for all the constellations. Next, the classification is
performed with the three types of classifiers and all the different feature
sets that were prepared. The classifier parameters are fixed with the values
that were chosen in the preliminary parameter study, and the classification
is performed with 10-fold cross-validation. A graphic overview of the
classification workflow is given in figure 50.575
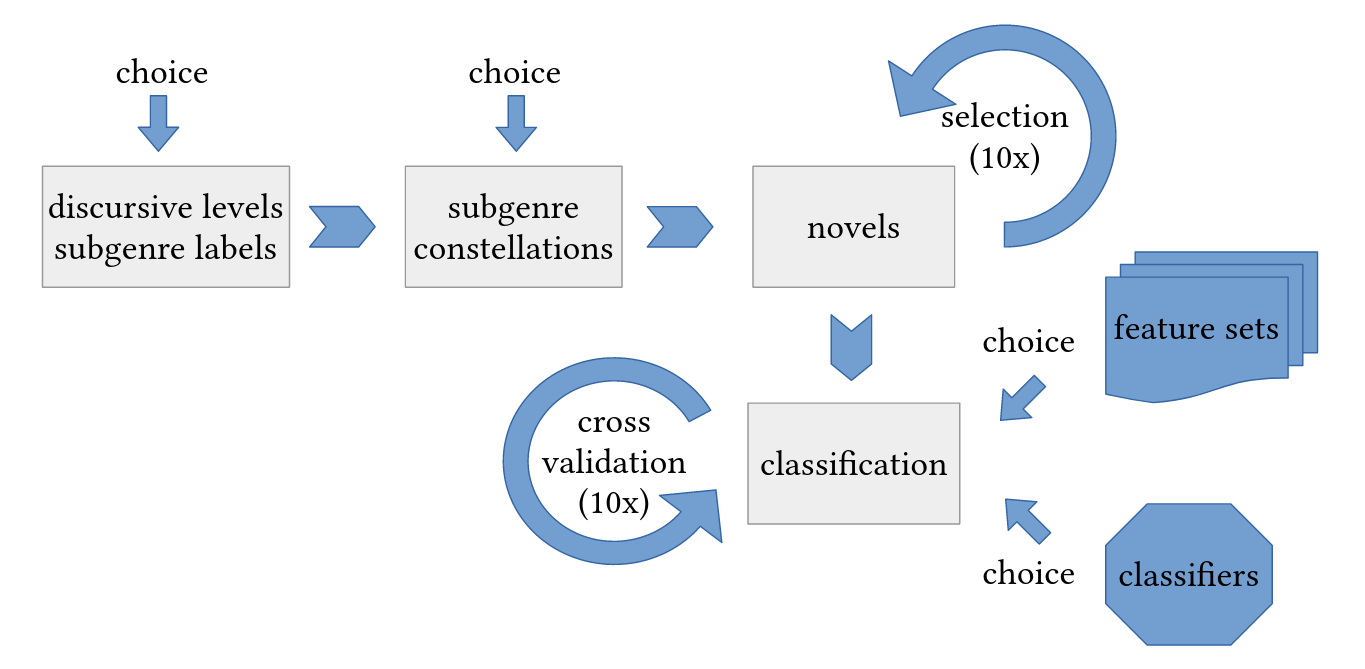
676The results are evaluated to find out which sets of MFW-based and topic features work best with which classifier. The best constellation of classifiers and features is chosen for each discursive level. Following the assumption that different kinds of features and hence different levels of style can be decisive for the various discursive levels of subgenres, independent decisions are made for thematic subgenres and literary currents. However, for the different subgenre constellations on the same discursive level, no individual choice is made. Here the best classifier, MFW-based, and topic feature sets found for the discursive level are chosen to further evaluate the results of the subgenre classification. For example, the results for the novela romántica can be directly compared to the results for the novela realista. Beyond inspecting accuracy values and F1 scores, further interpretation of the results is concerned with two aspects:
677The feature importances and classification results vary for each run with the ten different data selections in the undersampling process and the ten repetitions in the cross-validation procedure. Therefore, all the values are collected, and the average results are analyzed. For the MFW, the feature importances and classification results for the individual novels can be averaged on the level of the different feature sets (for example, for all the data selections and cross-validations performed with 100 MFW and tf-idf normalization) because the kinds of features stay the same: which ones are the 100 MFW does not change. For the topics, in contrast, it is not possible to summarize the feature importances and novel classifications on such a general level because the topic features are different in each topic model that is produced. Even if the number of topics, the iterations, and optimization intervals are fixed, the topics themselves are not consistent throughout the five topic modeling repetitions because of the probabilistic procedure. So in the case of the topics, one specific topic model must be chosen. Only then the features and the individual classifications of the novels can be evaluated and their importance can be averaged. Here, the first of the five topic models that are produced for each topic model parameter constellation is chosen as a representative.577
678In this setup, the models that the classifiers build based on specific feature sets are interpreted as sets of literary text types. They are considered sets of text types and not individual text types because the classifiers learn to differentiate between several classes. Because here only two classes are compared each time, two text types are learned, or rather, it is learned how two text types can be delimited and distinguished, one for the positive and the other for the negative class. That they depend on a specific set of textual features means that the text types are constituted on a certain stylistic level (e.g., the 1,000 MFW and all the linguistic material that is covered by them or 50 topics and all the thematic distinctions that can be made based on them). Furthermore, specific stylistic cues are determined for the text types, for instance, specific topics that have great importance as features for the classification. When the results are evaluated, several stylistic cues can be interpreted as forming stylistic traits of the literary text types in question. For instance, if several adjectives and nouns referring to opposites (e.g., good-bad, city-countryside) turn out to be significant features in an MFW-based model, these stylistic cues can be subsumed as a trait of opposites or antagonisms. When a range of different feature sets is used in several classifications to analyze the same subgenre, such traits can be collected and interpreted as different facets of a text type.
679The text types are not only represented by the classification models but also by the set of texts that participate in them. However, these texts are not equivalents of the conventional genre. It is not that the texts carrying specific labels are contrasted directly to view their features. Instead, the feature importances that result from trying to classify the novels by their subgenre label are contrasted. In the latter case, the text type consists of the texts that are repeatedly found as true positives plus the ones that are frequently determined as false positives. On the other side, the texts that carry the conventional label but do not fit textually are not included when the importance of the different features is evaluated. In the next chapter, the classification results for the thematic subgenres are presented. As the general classification workflow was already presented in this chapter, the details about the steps taken to perform the classifications are not repeated in the result sections.
680This chapter presents the results of the classification of
novels by thematic subgenres. First, the distribution of the primary
thematic subgenres in the corpus is presented in figure 51.
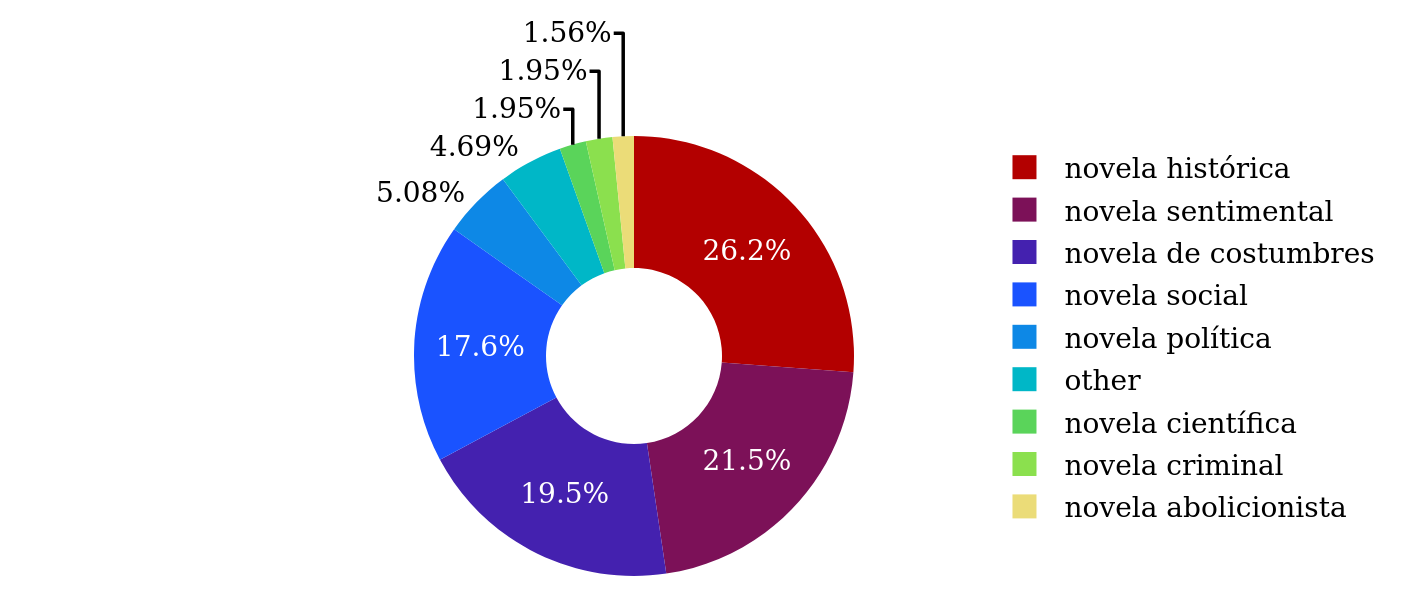
681The four most frequent types of primary thematic subgenres are the novela histórica, with 67 novels; the novela sentimental, with 55 novels; the novela de costumbres, with 50 novels; and the novela social, with 45 novels. Smaller groups are the political novels (13), the science fiction and crime novels (5 each), and the anti-slavery novels (4). The latter can also be subsumed under social novels but are marked separately because historically and by literary critics, they were categorized with this more specific label. Twelve novels participate in other primary thematic subgenres, which all occur only one to three times. The classification of primary thematic subgenres is conducted for the following selected subgenre constellations:
682With these six constellations, the three most frequent primary thematic subgenres are analyzed. They correspond to the subgenres that developed in the romantic period and to the ones that literary historians have often distinguished as relevant thematic subgenres in nineteenth-century Spanish America.578 The presentation of the results starts with the topic features and then goes on to the MFW-based ones. The results for the topic features are discussed in more detail, inspecting feature importances, numbers of correct and wrong classifications, and topic profiles of selected novels. For the MFW, the overall classification results are presented to see how well these features work, but a deeper analysis of the features and novels is left as a future task.
683First, it is analyzed which classifiers worked best to classify the thematic subgenres in all six constellations.579 For this, the accuracy and F1 score values for all classification runs were evaluated, and top values, mean values, and the standard deviation (SD) were calculated. In total, 144,000 classification runs were considered for the topic features, including all topic model parameter constellations, topic modeling repetitions, repeated data selections, and 10-fold cross-validation.580 The results for the topic features are shown in table 36.
| Classifier | Feature type | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| KNN | topics | 1.0 | 0.77 | 0.14 | 1.0 | 0.78 | 0.14 |
| SVM | topics | 1.0 | 0.80 | 0.13 | 1.0 | 0.80 | 0.14 |
| RF | topics | 1.0 | 0.80 | 0.14 | 1.0 | 0.80 | 0.15 |
684In the case of the topics, SVM and RF work best with a mean
accuracy of 0.80, but the results for KNN are also quite good, with a
mean accuracy of 0.77. The relatively high standard deviation indicates
that either the results vary for the different topic model parameters or
for the different subgenre constellations, or both. For the following,
more detailed analyses of the results, SVM is chosen because the standard
deviation is lower than for RF, even if there is only a difference of one
percentage point. Once the best classifier is chosen, the next step
consists in evaluating the feature sets in more detail. The goal is to
find out which influence the different parameter values have on the
results and to find the ones that are best suited for the classification
of primary thematic subgenres. The classification results for the
different topic modeling parameters are presented in figure 52.
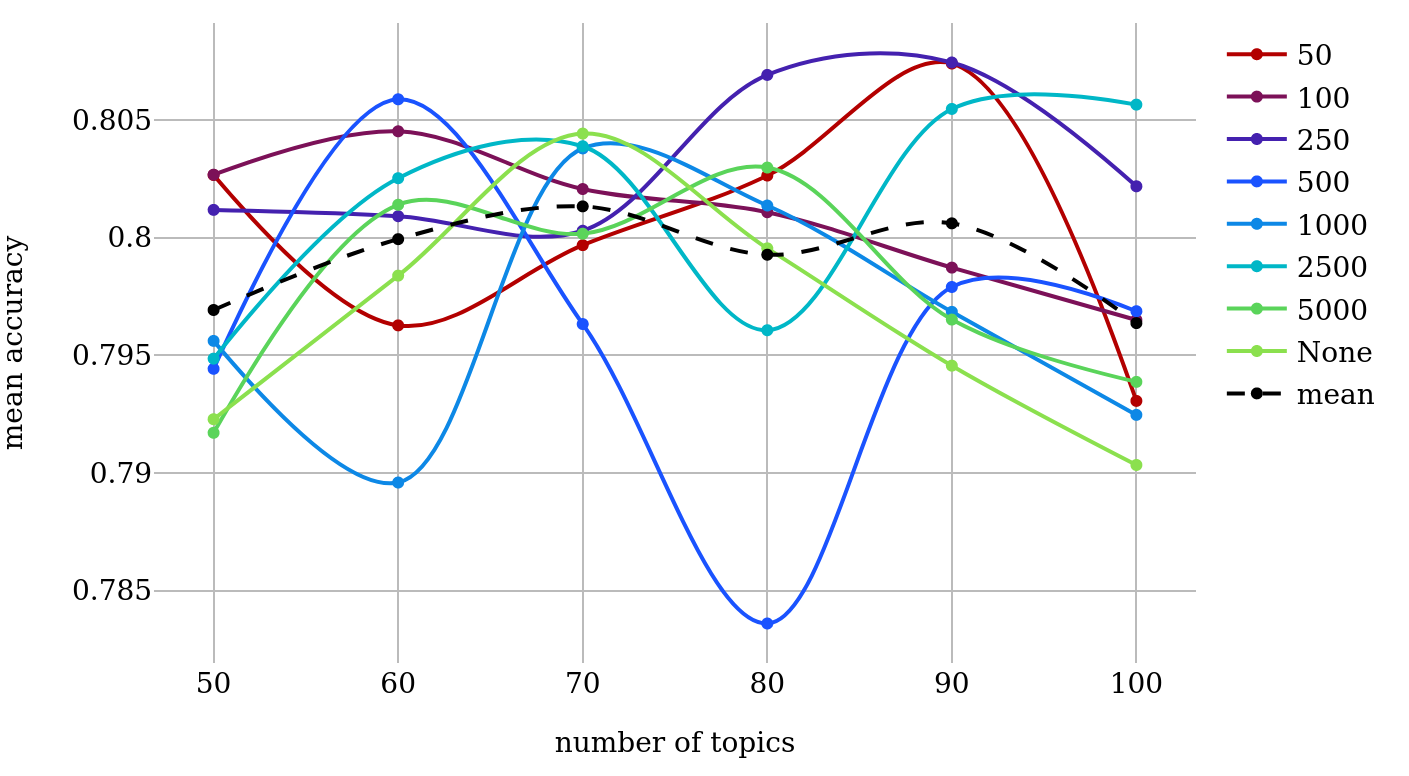
685The top mean accuracy of 0.81 is reached with several different combinations of topic numbers and optimization intervals: with 60 topics and an interval of 500, 80 topics and an interval of 250, and 90 topics and an interval of 50, 250, or 2,500.581 If one evaluates the general development of the results for different topic numbers and optimization intervals, for some intervals, there are trends, and for others, oscillations. With an interval of 100, for example, the score is highest at 60 topics and decreases for higher topic numbers. The score for no optimization at all rises up to 70 topics and then falls again. For intervals of 50 and 250, the scores get higher with more topics. Except for the interval of 2,500, which means very little optimization, all the scores drop with more than 90 topics. This suggests that the models get too specific to detect subgenres if they have more topics. Otherwise, it appears that the number of topics interacts with the optimization interval so that specific combinations which produce topics and topic distributions that are not too general and not too specific work well to model thematic subgenres.582
686Overall, the differences between the mean accuracies using different kinds of topic features are very low, ranging from 0.78 for 80 topics and an interval of 500 to the highest value of 0.81. This means that the higher standard deviation observed in the general accuracy mean for topic features is not due to the different topic modeling parameters but must be connected to the different kinds of thematic subgenres or to the influence of individual novels. With such similar results, the decision to choose a certain combination of topic numbers and optimization intervals does not only need to be based on the top mean accuracies but can also take into account the kind of topics that are likely to result from a model with a specific combination of parameters. Here, 90 topics are chosen because they lead to the highest mean score several times and also because the topics are more specific than they would be in a topic model with a lower number of topics so that the resulting text types can be described in more detail. As for the optimization interval, a number of 250 is chosen so that the topics are still relatively balanced regarding the different weights they have in the corpus and individual texts.
687Having decided on the kind of classifier to use and on the specific kinds of features, the classification results for the different constellations of thematic subgenres can now be inspected. The results for the topic models with 90 topics and an optimization interval of 250, using SVM as a classifier, are shown in table 37. These average results are based on 500 classification runs for different data samples and the 10-fold cross-validation.
| Subgenre 1 | Subgenre 2 | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| novela histórica | other | 1 | 0.82 | 0.10 | 1 | 0.82 | 0.09 |
| novela sentimental | other | 1 | 0.81 | 0.12 | 1 | 0.80 | 0.13 |
| novela de costumbres | other | 1 | 0.71 | 0.14 | 1 | 0.72 | 0.16 |
| novela histórica | novela sentimental | 1 | 0.89 | 0.11 | 1 | 0.89 | 0.10 |
| novela histórica | novela de costumbres | 1 | 0.84 | 0.10 | 1 | 0.84 | 0.10 |
| novela sentimental | novela de costumbres | 1 | 0.77 | 0.13 | 1 | 0.75 | 0.16 |
688The constellation novela histórica versus novela sentimental has the highest mean accuracy with 0.89. The second best result is reached for novela histórica versus novela de costumbres, and the third for novela histórica versus other. This shows clearly that the historical novel is the subgenre that can best be distinguished from the other two thematic subgenres that were chosen here but also from the big group of all other kinds of novels, which include not only sentimental novels and novels of customs, but also crime novels, science fiction novels, social and political novels, and more. This result confirms the expectation that the novela histórica as a subgenre, which is by convention firmly established in Argentina, Cuba, and Mexico in the nineteenth century, also is united textually. Although there are different subtypes of historical novels dealing with different past (or not-so-past) epochs and different specific topics, the subgenre can be classified well by using topic features. Furthermore, it is astonishing that it can be separated best from the sentimental novel because there are many historical novels with a sentimental plot and also because most historical and sentimental novels in the corpus are romantic novels that have much in common. This result confirms what most literary histories of nineteenth-century Spanish-American novels describe (see chapter 3.1.3 on the novela sentimental): that the sentimental novel is an important and recognizable thematic subgenre as well. After the historical novel, the sentimental novel has the second-best results. The mean accuracy for novela sentimental versus other novels is at 0.81, which is only slightly worse than for the historical versus the other novels. Apparently, the sentimental novel can be separated well from other subgenres, even if there are many novels that also have a sentimental plot. However, the results also show that this is not so easy if sentimental novels are compared to novels of customs. Here, the mean accuracy is at 0.77, which is the worst result for the direct comparisons of subgenres. This confirms what has has been remarked by Janik (2008, 67–68Janik, Dieter. 2008. Hispanoamerikanische Literaturen. Von der Unabhängigkeit bis zu den Avantgarden (1810–1930). Tübingen: Narr Francke Attempto.): that the description of local customs in novels and the expansion of the cuadros de costumbres to longer fictional narrative works in the form of novels of customs needed the sentimental plot as a basic structure, at least in the romantic variant of the subgenre. The results are even worse when the novels of customs are contrasted with all other novels (with an accuracy of 0.71), which can be interpreted as a sign that costumbrista elements are not only found in sentimental novels but also in other subgenres. As the group of other novels also contains all the social and political novels that are associated with the realist (or naturalistic) current, it might well be the case that this causes lower accuracy. The two results for the novels of customs can be interpreted as a sign of mixtures of sentimental novels and novels of customs, but also similarities of the novels of customs with other social and political novels in terms of the topics that they treat. Thus, for example, Kohut has noted that there are not only romantic, but also realistic and naturalistic novelas de costumbres (Kohut 2016, 196Kohut, Karl. 2016. Kurze Einführung in Theorie und Geschichte der lateinamerikanischen Literatur (1492–1920). Berlin: Lit Verlag.). However, mean accuracies of over 0.70 do mean that even for the novels of customs, a model can be learned that classifies the texts better than by chance, only that this thematic subgenre is textually less coherent than the others. Overall, the standard deviations for the accuracies (and F1-scores) are still quite high, which means that the results also depend on the individual novels that are selected for the training and test sets.
689The next step consists in having a look at the coefficients
that have the highest values in each subgenre constellation to inspect
the characteristics of the text types that were learned by the
classifiers. Starting with the historical novels, figure 53 shows the top 25 coefficients for the
classification of novela histórica versus novela
sentimental. As these weights are based on a specific topic
model, they represent the average weights of 100 classification runs (ten
different selections of novels and ten cross-validation runs, as
explained in chapter
4.2.2.1 above on the classification workflow). In the plot, the
topics are identified by the number they got in the topic modeling
process (0 to 89 for the 90 topics) and the three words that are most
important in each topic.583
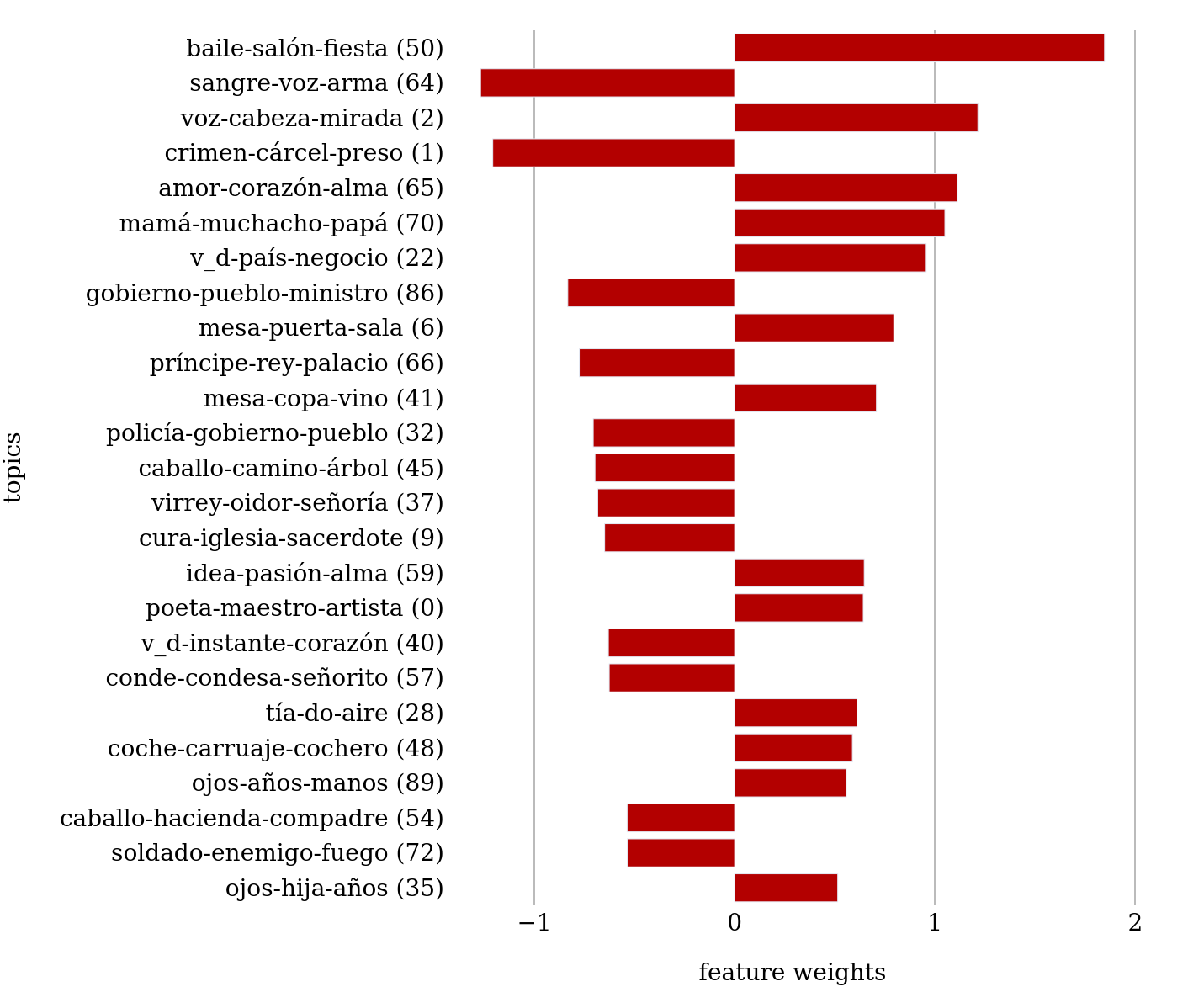
690The bars with negative values are the topics characteristic
of historical novels and those with positive values of sentimental
novels.584 The most important
topic for distinguishing historical from sentimental novels is
“baile-salón-fiesta”, which is a topic concerned with a ball situation
that is typical for sentimental novels. The second most important
distinguishing topic is “sangre-voz-arma”, this time for historical
novels. The topic covers a situation in a fight or battle. The word
clouds of the two topics are given in figure 54. It is interesting that both top
topics describe situations that are typical for the two subgenres in
question and that can be considered characteristic scenes and elements of
the plot. As the topics consist only of nouns and verbs are not included,
the dynamic aspect of the topics does not stand out directly, but even
the nouns describe actions if they are analyzed together. In the case of
the ball situation, for example, the words “mirada”, “brazo”, “sonrisa”,
“conversación”, and “palabra” point to acts of the characters. In the
fight situation, also the word “brazo” occurs, as well as “cabeza”,
“golpe”, “grito”, “espada”, “pistola”, “puñal”, “combate”, “lucha”,
“herida”, and “muerte”, so in both cases parts of the body and physical
actions are involved. The ball topic contains also words that describe
the setting of the situation, for example, “salón”, “sala”, “pieza”,
“teatro”, “flor”, “música”, “piano”, “gente”, “reunión”, “concurrencia”,
“sociedad”. That the word “teatro” is part of the ball topic could be a
sign that similar thematic elements are relevant if the situation is a
theater performance as a social event. The fight topic is less
descriptive and contains more words related to emotions and sounds:
“miedo”, “peligro”, “terror”, “venganza”, “ruido”, and “silencio”.

691All in all, the top feature weights for historical versus sentimental novels are balanced in that there are as many features that are distinctive for the historical as for the sentimental novel. They also alternate by importance in the range of top 0 to 25. Besides the fight topic, other highly weighted topic features for the historical novels are concerned with crime and prison (“crimen-cárcel-preso”), politics and administration (“gobierno-pueblo-ministro”, “policía-gobierno-pueblo”, “virrey-oidor-señoría”), monarchy and nobility (“príncipe-rey-palacio”, “conde-condesa-señorito”), the countryside (“caballo-camino-árbol”, “caballo-hacienda-compadre”), church (“cura-iglesia-sacerdote”), and another topic about battles (“soldado-enemigo-fuego”). These topics point to different subtypes of historical novels dealing with colonial and contemporary history and different urban and rural surroundings.
692Among the top topics for historical novels, there is also
one which is a bit more difficult to interpret: “v_d-instante-corazón”.
It is dominated by the historical form of address “vuestra merced”, which
is actually not a noun but was misinterpreted by the linguistic tagger
because of the abbreviation “vd”. The topic, which is shown in figure 55, is a bit more
abstract and mixed than the other top topics for historical novels. It
seems to be about physical (“pecho”, “pena”, “doctor”) and mental states
(“alma”), feelings (“temor”, “duda”, “amor”, “placer”, “satisfacción”,
“esperanza”, “corazón”, “desgracia”, “felicidad”), and thoughts
(“pensamiento”, “idea”), but it also contains other words that are not
related to these aspects. The words “instante”, “puerta”, and “vista”
together with “fisonomía”, “cabeza”, “rostro”, “gracia”, and “virtud”
seem to describe a moment in which someone is observed and the appearance
of a person is described. The impression that this topic gives is that it
joins together several thematic aspects that are not prototypical for
historical novels but are accompanying material related to the plots and
the representation of the characters’ feelings.
693Besides the ball topics, the other top distinctive topics
for sentimental novels cover private conversation (“voz-cabeza-mirada”),
love (“amor-corazón-alma”, “idea-pasión-alma”), family relationships
(“mamá-muchacho-papá”), material aspects (“v_d-país-negocio”), interiors
and meals (“mesa-puerta-sala”, “mesa-copa-vino), art
(“poeta-maestro-artista”), and travel or movement
(“coche-carruaje-cochero”). The three topics “tía-do-aire”,
“ojos-años-manos”, and “ojos-hija-años” need a closer look. In the first
one, which is visualized in figure
55, the word “do” sticks out because it is not a regular Spanish
word. The novels in which this topic has the highest probability were
checked, and the “do” is a spelling error (instead of “de”) that remained
unnoticed in some of these novels.585 Moreover, the other top words of this topic
suggest that it can be interpreted as being about outward appearances and
physical encounters because it contains words referring to people
(“muchacho”, “hijas”, “mujeres”, “viejita”, “virgen”), body parts
(“cabeza”, “ojos”, “labios”), clothes (“camisa”, “pana”, “abrigo”,
“alfiler”), meeting places (“sitio”, “calle”, “playa”, “pieza”, “sillas”,
“cama”, “flores”, “vela”), and also the word “besos” and “belleza” occur
in it. The word “aire” can then be read in its sense of “look” and “airs
and graces”. The other two topics that were not directly clear from the
three top words (“ojos-años-manos” and “ojos-hija-años”) can be
interpreted better when more of the top words are considered. The first
one has mixed meanings and appears more abstract than the other top
topics for sentimental novels. It can be described as treating views,
nature, body, and time. The second one is about looking, also talking,
mainly female persons, and emotions. In the first case, the word “años”
probably refers to time, and in the second case, it may refer to
age.586 Summing up the findings
about the topics that are most important for the classifier to
distinguish historical from sentimental novels, it can be stated that
most topics can be interpreted easily from the top words and some by
examining them more closely. The topics of the historical novels are more
easily recognizable as themes, whereas some topics of the sentimental
novels are more subtle or mixed but also make sense for the concept of
the subgenre. For the aspects covered by the topics that are at first
sight less clear, it may have been favorable to also have verbs and
adjectives and not only nouns in the topics. In what follows, not all the
topics can be analyzed in the same depth as the ones that are most
distinctive for historical versus sentimental novels, and the
presentation of the results concentrates on the three top topic words
unless there are aspects that need to be clarified or are of special
interest. Nevertheless, a look into more top words of the topics and, if
needed, also into the texts of the novels shows that the topics can be
interpreted in more depth to characterize the subgenres that are
classified. The next subgenre constellation for which the feature weights
are analyzed is novela histórica versus novela de
costumbres (see figure
56).
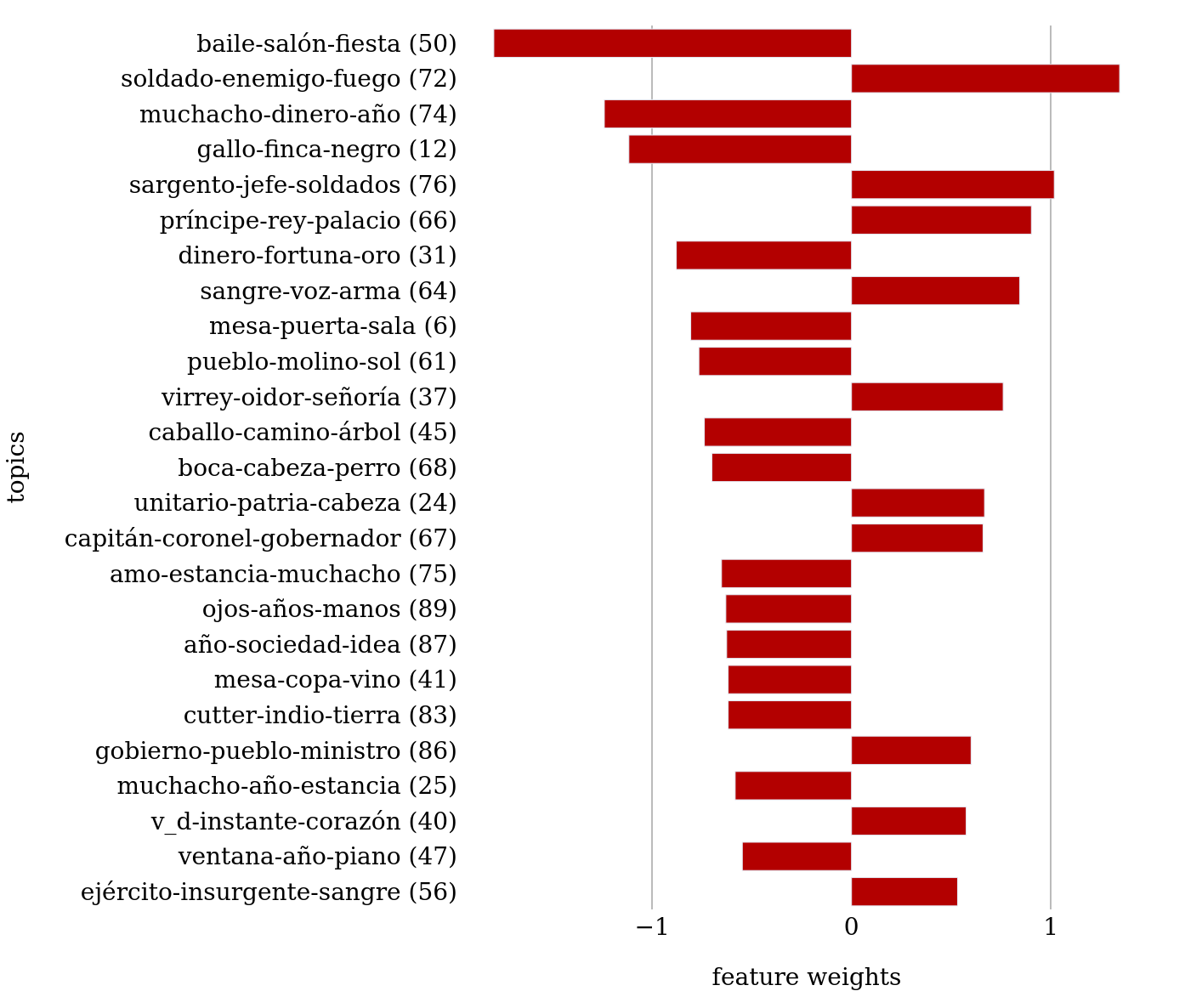
694The positive bars to the right are the topics that are
distinctive for the historical novels and the negative bars to the left
are the ones that are distinctive for the novels of customs.
Interestingly, the top topic for novels of customs is the same as for
sentimental novels: “baile-salón-fiesta”, which shows that the text types
of these two kinds of conventional subgenres have common stylistic
traits. The top topic for the historical novels is, in this case, the
topic of battles: “soldado-enemigo-fuego”. The number of top topics for
each subgenre is less balanced in this case than for the constellation
novela histórica versus novela sentimental
because, among the top 25, there are 10 topics for the historical novels
and 15 for the novels of customs. This is a sign that the novels of
customs are more diverse in terms of characteristic topics. Besides the
first one, the other topics with high weights that characterize the
novels of customs are concerned with lower class work
(“muchacho-dinero-año”), with tobacco, sugar, and coffee plantations and
work on them (“gallo-finca-negro”, “amo-estancia-muchacho”), which
clearly points to the Cuban novels, with work on a ranch
(“cutter-indio-tierra”), which is a topic that seems to be related to
cattle and sheep breeding in Argentina, with the countryside
(“pueblo-molino-sol”, “caballo-camino-árbol”, “muchacho-año-estancia”),
money, business, and gambling (“dinero-fortuna-oro”), meals
(“mesa-copa-vino”), the description of rooms (“mesa-puerta-sala”), the
description of characters (“boca-cabeza-perro”), including pets (dogs and
cats), youth and student lifestyle (“ventana-año-piano”), and reflections
about society (“año-sociedad-idea”). Of these topics, the one about meals
was also among the top topics for sentimental novels. Furthermore, the
mixed topic “ojos-años-manos” about views, nature, body, and time appears
again. Among the top topics for the novels of customs, there are several
that cover rural life and surroundings, which confirms that the
novelas de costumbres were oriented towards that sphere.
In addition, the aspect that the life and working conditions of people
are realistically described in the novels of customs becomes visible in
the top topics. Finally, there are several descriptive topics as well as
a reflective one, which is in line with the aim of the novel of customs
to represent different areas of society closely and also to provide a
social critique or vision. For inspection, the two descriptive topics
“mesa-puerta-sala” and “boca-cabeza-perro” are given in figure 57.

695The other top topics for the historical novels are very
similar to the ones that also appeared in contrasting the historical
novels with the sentimental ones, and they are semantically much more
homogeneous than the various top topics of the novels of customs. Again,
elements of colonial history and also contemporary politics are present.
A topic that is new here is, for example, “unitario-patria-cabeza”, which
is related to the struggle between Unitarians and Federalists that took
place in Argentina in the first half of the nineteenth century. The last
constellation of thematic subgenres for which the coefficients of the
linear classification model are analyzed is novela de
costumbres versus novela sentimental (see figure 58).
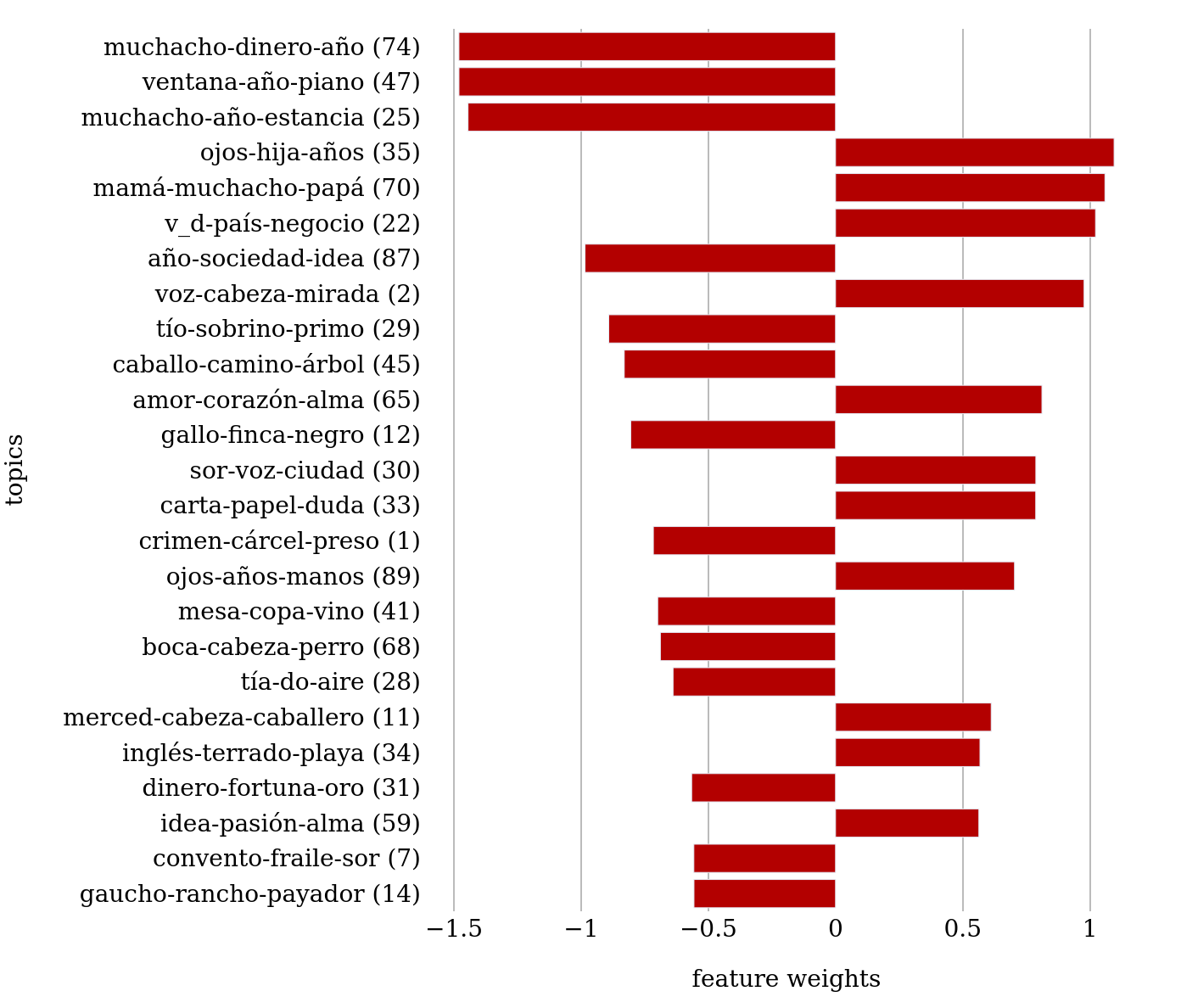
696Among the top 25 topics, there are 14 that are typical for the novels of customs and 11 that are typical for the sentimental novels. Many topics that were already relevant in the other subgenre constellations appear again, for example, the lower class work topic “muchacho-dinero-año”, the youth and student life topic “ventana-año-piano”, or the countryside topic “muchacho-año-estancia” as topics that are distinctive for the novels of customs, and the love topics “amor-corazón-alma” and “idea-pasión-alma”, as well as the private conversation topic “voz-cabeza-mirada” as topics that are typical for the sentimental novels. In addition, some new topics appear, for instance, “carta-papel-duda” for the sentimental novel, which addresses the writing and reading of letters, or “tío-sobrino-primo” for the novel of customs, which is a topic about relatives and cliques. Furthermore, some topics change the side, that is, they become distinctive for another subgenre than in the other constellations that were already examined. This is the case for the airs and looks topic “tía-do-aire”, which is now typical for the novel of customs but was important for the recognition of sentimental novels when they were contrasted with historical ones, and also for the abstract views, nature, body, and time topic “ojos-años-manos”, which was distinctive for novels of customs in contrast with historical novels and is now typical for sentimental novels when compared to novels of customs. This fluctuation shows that even though some characteristic traits of the subgenres remain constant independently of the subgenre constellation, others are relative and depend more on the kind of subgenres that are compared. The fact that topics are, in one case, typical for the sentimental novel and, in the other, for the novels of customs is again a sign of how these two subgenres are intertwined thematically. That topics are in one case typical for the sentimental novel and in the other for the novels of customs is again a sign of how these two subgenres are intertwined thematically. The plots for the constellations of the individual thematic subgenres against all other novels are not shown in detail here. What is interesting about them is that in all three cases, there are more top topics for the positive class than for the other group, which shows that the classifier focuses on the aspects that are specific for the individual subgenre that is compared to the big group of novels with many different subgenres, which makes complete sense.587
697Besides the feature importances, also the cases of correct
and false classifications of individual novels were analyzed for each
subgenre constellation, with the aim to find out how many and which of
the texts that are part of the conventional subgenres are typical or
untypical for the text types. The results of this analysis are summarized
in the form of histograms, which show the distributions of true
positives, false positives, and false negatives. The true positives are
interpreted as instances of the conventional genre, as well as of the
text type and hence of the textual genre. The false positives are
instances of the text type but not of the conventional and textual genre,
and the false negatives are part of the conventional genre but not of the
text type and, therefore, also not of the textual genre. For each novel
in the corpus, it was counted how often it fell into one of the three
groups in absolute and relative terms. As the data selection process was
random and repeated several times (ten times for the undersampling and
ten times for the cross-validation), not every novel of the corpus is
present in every classification, and some novels were classified more
often than others. The relative numbers of correct classifications and
misclassifications can still be used to examine how prototypical the
novels are for the subgenres. The chart for novela histórica
versus other novels is given in figure 59.588
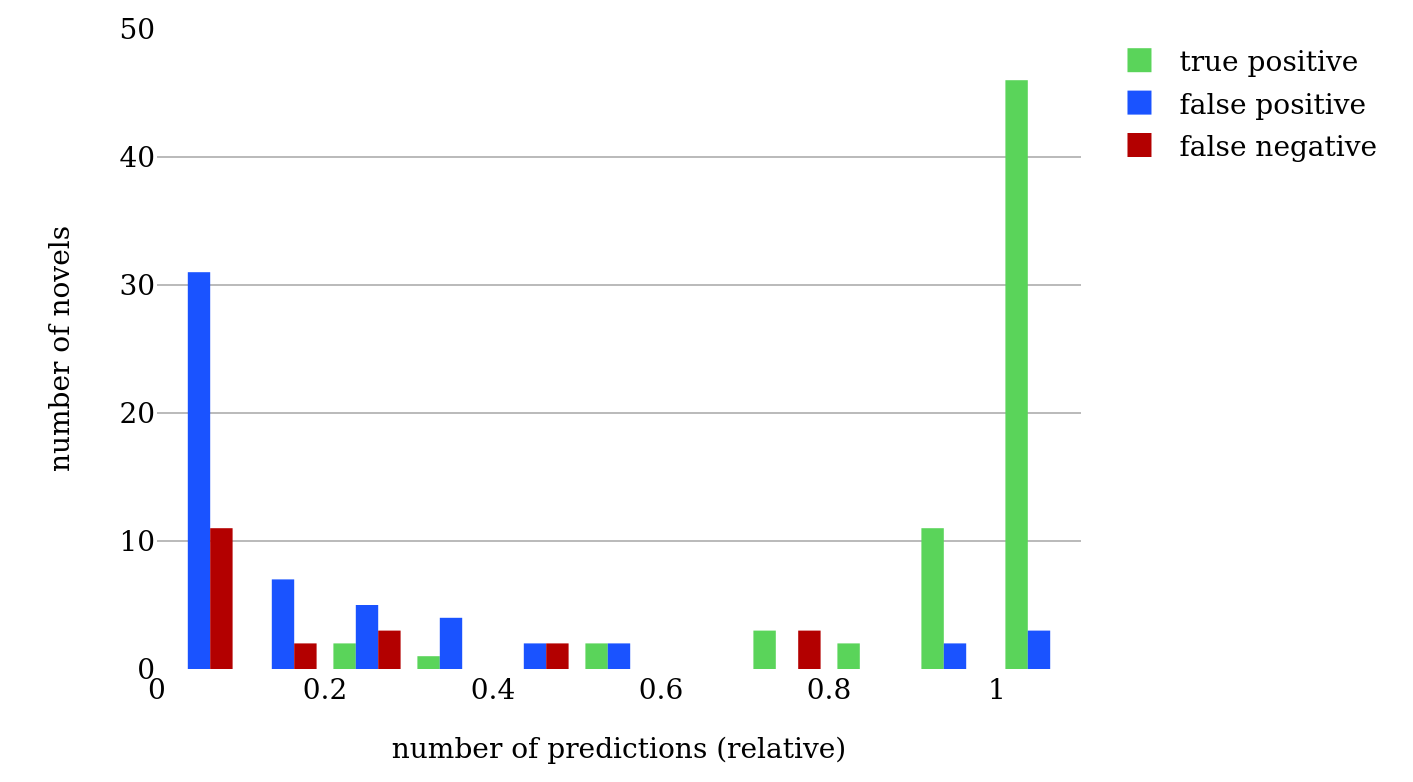
698Of special interest are the bars on the right side because
they mean that the novels covered by them were classified correctly or
wrong in many cases. In the histogram, the bars are grouped in steps of
10 %, starting with 0–9 % and ending with 90–99 %, and then 100 %. So the
rightmost group of bars stands for the novels that were classified
correctly or wrong in 100 % of the cases. If the novels were classified
correctly, they can be interpreted as prototypical instances of the
subgenre. If not, there is a discrepancy between the conventional and the
textual genre for these novels. Of course, if a novel was only classified
once and then correctly, it would appear as prototypical. That
characterization would be less sure than for a novel that was classified
100 times and each time correctly, so these details have to be taken into
account when this kind of chart is interpreted. For the constellation
novela histórica versus other novels, 252 of the 256
novels in the corpus were classified at least once, among them all the 67
historical novels. Of these, 46 (69 %) were classified correctly in all
100 classification runs and can thus be considered the prototypical core
of the text type novela histórica. Among them are, for
example, the romantic historical novel “La cruz y la espada” (1866, MX)
by Eligio Ancona and the realist historical novel “Puebla” (1903, MX) by
Victoriano Salado Álvarez, which both carry the explicit historical
subgenre label “novela histórica” and for which there is also agreement
among literary historians to classify them as historical novels. As an
example of such prototypical historical novels, the probabilities of the
topics that are most distinctive for historical versus other novels are
visualized for the novel “La cruz y la espada” in figure 60.589
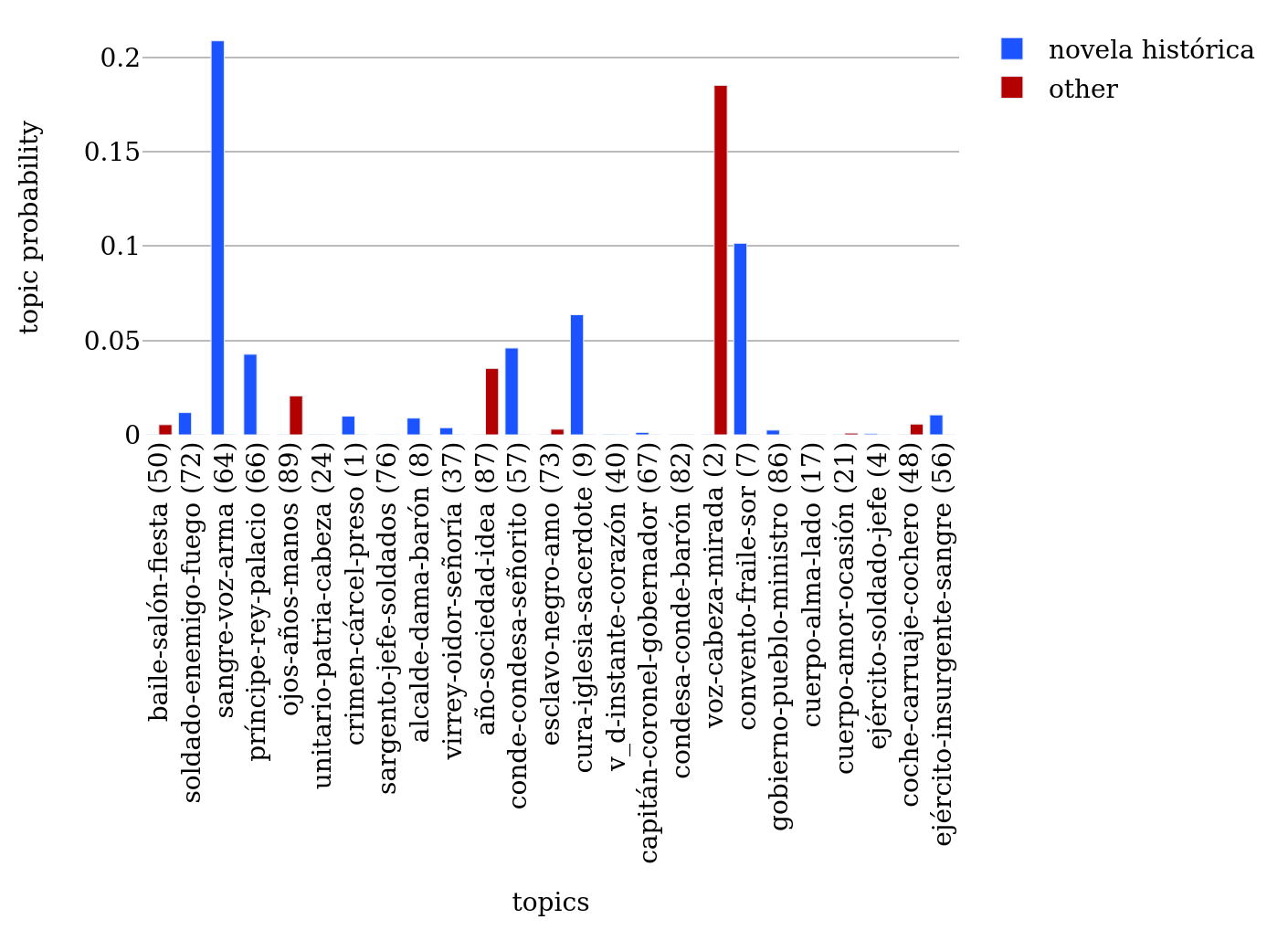
699In the plot, the topics are ordered by the weight that they have for the distinction of historical and sentimental novels in general, so that “baile-salón-fiesta” is the topic with the most weight and “ejército-insurgente-sangre” with the least. The colors indicate for which subgenre the topics are typical. The plot for “La cruz y la espada” shows that several topics that are distinctive for historical novels also have higher probabilities in this novel. For example, this is the case for “sangre-voz-arma”, “príncipe-rey-palacio”, “conde-condesa-señorito”, “cura-iglesia-sacerdote”, and “convento-fraile-sor”. Especially the last four topics characterize this novel as one that is set in a more remote past (it is about the Spanish conquest of Mexico) because they refer to monarchy, nobility, and church. So the novel is a specific subtype of the historical novel, but still always classified correctly. On the one side, it has a high probability for the topic “sangre-voz-arma”, which is a general topic for historical novels, but there are also top topics of historical novels which are not so important in “La cruz y la espada”, as, for example, “soldado-enemigo-fuego”, “virrey-oidor-señorita”, “capitán-coronel-gobernador”, or “gobierno-pueblo-ministro”. The first one of these is a general topic about battles. The second would be typical for a novel that is set in the colonial era because it mentions the viceroy and “oidor”, which was a judge in the colonial judicial system. The last two would be typical for a novel that treats contemporary history. This shows that the top topics of historical novels, in general, combine elements of different subtypes of the subgenre. As the case of “La cruz y la espada” shows, it is not necessary for each individual novel to have high values for all of these topics in order to be always classified correctly as a historical novel. This means that not only the idea of prototypically organized categories is present in the statistical classes that are determined in the machine learning process, but also the idea of family resemblance: The novels can have high probabilities of specific subsets of the most distinctive topics, but they do not all need to have the same distributional profile. However, the aspect of family resemblance that is covered by the statistical classification is also limited because the boundaries between classes are still strictly drawn, and there are no loose networks of novels with overlapping similarities. What can be done is to interpret the novels inside of a class as members of a family that share different characteristics, or to analyze novels at the edges between two classes, that is, novels that are often misclassified for each class, to see to what extent they share properties.
700In the case of “La cruz y la espada”, not only the topics that are distinctive for historical novels are of interest, but also the ones that are typical for other types of novels because this novel also has high probabilities for some of these topics. For example, a top topic that has much weight in the novel is “voz-cabeza-mirada”, and also “año-sociedad-idea” and “ojos-años-manos” have higher weights. However, in sum, these topics are less dominant than the ones that are typical for the historical novel. What this shows is that elements that are typical for other subgenres can be present and have a certain weight, but as long as they are not dominating, the novel is still classified correctly. So the class of a novel is really determined in quantitative terms: which topics “win” in terms of numbers? This also means that a prototypical historical novel can have elements of other subgenres, as well. This aspect is particularly useful in the case of the nineteenth-century Spanish-American historical novels, of which many were romantic and included a sentimental plot or were more realistic and contained passages with descriptions of customs. In this view, instances of prototypes are not necessarily pure but have certain feature values and distributions that are quantitatively dominating and can be interpreted as salient.
701Returning to the group of prototypical historical novels that were always classified correctly, there are also novels that have been discussed not only as historical novels but also in other terms by literary historians. For example, the novel “Amalia” (1855, AR) by José Mármol has been described as a political novel, a historical novel, and also a sentimental novel, but is here always classified as a historical novel. Regarding the historical genre conventions, an interesting aspect of this novel is that the main title, “Amalia”, is typical for sentimental novels because it refers to a female first name, but the novel also has the subtitle “novela histórica” in most editions that are published from 1874 onwards. It was therefore labeled with the primary thematic label “novela histórica” here. The results of the SVM classifier make clear that the sentimental plot elements do not prevent this novel from being classified as a historical one. The four novels of the series “Dramas militares”, which were published between 1884 and 1886 by Eduardo Gutiérrez and in which the protagonist is an Argentine gaucho, are also always classified as historical novels.
702There are three novels that resulted as false positives in every case and two novels for which this happened in more than 90 % of their classifications so that they can be interpreted as belonging to the text type of the historical novel, although they did not have the primary thematic label “novela histórica”. One of them is “Las gentes que son así (Perfiles de hoy)” (1872, MX) by José Tomás de Cuéllar, which is a novel of customs that is part of the series “La linterna mágica”. It was classified as a historical novel 60 times out of 60. Another one, which was classified 39 times as a historical novel and one time as “other”, is “Los bandidos de Río Frío. Novela naturalista, humorística, de costumbres, de crímenes y de horrores” (1892, MX) by Manuel Payno, which has been assigned the primary thematic label “novela de costumbres” in the corpus. Already the subtitle shows that it refers to several genre conventions at once. It is about banditry and has also been classified as a novel of customs by Brushwood:
Manuel Payno, for example, published another serial novel Los bandidos de Río Frío, from 1889 to 1891. The subtitle even states that it is ‘naturalistic’, but it has much Romantic overstatement that identifies it with an earlier time. Taking the theme of banditry that had by that time become very popular, Payno wrote another essentially costumbrista novel. (Brushwood 1966, 116Brushwood, John S. 1966. Mexico in its Novel. A Nation’s Search for Identity. Austin: University of Texas Press.)590
703In these two example cases, it is not entirely clear why
they are repeatedly classified as historical novels, so the top topic
profiles of them are checked to see if they explain these results (see
figures 61 and 62).
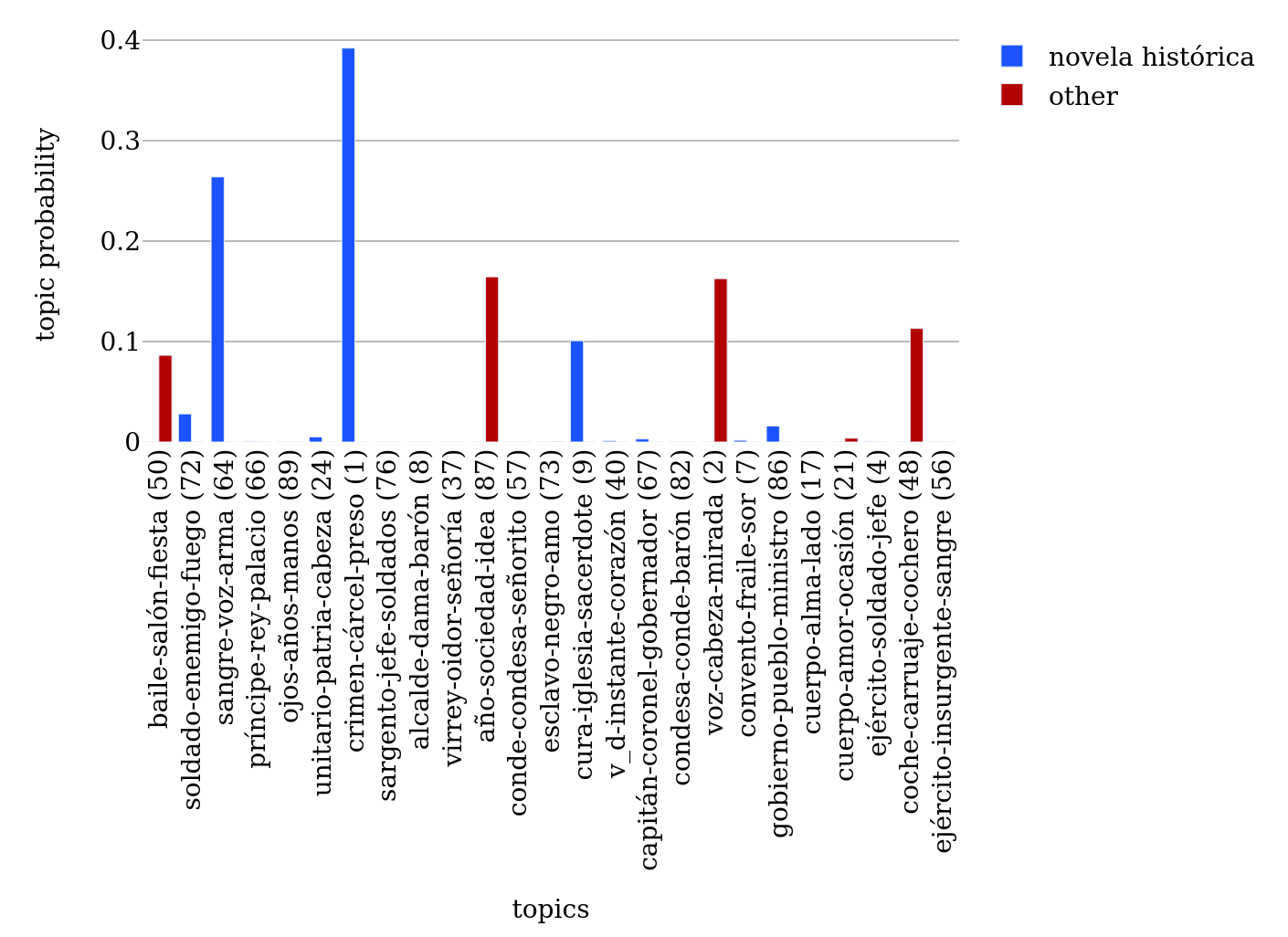
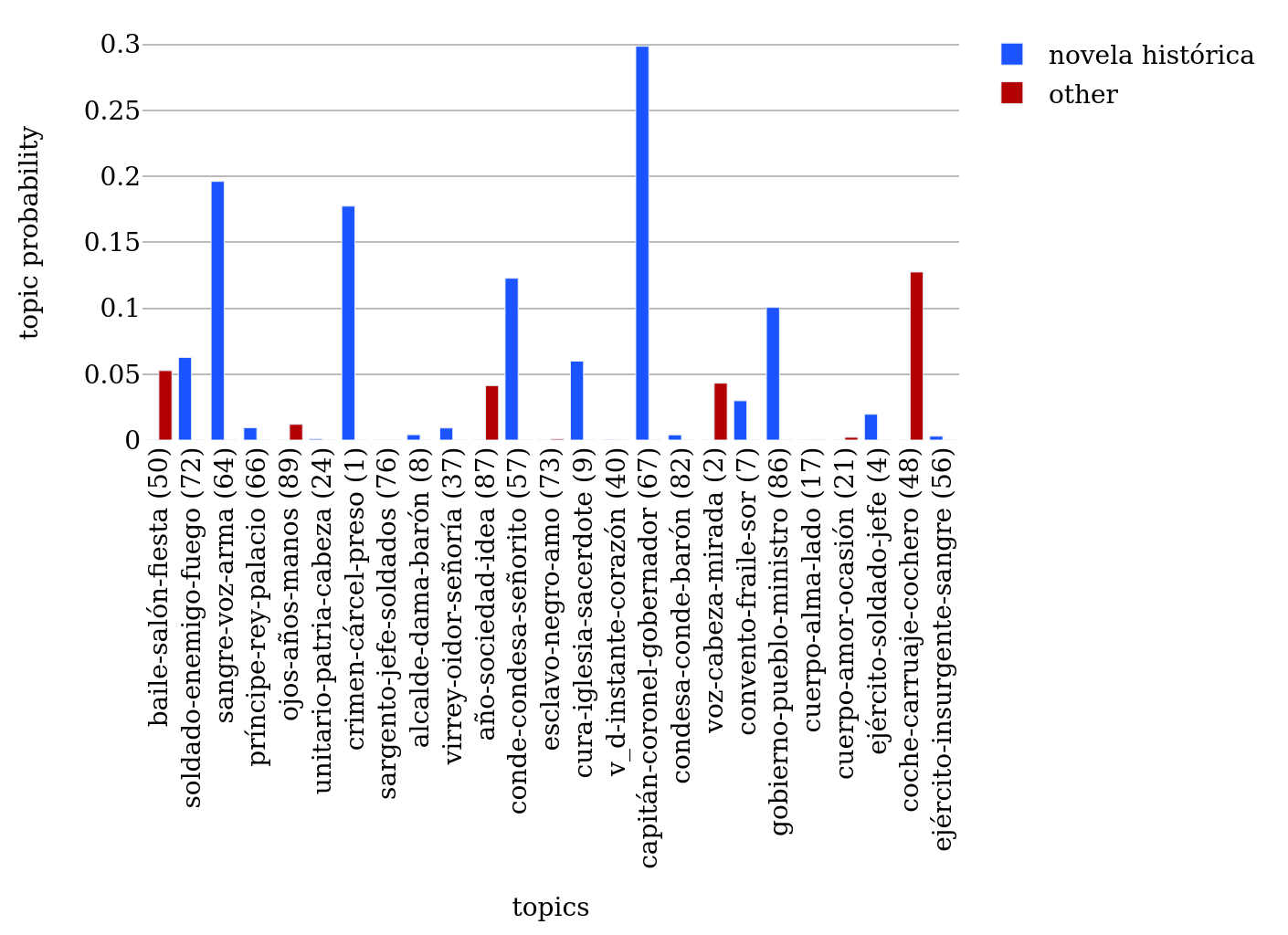
704As to the novel “Las gentes que son así”, a look into the probabilities that it has for the topics that are most distinctive for historical novels reveals that especially the topics “crimen-cárcel-preso” and “sangre-voz-arma” have high values. The first one is about crime, justice, and imprisonment, and the second one is a general topic about fights. These topics are not exclusively historical but can as well occur in novels of other subgenres. However, because they are typical for historical novels, the novel of customs “Las gentes que son así” in which they are so important, is mistaken as a historical novel, even if it does not have high probabilities for topics that are more specific for historical novels, such as “soldado-enemigo-fuego” or “sargente-jefe-soldados”. What this demonstrates is that the classifier has no idea about the conventional genres and does not make a difference between necessary, typical, or sufficient features. It just compares the topic values and distributions, and if it finds that they are similar to the ones typically found in a certain subgenre, the novel is classified as such. The example of “Las gentes que son así” is one where the novel has textual similarities to historical novels and is recognized as part of the corresponding text type, but it should not be treated as part of the textual genre, because by convention and also in terms of necessary features it is no historical novel.
705The second case, “Los bandidos de Río Frío”, has another quality. The probabilities for the top topics that are typical for historical novels show that some of them also have high values in this novel, above all “capitán-coronel-gobernador”, “sangre-voz-arma”, “crimen-cárcel-preso”, “conde-condesa-señorito”, and “gobierno-pueblo-ministro”. They are more than in the novel “Las gentes que son así”, and even though the general fight and crime topics appear again, there are also topics concerned with the military, politics, and nobility. The novel “Los bandidos de Río Frío” was published in 1892 but is set in the 1830s. The male protagonist has a military position, and also social and political problems of banditry, insecurity, and corruption are treated in the novel. That the occupation of the protagonist has an influence on the topics of the novel and that this, in turn, affects how the novel is classified in terms of subgenre again makes clear that a machine learning classifier cannot distinguish between different reasons for which topics are present in the texts. However, the combination of themes which are treated in “Los bandidos de Río Frío”, together with the fact that it treats a period that is several decades away from its publication time, does not make it far-fetched to compare it to other novels of contemporary history, so here, the result is not considered so misleading as in for “Las gentes que son así”.
706The three other novels that frequently resulted as false positives are “Misterios del corazón” (1875/1897, AR) by Rafael Barreda, “La hija de Tutul Xiu. Novela yucateca” (1884, MX) by Eulogio Palma y Palma, and “La Chapanay” (1884, AR) by Pedro Echagüe. The first one was classified as a historical novel 50 out of 50 times, the second one 30 out of 30 times, and the third one 28 times as a historical novel and 2 times as “other”. Barreda’s novel has the primary label “novela sentimental” and the secondary thematic label “novela histórica” because it is set in the Rosas’ era. Therefore, it is not surprising that it is mistaken as a historical novel, but what is surprising is that this happens every time. It seems that, in this case, the setting has a bigger influence on the text type than the intended primary theme of the novel. Or, from another perspective, aspects of the sentimental novel are not untypical for nineteenth-century Spanish-American historical novels and are part of the historical novel’s text type. The case of “La hija de Tutul Xiu. Novela yucateca” can also be easily explained because it is an indianist novel set in the pre-Spanish period, and it also has the secondary thematic label “novela histórica” in the corpus. So here, the problem was that only the more specific thematic label was considered in the classification and not the more general secondary one. As to “La Chapanay”, it has the primary thematic label “novela de costumbres”. This novel is an account of the life of Martina Chapanay, a historical Argentine personality of the nineteenth century which is only of regional importance. Lichtblau summarizes the novel’s contents as follows: “Regional types, customs, and the daily life of the San Juaneses are vividly portrayed in the novel as we see Martina first as a rebellious young girl, then as a member of a band of highwaymen, and finally as a contrite woman aiding the forces of law and order” (Lichtblau 1997, 299Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.). This description identifies it as a novel of customs, but “La Chapanay” also contains passages in which the narrator expresses his political opinion and criticizes the Rosas regime (Lichtblau 1997, 299Lichtblau, Myron. 1997. The Argentine novel: an annotated bibliography. Lanham, Maryland: Scarecrow.). So similarly to “Misterios del corazón”, where it was the historical background that approximated the novel stylistically to other conventional historical novels, here there are argumentative passages that influence the text style in terms of topics. In addition, this is another case of a hybrid between the novel of customs and the historical novel.
707As to the novels that were labeled as historical novels but
often classified as other types (the false negatives), there is none that
was misclassified in every run. There are three significant cases,
though. The first one is “Los esposos” (1893, AR) by Lola Larrosa de
Ansaldo, which was classified as “other” 77 times and as a historical
novel 23 times. In the corpus, the novel has the primary thematic label
“novela histórica” because it had this subtitle in the first edition. The
second edition, in contrast, does not have that subtitle anymore.
Moreover, Lichtblau describes the novel as follows: “A cloyingly romantic
novel, Los esposos interweaves several plots that demonstrate the
author’s self-righteous morality and her traditional beliefs about
women’s place in the home” (Lichtblau 1997, 530Lichtblau, Myron. 1997. The Argentine novel: an
annotated bibliography. Lanham, Maryland: Scarecrow.). Finally, it also has the main title “Los
esposos”, which seems rather typical for a sentimental novel. In the
corpus, it has therefore been assigned a secondary subgenre label:
“novela sentimental”. As it seems, the explicit historical label that
this novel carries is not entirely detached from the textual material and
fits in 23 % of the cases, but the novel is textually closer to another
subgenre, most probably the sentimental novel. A look into the weight
that the top distinctive topics for novela histórica versus
“other” have in this novel confirms that it does not correspond to the
historical novels textually (see figure 63). The topic with the highest value is
“voz-cabeza-mirada”, which is indeed one of the top topics for
sentimental novels when compared to others, but the other two topics,
“año-sociedad-idea” and “cuerpo-amor-ocasión”, are neither distinctive
for historical nor for sentimental novels, and also not for the novels of
customs,591 but for other subgenres. As the novel was published in
1893, it is possible that it includes elements that are typical for the
realist or naturalist novel. The topic “año-sociedad-idea” points in the
first direction and “cuerpo-amor-ocasión” in the second one.
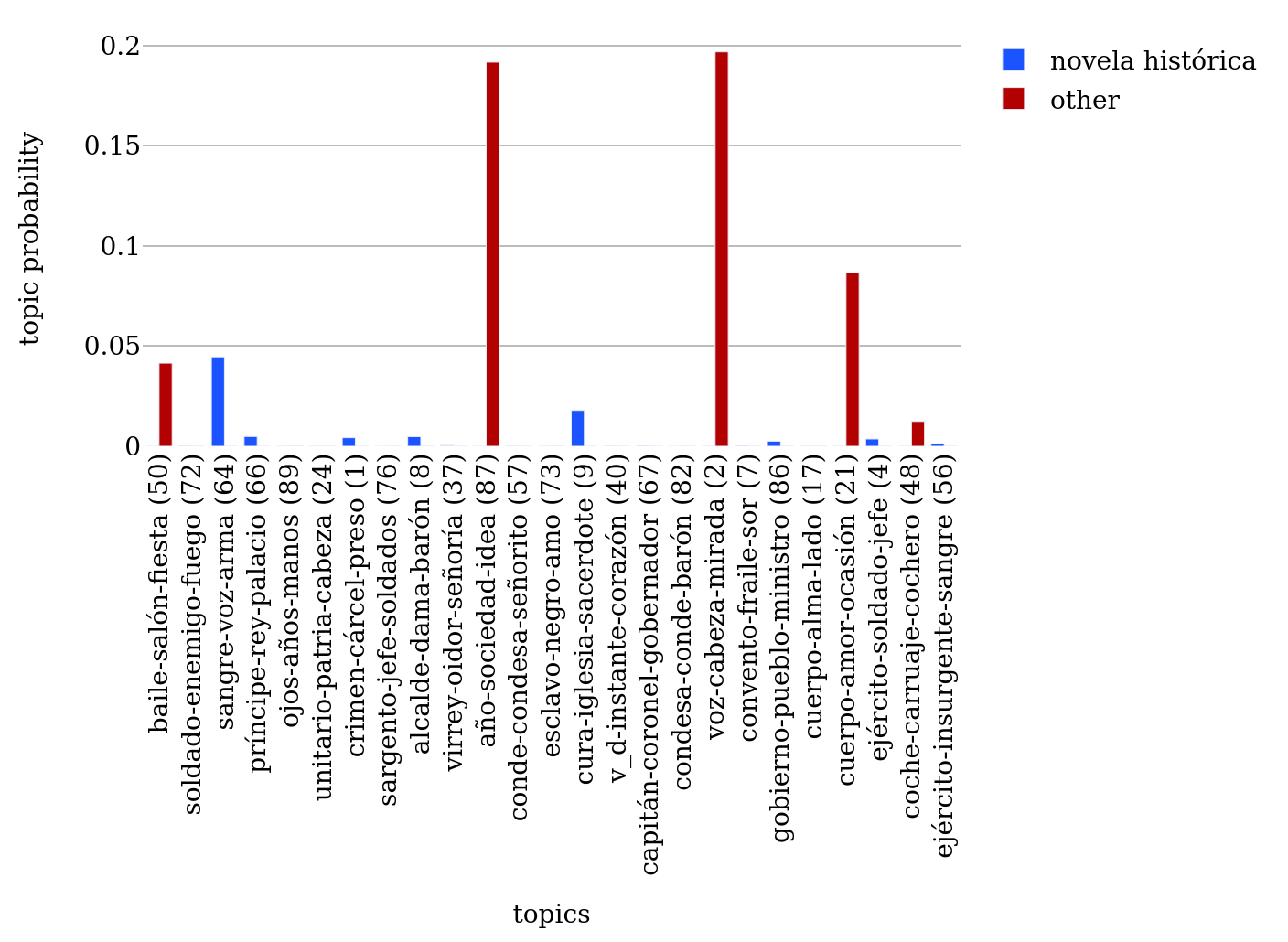
708The second false negative is “Vía Crucis” (CU) by Emilio
Bacardí Moreau, of which the first part, “Páginas de ayer”, published in
1910, is included in the corpus. It was classified as “other” 73 times
and as a historical novel 27 times. This novel is an account of the Cuban
struggle for independence in the second half of the nineteenth century,
which means that it treats contemporary historical events. It has
nonetheless been characterized as a historical novel by several literary
historians, for example, by Remos y Rubio, who compares Bacardí’s style
to the one of Pérez Galdós, a Spanish writer who published the famous
series of historical novels entitled “Episodios Nacionales”. He also
relates Bacardí Moreau’s style to the ones of Alexandre Dumas and Walter
Scott (Remos y Rubio
1935, 42–43Remos y Rubio, Juan J. 1935. Tendencias de la
narración imaginativa en Cuba. La Habana: Casa Montalvo-Cárdenas. https://dloc.com/UF00078289/00001/images.).592 However, Remos y Rubio also
remarks that the novel “Vía Crucis” contains accomplished
costumbrista passages: “Por el alto valor costumbrista
que hay en ella, por lo admirable de las descripciones locales, como
cafetales, campiñas, amenas, hogares criollos, etc., ha sido estimada
Vía Crucis por algunos críticos, superior a Cecilia
Valdés” (Remos
y Rubio 1935, 44Remos y Rubio, Juan J. 1935. Tendencias de la
narración imaginativa en Cuba. La Habana: Casa Montalvo-Cárdenas. https://dloc.com/UF00078289/00001/images.). The similarity with other novels of customs,
especially the Cuban ones that also contain descriptions of coffee
plantations, might be an aspect that leads to the frequent
misclassifications in the case of “Vía Crucis”. Its top topic profile is
visualized in figure 64. It
becomes visible that this novel has high weights for topics that are
typical for the sentimental novel (“voz-cabeza-mirada”,
“baile-salón-fiesta”, and “ojos-años-manos”) and indeed a topic about
slavery (“esclavo-negro-amo”), but none of the topics that are
distinctive for novels of customs versus other novels are strong in this
novel. Instead, the two topics “año-sociedad-idea” and
“cuerpo-amor-ocasión” are important, which are the same ones as in “Los
esposos”. As “Vía Crucis” was published in 1910, it is a novel that is
clearly not a romantic historical novel and also Remos y Rubio remarks on
the new kind of historical novel that develops in the early twentieth
century and of which “Vía Crucis” is an example: “La novela histórica se
oscurece con el advenimiento de las nuevas tendencias, hasta que a partir
de 1910 la reaniman con nuevos bríos y moderna fisonomía, el selecto
Rodríguez Embil y el ameno narrador santiaguero, EMILIO BACARDI MOREAU”
(Remos y Rubio 1935,
42Remos y Rubio, Juan J. 1935. Tendencias de la
narración imaginativa en Cuba. La Habana: Casa Montalvo-Cárdenas. https://dloc.com/UF00078289/00001/images.). So the misclassifications of “Los esposos” and “Vía Crucis”
can also be interpreted as signs of a new type of historical novel
related to Realism, Naturalism, and Modernism, which is less frequent in
general and in the corpus than the romantic type of historical novel and
is therefore not recognized well, because it is not learned as part of
the model of the quantitatively dominant historical novel. These results
underline how important the construction of the corpus is for the digital
text analysis, and the attention to balance subparts of it. However, if a
certain type of novel simply was not frequent enough to be balanced
against another type (as the modernist historical novel, for instance,
against the romantic historical novel), then qualitative analysis or an
approach that is different from statistical classification is more
meaningful to describe its characteristics.
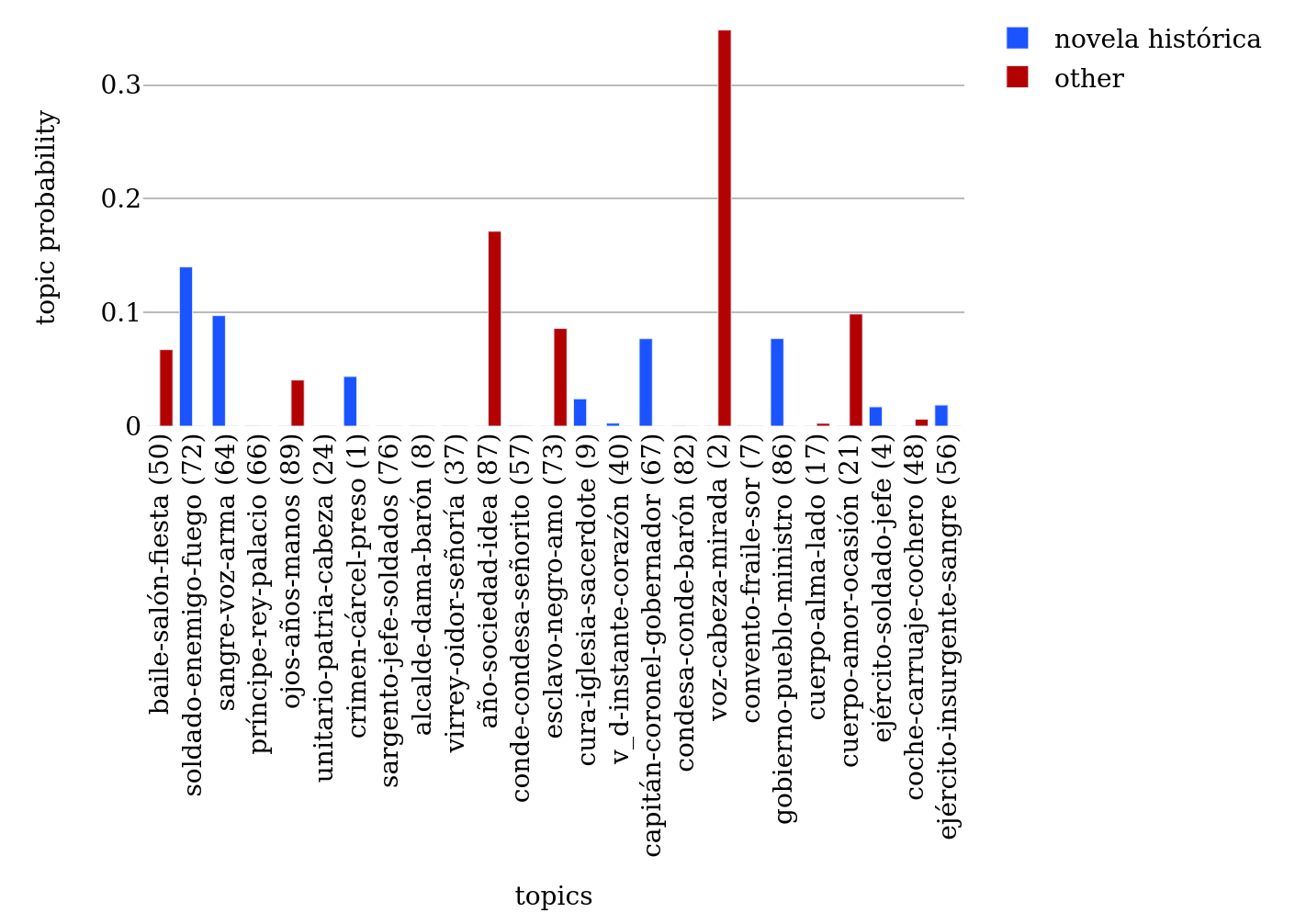
709The third novel that carries the label “novela histórica”
but is often misclassified is the novel “Las ranas pidiendo rey.
Confesiones de una afrancesada (1861–1862)” (1903, MX) y Victoriano
Salado Álvarez. It is part of the series of historical novels “Episodios
Nacionales Mexicanos”. The novel was classified as historical 30 times
and as “other” 70 times. Like “Vía Crucis”, this novel treats events of
the recent past. Furthermore, it is written in the form of a diary and
thus in the first person, which is quite unusual for a historical novel.
Here it is assumed that especially the latter aspect turns it into a
novel that is stylistically closer to other subgenres than the historical
novel, but the narrative perspective does not need to have much influence
on the topics. The plot for the novels’ top topic probabilities is given
in figure 65 to check that.
What it shows is that the most important topic which is not distinctive
for historical novels is “año-sociedad-idea”, followed by
“baile-salón-fiesta”. The second one is typical for sentimental novels,
and it might have more weight here because of the personal account that
is given of the events, but not necessarily. It can also be an element
that is inherited from romantic historical novels with a sentimental
plot. The other topic about intellectual work and society is the same
that had much weight in “Los esposos” and “Vía Crucis”. Now, “Las ranas
pidiendo rey” was published in 1903, and the historical novels of
Victoriano Salado Álvarez are commonly attributed to the realist current.
So this is yet another example of a later type of historical novel that
challenges the classifier.
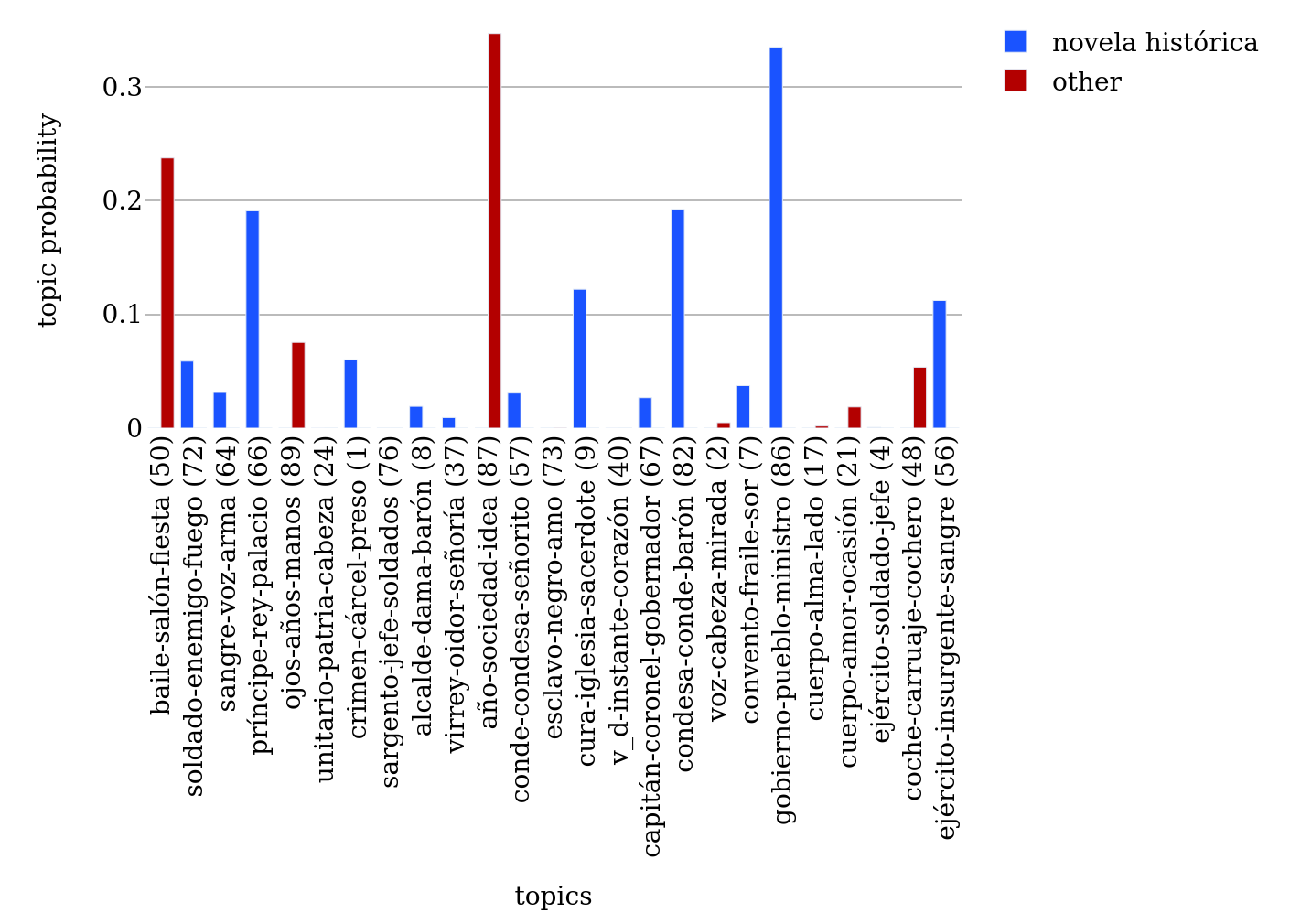
710The findings for the textual coherence of the historical
novel can be summarized as follows: The majority of novels are
prototypical historical novels and are both part of the conventional and
the textual genre. There are only a few novels that are consistently
misclassified or classified wrongly in more than 70 % of the cases. Five
novels are regular false positives and interpreted as members of the text
type but were, for different reasons, not labeled as members of the
conventional genre. Three novels are persistently false negatives or
members of the conventional genre but not of the text type, for
individual reasons but also because they were published in the late
nineteenth or early twentieth century. In all of these cases, the results
can be explained by comparing and relating the textual and the
conventional generic levels to each other, so their misclassifications
are not considered real errors, except in the case of “Las gentes que son
así”. Howver, also in that case, the decision of the classifier can be
explained. Besides, there are groups of novels that are only sometimes
misclassified. For instance, 13 of the “novelas históricas” are
classified as other types only in up to 20 % of the cases. They are still
considered members of the text type but less prototypical ones. On the
other hand, there are 38 novels of other subgenres that are classified as
historical novels in up to 20 % of the cases. These are members of other
text types that have similarities with the historical text type and that
are stylistically located at the edge of the historical prototype
category. For the sentimental novels and the novels of customs, no
individual cases are discussed, but their generic profiles
are evaluated on a general level. The histograms for the constellations
novela sentimental versus “other” and novela de
costumbres versus “other” are given in figures 66 and 67.
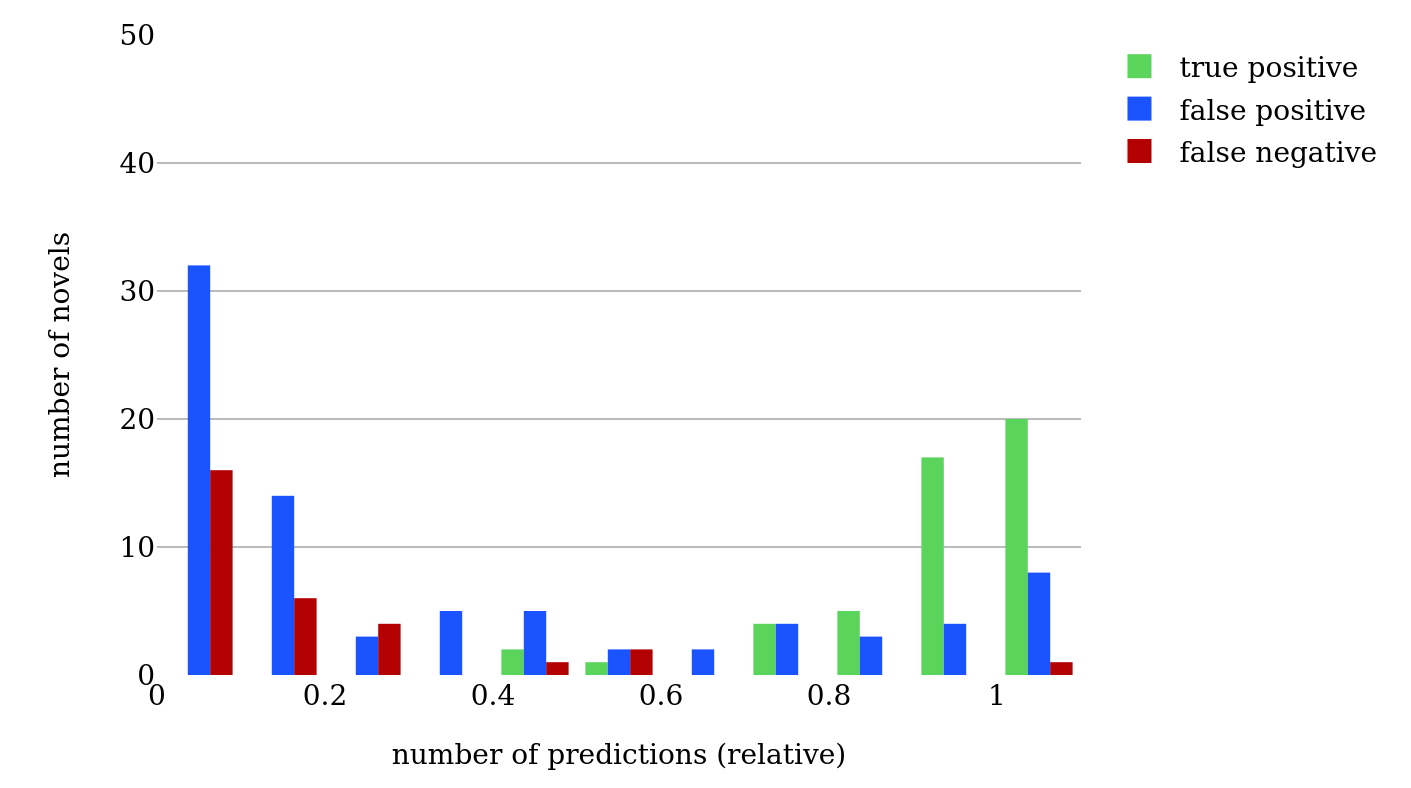
711All of the 55 sentimental novels in the corpus were included in the classifications for the constellation novela sentimental versus “other”. In total, 243 of the 256 novels were part of this contrast at least once. Like the historical novel, also the sentimental novel has a strong prototypical core, but it is smaller than in the case of the historical novel. Of the sentimental novels, 33 (60 %) were classified correctly in 100 of 100 cases, compared to 67 % of the historical novels. For the sentimental novel, there are twelve instances that are regular false positives (seven with 100 %, four with 90 or more, and one with 80 %) and three instances that are very frequent false negatives (one of 100 % and the other two with 97 and 89 %). So the number of novels that were not labeled as sentimental novels but are recognized as such on the textual level is higher than for the historical novels, while the number of novels that carry the label but are not textually congruent with the subgenre is the same. Otherwise, the distribution is similar to the one of the historical novel. Less prototypical are 15 novels that have the label but are not recognized as sentimental novels in up to 10 % of the classifications. At the edge of the category are 34 novels that are classified as sentimental novels in up to 20 % of the cases but were not labeled as such.
712The novel of customs has 50 instances in the corpus, all of which were included in the classifications of novela de costumbres versus “other”. 241 novels out of the 256 in the whole corpus participated in these classifications. The histogram for the novel of customs looks a bit different than the ones for the historical and the sentimental novel. The group of novels that are always or almost always classified correctly is smaller, and there are more false positives which are relatively frequent. The amount of frequent false negatives, in contrast, is not especially high. This means that the prototypical core of this textual genre is smaller: 20 novels (40 %) are classified correctly in 100 of 100 cases. In addition, more novels that are not labeled as novels of customs still belong to the text type (according to these results): 19 novels are classified as novelas de costumbres in 70 % of the cases or more. On the other hand, there is only one novel which is labeled as novel of customs and always classified as “other”: the Cuban anti-slavery novel “El negro Francisco” (1873, CU) by Antonio Zambrana y Vázquez. An interpretation of these results is that the description of customs is a textual element in many of the nineteenth-century Spanish-American novels. However, it is not always marked on the level of historical genre convention and also not always considered as the primary thematic element by literary historians even if it dominates a text quantitatively. As was seen before, there are many different topics that are typical for the novels of customs, which might contribute to this lesser degree of overlap between the larger text type and the smaller conventional genre. The results for all three thematic subgenres demonstrate that the primary thematic labels that the novels have are not totally disconnected from the stylistic characteristics of the texts; quite the contrary. Nevertheless, there are also novels in which the conventional subgenre identity does not correspond to the textual one, either completely, as in the extreme cases, or in part. All constellations are possible on the way from a prototypical core to the edge of a textual genre, but some are more frequent than others, depending on the kind of subgenre that is analyzed.593
713In what follows, the classification results for the MFW-based features are presented. These features consist of three main groups: words, word n-grams, and character n-grams. The results for each group are reported separately. In total, 18,000 classification runs were considered for basic MFW, 54,000 for word n-grams, and 162,000 for character n-grams.594 The results for the MFW-based features are summarized in table 38.595
| Classifier | Feature type | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| KNN | MFW | 1.0 | 0.68 | 0.15 | 1.0 | 0.68 | 0.18 |
| MFW word n-grams | 1.0 | 0.64 | 0.14 | 1.0 | 0.64 | 0.17 | |
| MFW character n-grams | 1.0 | 0.68 | 0.15 | 1.0 | 0.69 | 0.17 | |
| all | 1.0 | 0.67 | 0.15 | 1.0 | 0.67 | 0.17 | |
| SVM | MFW | 1.0 | 0.77 | 0.15 | 1.0 | 0.77 | 0.16 |
| MFW word n-grams | 1.0 | 0.75 | 0.16 | 1.0 | 0.74 | 0.17 | |
| MFW character n-grams | 1.0 | 0.76 | 0.15 | 1.0 | 0.76 | 0.16 | |
| all | 1.0 | 0.76 | 0.15 | 1.0 | 0.76 | 0.17 | |
| RF | MFW | 1.0 | 0.78 | 0.14 | 1.0 | 0.77 | 0.15 |
| MFW word n-grams | 1.0 | 0.74 | 0.15 | 1.0 | 0.73 | 0.16 | |
| MFW character n-grams | 1.0 | 0.76 | 0.15 | 1.0 | 0.76 | 0.15 | |
| all | 1.0 | 0.76 | 0.15 | 1.0 | 0.75 | 0.16 |
714With the KNN classifier, a mean accuracy of 0.68 is reached
with MFW features and also with character n-gram features. The mean
accuracy for word n-grams is only 0.64. With SVM, MFW yield the best mean
accuracy value of 0.77, character n-grams 0.76, and the word n-grams
0.75, so here, the results for the three subtypes of MFW-based features
are very close. The RF works best with MFW features, which lead to a mean
accuracy of 0.78, followed by character n-grams with 0.76 and word
n-grams with 0.74. So MFW are the best token unit across all classifiers,
and character n-grams work equally well for KNN, but word n-grams work
less well for all three classifiers. SVM and RF are almost equally
successful and have the same average accuracies across the different
types of feature sets (MFW, word n-grams, and character n-grams). Because
RF is slightly better for the basic MFW, it is chosen here for evaluating
the classification results for primary thematic subgenres with MFW-based
features further. Figure
68 displays the classification results for different numbers of MFW
and tf-idf versus z-scores.596
715It is directly visible that the lower numbers of MFW are
not suited for classification by thematic subgenre. On the other hand,
the results stay at a high level, approximately from the 1,000 MFW
onwards. As was shown in the chapter on the MFW-based features, in the
range of 1,000 MFW, there are already verbs, adjectives, adverbs, and
nouns, so it can be concluded that these content words are essential for
the classification by thematic subgenre.597 As to the difference between tf-idf and
z-scores, the former are better up to 3,000 MFW and the latter from 4,000
MFW onwards. When one rounds to two decimal places, the top mean
accuracies of 0.81 are reached with tf-idf and 3,000 or 2,000 MFW.598
Because of the above results, tf-idf and 3,000 MFW are chosen to analyze
the classification results further. Next, word n-gram features are
examined. The classification results relying on these feature sets are
summarized in figure 69.
716In general, word 2-grams give higher mean accuracies than 3-grams or 4-grams, which was expected because the more words are involved, the less frequent the combinations are in the corpus and potentially less helpful to classify texts by genre if they only occur in a few texts. Here, too, the results are generally better from 1,000 MFW onwards than with fewer MFW, but they also drop again for the 2-grams and 4-grams, even if slowly. The differences between tf-idf values and z-scores are very small. The best mean accuracy is achieved with tf-idf, word 2-grams, and 2,000 MFW, which is at 0.79. If the values are rounded to two decimal points, the same result is achieved with 2-grams from 1,000 to 4,000 MFW with both tf-idf and z-scores, and also with 5,000 MFW and z-scores, so the differences between these different constellations are minimal.
717The third set of MFW-based feature sets that is examined
are the character n-grams. Here, different parameter constellations for
three n-gram subtypes are evaluated. The first subtype are the “classic”
character n-grams containing all characters, punctuation marks, and blank
spaces. The classification results for these are summarized in figure 70.599
718With character n-grams, the best mean accuracy is achieved
with the combination of tf-idf, 3-gram characters, and 4,000 MFW,
reaching 0.80. With values rounded to two decimal points, the same result
is achieved with tf-idf, 4-gram characters, and 5,000 MFW.600 Besides the classic n-gram features, also two special
types of n-grams were created. The first of them only uses mid-word and
multi-word n-grams and is called “word n-grams” and the second type only
uses prefix n-grams as well as n-grams ending with punctuation marks and
is called “affix-punct”.601 In the
following, it is checked if they have advantages over the classic
n-grams. Figure 71 visualizes
the results for the “word” character n-grams.
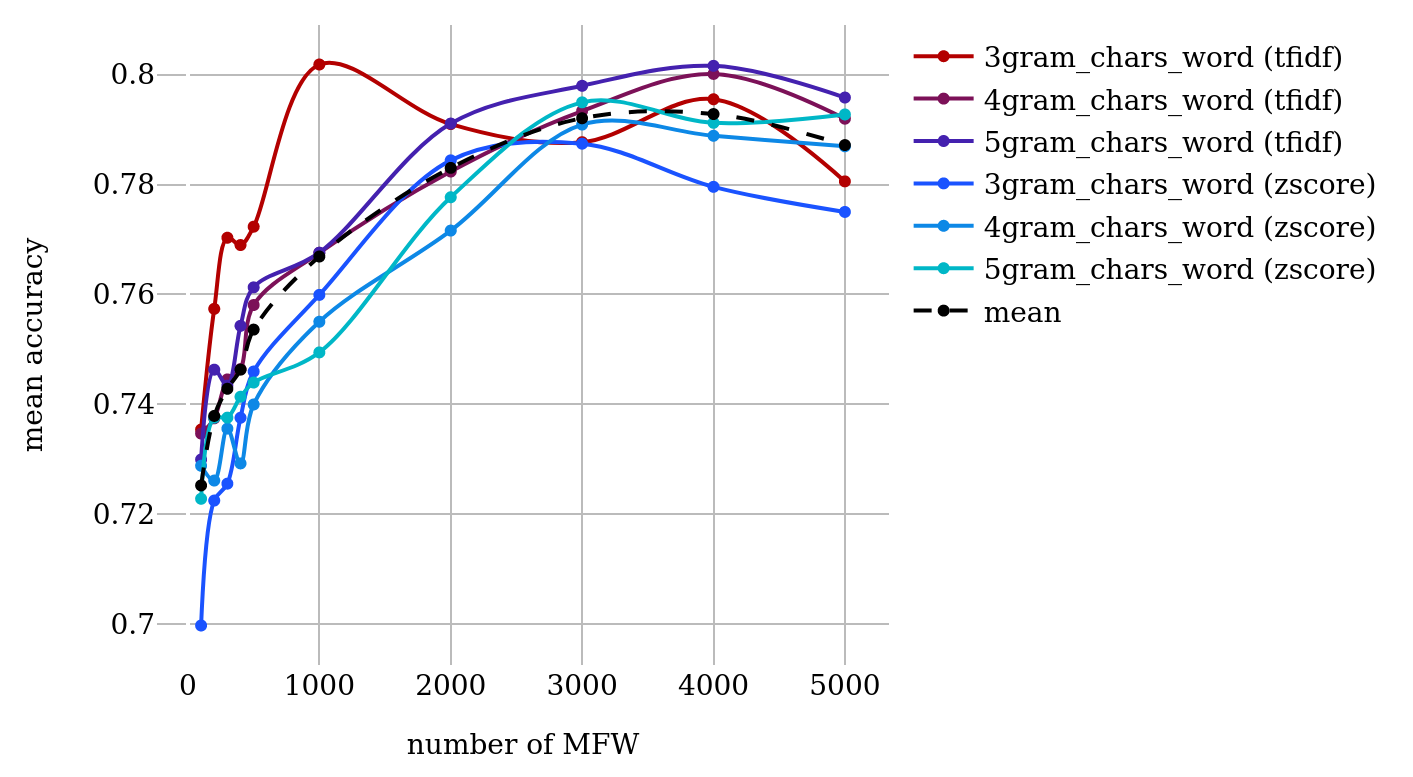
719With the “word” character n-grams, the best result is an
average accuracy of 0.80, which is reached with tf-idf, 3-grams, and
1,000 MFW and also with tf-idf, 4,000 MFW, and 4-grams or 5-grams, as
well as with tf-idf, 5-grams, and 3,000 MFW (rounded values). The top
mean accuracy is the same as for the classic n-gram features, so it was
no advantage to only use n-grams that are derived from words or word
boundaries. The classification results for the second special type of
n-gram features, the “affix-punct” character n-grams, are given in figure 72.
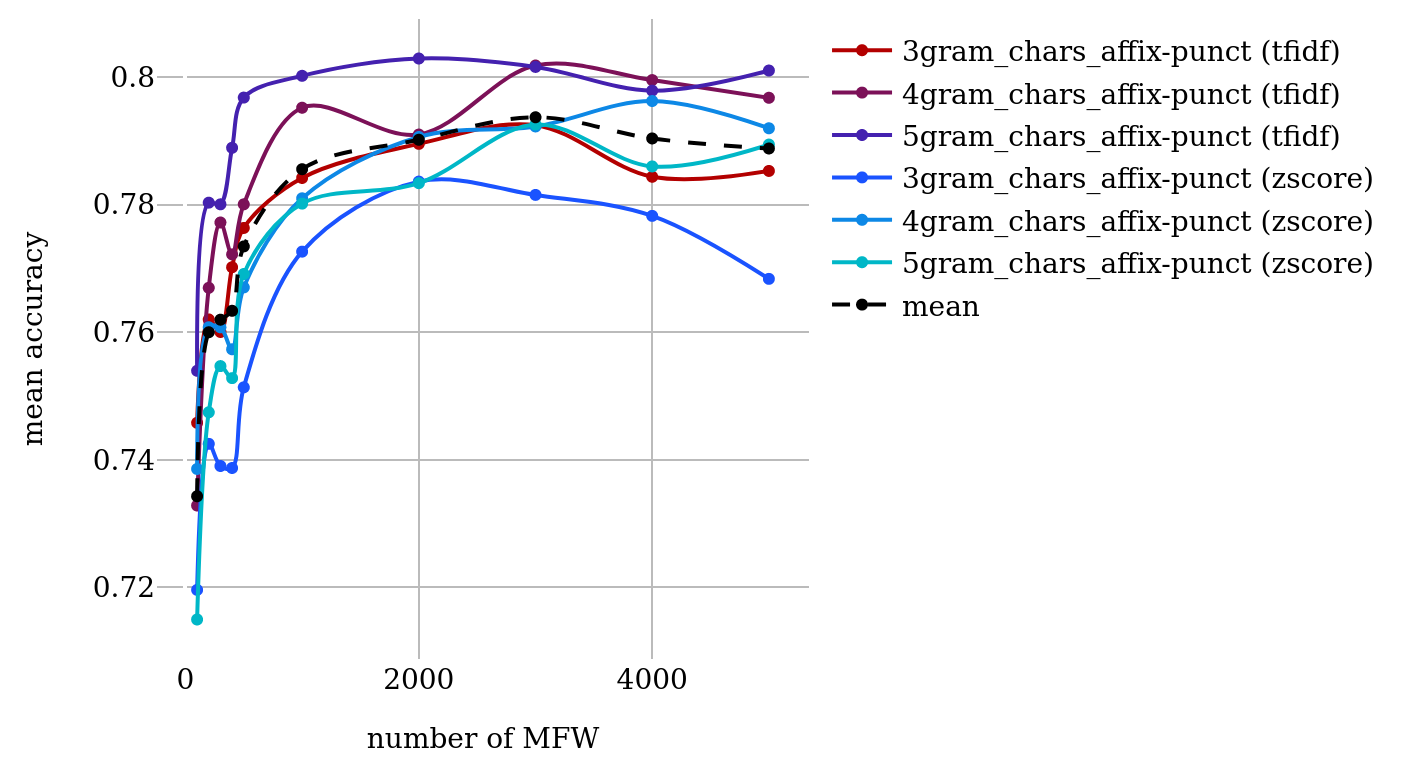
720In this group of feature sets, the highest mean accuracies of 0.80 are achieved with character 5-grams and tf-idf values for several numbers of MFW (1,000 to 5,000, with accuracies rounded to two decimal places). The 4-grams with tf-idf reach this value several times, too. Again, there is no difference in the mean accuracy compared to the other types of n-grams, so for the classification of the nineteenth-century Spanish America novels by thematic subgenres, it is not decisive which kind of n-gram features are used.
721When the findings for different token units are summarized, it can be observed that the top mean accuracies are all very similar, as they range from 0.79 in the case of word 2-grams over 0.80 for the character n-grams to 0.81 for normal MFW. All of these token units seem equally suited to classify the novels by thematic subgenres. As to the numbers of MFW, higher numbers of 1,000 or more tokens work better in all cases. Regarding the normalization techniques, tf-idf was, in general, the one that reached the top values, but the differences between the different maximum mean accuracies were small in many cases. Only the standard MFW features are chosen here to inspect the classification results for the different subgenre constellations, with 3,000 MFW and tf-idf. The results for this combination, using the RF classifier, are given in table 39 below.602
| Subgenre 1 | Subgenre 2 | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| novela histórica | other | 1 | 0.86 | 0.09 | 1 | 0.86 | 0.09 |
| novela sentimental | other | 1 | 0.78 | 0.14 | 1 | 0.78 | 0.16 |
| novela de costumbres | other | 1 | 0.69 | 0.15 | 1 | 0.71 | 0.15 |
| novela histórica | novela sentimental | 1 | 0.90 | 0.08 | 1 | 0.90 | 0.09 |
| novela histórica | novela de costumbres | 1 | 0.88 | 0.10 | 1 | 0.87 | 0.12 |
| novela sentimental | novela de costumbres | 1 | 0.74 | 0.12 | 1 | 0.72 | 0.15 |
722What is striking about the results for MFW is that the ranking of subgenre constellations is the same as for the topic features. The constellation that is easiest to distinguish is novela histórica versus novela sentimental, which reaches a mean accuracy of 0.90, the second best novela histórica versus novela de costumbres with 0.88, and the third best novela histórica versus “other” with 0.86. Again, the historical novel is the subgenre that can be separated best from the other thematic subgenres, followed by the sentimental novel. For the latter, a score of 0.78 is achieved if the subgenre is compared to all other novels and a score of 0.74 if it is contrasted with the novel of customs. As with the topics, also with MFW, the novelas de costumbres have the lowest mean accuracy of all constellations when they are classified against all other novels. In part, it is understandable that 3,000 MFW leads to similar results as topics because content words and, thereby, semantic features which can capture thematic elements or other semantic surface structures are also part of this feature set. Nevertheless, in the MFW set, not only nouns are included, but all kinds of word categories, and there is no layer of hidden semantic distributions that is analyzed, but the (normalized) word frequencies are directly used as features. So obtaining such similar classification results with different feature sets means that the results are meaningful regarding the characteristics of the different subgenres.
723Another noticeable aspect of all the results for the classification of thematic subgenres is that the standard deviations were not reduced considerably from the first average results based on all feature sets and parameter constellations to the individual subgenre constellations. They were about 0.15 in the first overviews and are still at about 0.10 in the direct comparison of subgenres with a certain feature set. This means that approximately two-thirds of the variation are to due to different selections of novels for the various classification runs, which shows how important it is to have a corpus and subcorpora for the different subgenres as large as possible and how important it is to prevent the classifiers from focusing too much on specific novels. Furthermore, it means that in the case of the nineteenth-century Spanish America novels analyzed here, the thematic subgenres are not categories of very homogeneous texts but of texts that share textual features so that they are recognizable as instances of the text types, but they do so to different degrees. Furthermore, that the results for different classifiers, feature sets, and feature parameters are so similar indicates that the approximately 20 % of accuracy that is missing to reach the perfect classification is probably not due to a wrong choice of features or settings in the classification procedure but due to the discrepancies between the conventional genres and their text types. This could also be shown in the discussion of examples of historical novels that were frequently misclassified.
724The classification of the novels by their primary literary
currents has several purposes. As for the thematic subgenres, the results
of the classification are analyzed to see which classifiers and feature
sets work best to capture the differences between the various literary
currents. The best constellations are then chosen to see how well the
different constellations of literary currents can be classified. A short
analysis of the features that are decisive in the classification as well
as overviews of how often individual novels were classified correctly or
wrong is given for the MFW-based features in this case but not for the
topics. Word-based features are considered more interesting for the
literary currents because they are not primarily thematically defined,
even if ranges of different topics are also characteristic for them. For
the literary currents, style in a narrower sense is assumed to play a
more important role.603
Figure 73 shows the
distribution of primary literary currents in the corpus.604
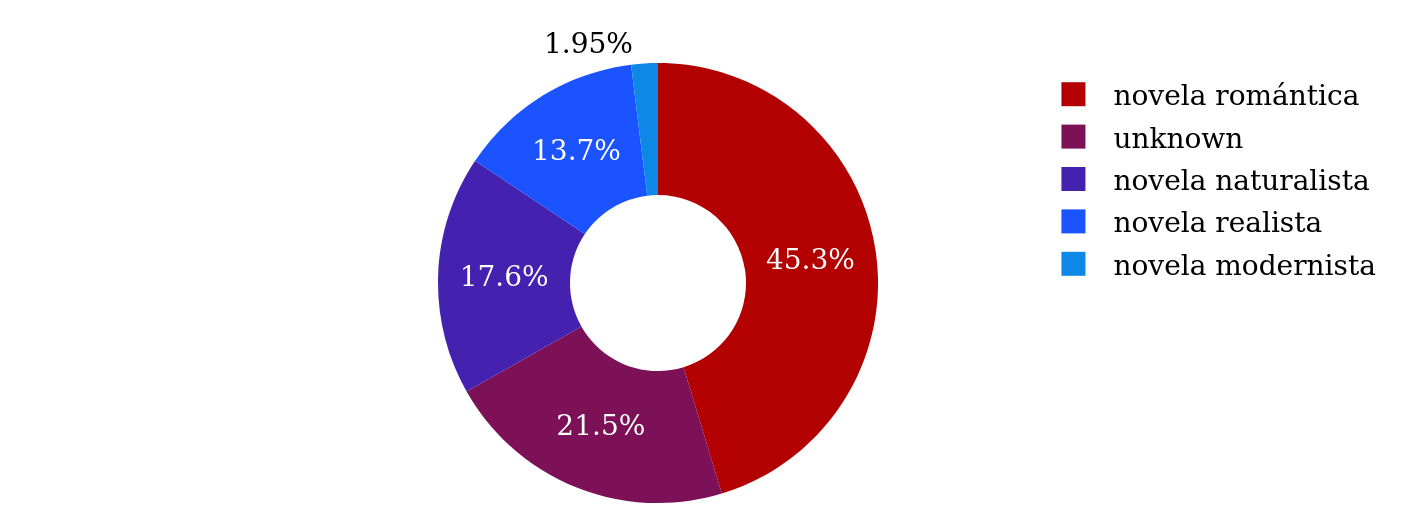
725Of the 256 novels, there are 55 for which the primary literary current is unknown.605 Romantic novels are most frequent with 116 instances, followed by 45 naturalistic, 35 realist, and 5 modernist novels. The following subgenre constellations are selected for the classification of primary literary currents:
726The novels for which the literary current is unknown were not included in classifications because they could be instances of the positive class. As for the thematic subgenres, also here the results for topic features are presented first, and then the ones for MFW-based features. First, it is determined which of the three classifiers, KNN, SVM, and RF, worked best. The overall results for the classification by literary current with topic features are shown in table 40. The results are based on 144,000 classification runs for each classifier, including all parameter variations, repetitions of data selection, and cross-validation steps.606
| Classifier | Feature type | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| KNN | topics | 1.0 | 0.83 | 0.15 | 1.0 | 0.83 | 0.15 |
| SVM | topics | 1.0 | 0.85 | 0.14 | 1.0 | 0.85 | 0.15 |
| RF | topics | 1.0 | 0.83 | 0.15 | 1.0 | 0.84 | 0.15 |
727SVM works best with a mean accuracy of 0.85, but KNN and
also RF follow closely with 0.83 each. These mean accuracies are higher
than the ones for the thematic subgenres, which were 0.77 and 0.80 for
topic features. This was not expected for the topic features because
especially the novels of the romantic current are subdivided into
specific thematic subgenres. Apparently, despite the different
conventional and textual thematic subgenres, the romantic novels all have
topics in common when contrasted with novels of the two later realist and
naturalistic currents. The possibility that the topics are not thematic
in a narrow sense also has to be kept in mind because they can also
represent other structures (descriptions, argumentation, motifs, etc.).
That so high results are already reached on average for all kinds of
features and subgenre constellations demonstrates that the literary
currents were not merely conventional movements but that the novels
associated with them had textual and stylistic traits in common. The next
step consists in evaluating which feature parameters worked best with the
SVM classifier. An overview of the results for different numbers of
topics and optimization intervals is given in figure 74.
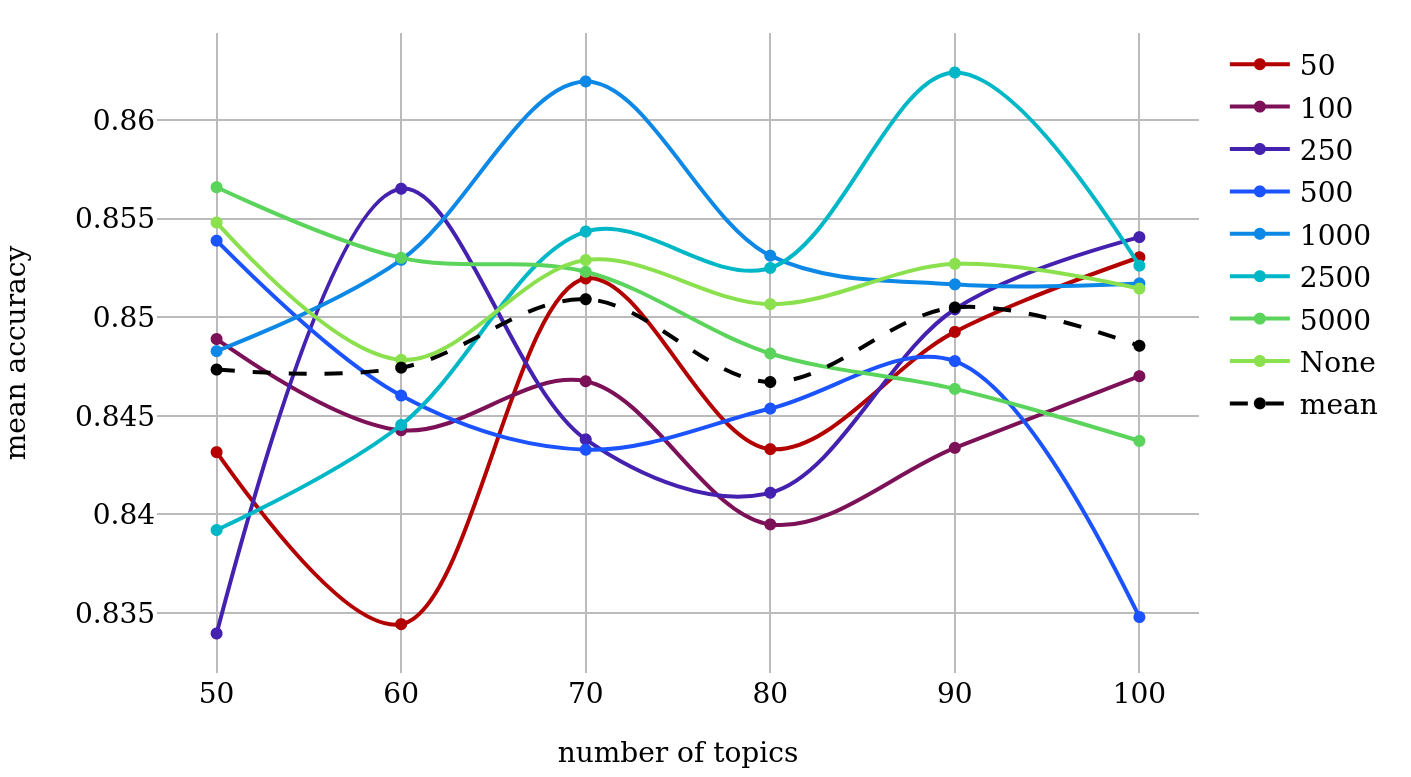
728The range of the mean accuracies goes from 0.83 to 0.86, so the differences are small between the different parameter constellations. The top mean accuracies are reached with 70 topics and an optimization interval of 1,000 and with 90 topics and an interval of 2,500.607 Regarding the developments of different optimization intervals with an increasing number of topics, the curves for intervals of 50, 100, and 250 first fluctuate and then rise from 80 topics onwards. Intervals of 500 and 5,000 have downward trends, the curves of 1,000 and 2,500 mainly fluctuate but also fall with more topics, and the curve for no optimization at all is the most stable one. Here, the best combination of 90 topics and an optimization interval of 2,500 is chosen to analyze the classification results for literary currents further. That a constellation with less hyperparameter optimization works better for the literary currents than for the thematic subgenres is a sign that it is helpful if the topics are more evenly distributed across the corpus and in the individual novels, maybe because the literary currents are more general phenomena than the thematic subgenres.
729With the decision for a certain combination of parameters for the topic feature set, the classification results for the different subgenre constellations can be inspected. The results for the literary currents with SVM, 70 topics, and an optimization interval of 1,000 are listed in table 41. These results are based on 500 classification runs for each constellation because of five topic modeling repetitions, ten random data selections, and 10-fold cross-validation.
| Subgenre 1 | Subgenre 2 | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| novela romántica | other | 1 | 0.92 | 0.07 | 1 | 0.92 | 0.07 |
| novela realista | other | 1 | 0.80 | 0.16 | 1 | 0.80 | 0.17 |
| novela naturalista | other | 1 | 0.85 | 0.12 | 1 | 0.85 | 0.12 |
| novela romántica | novela realista | 1 | 0.90 | 0.10 | 1 | 0.90 | 0.12 |
| novela romántica | novela naturalista | 1 | 0.92 | 0.09 | 1 | 0.92 | 0.09 |
| novela realista | novela naturalista | 1 | 0.77 | 0.16 | 1 | 0.78 | 0.16 |
730The mean accuracies range from 0.77 to 0.92, so there are clear differences as to how well the different literary currents can be distinguished from each other. The best mean accuracy of 0.92 is achieved for the classification of the novela romántica versus other novels and the novela romántica versus the novela naturalista. That the latter constellation yields the best results could be expected because the naturalistic novel can be considered a further development and specialization of the realist novel, carrying the realist aesthetic to the extreme so that it is also poetically more distant from the romantic novel. The best result for the novela romántica versus other novels with 0.92 and also the third best one for the novela romántica versus the novela realista with a mean accuracy of 0.91 was not expected for several reasons: because of the smooth transition of Romanticism into Realism in Spanish America, the existence of several novels that combine elements of both currents and the novels that included realistic elements before Realism (in particular the novels of customs). Furthermore, the romantic novel included several thematic subgenres, each of which is recognizable by its own topics, as was seen in the previous chapter. As it seems, the difference between romantic and realist novels is still big enough to lead to such good classification results. The classification of naturalistic novels against all others achieves a mean accuracy of 0.85, the realist novel versus the others 0.80, and the realist versus the naturalistic novels 0.77. That the score is lowest for the novela realista versus the novela naturalista could be expected because of the temporal overlap of both literary currents in nineteenth-century Spanish America but also because of the similar aesthetic concept of these two currents. The realist novel can be interpreted as the current that has a middle position between the romantic and the naturalistic novel. Therefore, it is not surprising that it has the lowest mean accuracy when it is contrasted with all the other romantic and naturalistic works. Next, the results achieved with MFW-based features and the different classifiers are analyzed for the literary currents. An overview of the results for the three main types of MFW features (words, word n-grams, and character n-grams) is given in table 42.
| Classifier | Feature type | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| KNN | MFW | 1.0 | 0.77 | 0.14 | 1.0 | 0.76 | 0.15 |
| MFW word n-grams | 1.0 | 0.69 | 0.16 | 1.0 | 0.71 | 0.17 | |
| MFW character n-grams | 1.0 | 0.78 | 0.15 | 1.0 | 0.79 | 0.15 | |
| all | 1.0 | 0.75 | 0.15 | 1.0 | 0.75 | 0.16 | |
| SVM | MFW | 1.0 | 0.86 | 0.12 | 1.0 | 0.86 | 0.13 |
| MFW word n-grams | 1.0 | 0.78 | 0.15 | 1.0 | 0.79 | 0.16 | |
| MFW character n-grams | 1.0 | 0.84 | 0.13 | 1.0 | 0.84 | 0.14 | |
| all | 1.0 | 0.83 | 0.13 | 1.0 | 0.83 | 0.14 | |
| RF | MFW | 1.0 | 0.84 | 0.13 | 1.0 | 0.84 | 0.14 |
| MFW word n-grams | 1.0 | 0.77 | 0.15 | 1.0 | 0.77 | 0.16 | |
| MFW character n-grams | 1.0 | 0.82 | 0.14 | 1.0 | 0.81 | 0.14 | |
| all | 1.0 | 0.81 | 0.14 | 1.0 | 0.81 | 0.15 |
731As with topics, so with MFW-based features, the SVM
classifier achieved the best results with a mean accuracy of 0.86 for the
basic MFW. The second-best mean accuracy is 0.84 for RF, and the worst is
0.78 for KNN. For all three classifiers, word n-gram features produced
worse results than single words. For KNN, the best results were achieved
with the character n-grams, and for SVM and RF, with words. As the SVM
classifier worked best, it was chosen to further evaluate the results.
The mean accuracies for different values of MFW and the three
normalization techniques are shown in figure 75.
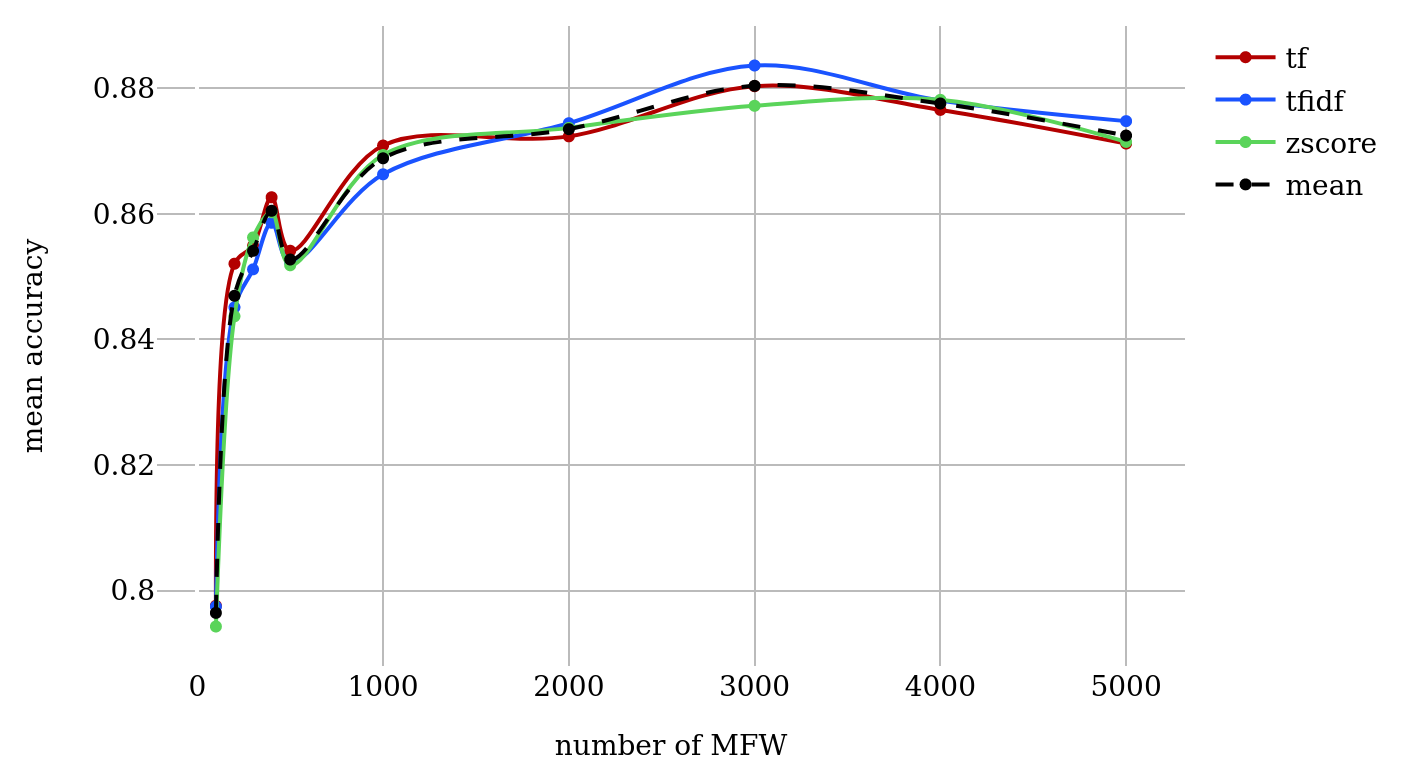
732For the basic MFW features, the highest mean accuracy of
0.88 is reached with 3,000 MFW and tf-idf values. The differences between
tf, tf-idf, and z-scores are minimal. The mean accuracies for the other
numbers of MFW from 1,000 up to 5,000 are also at 0.87 or 0.88 if the
values are rounded to two decimal points. So the most important aspect is
to use 1,000 MFW as a minimum, which was also the case for the thematic
subgenres. As 3,000 MFW and tf-idf resulted in the highest mean accuracy,
that combination of parameters was kept for the analysis of further
results. Figure 76 visualizes
the classification results for the word n-gram features.
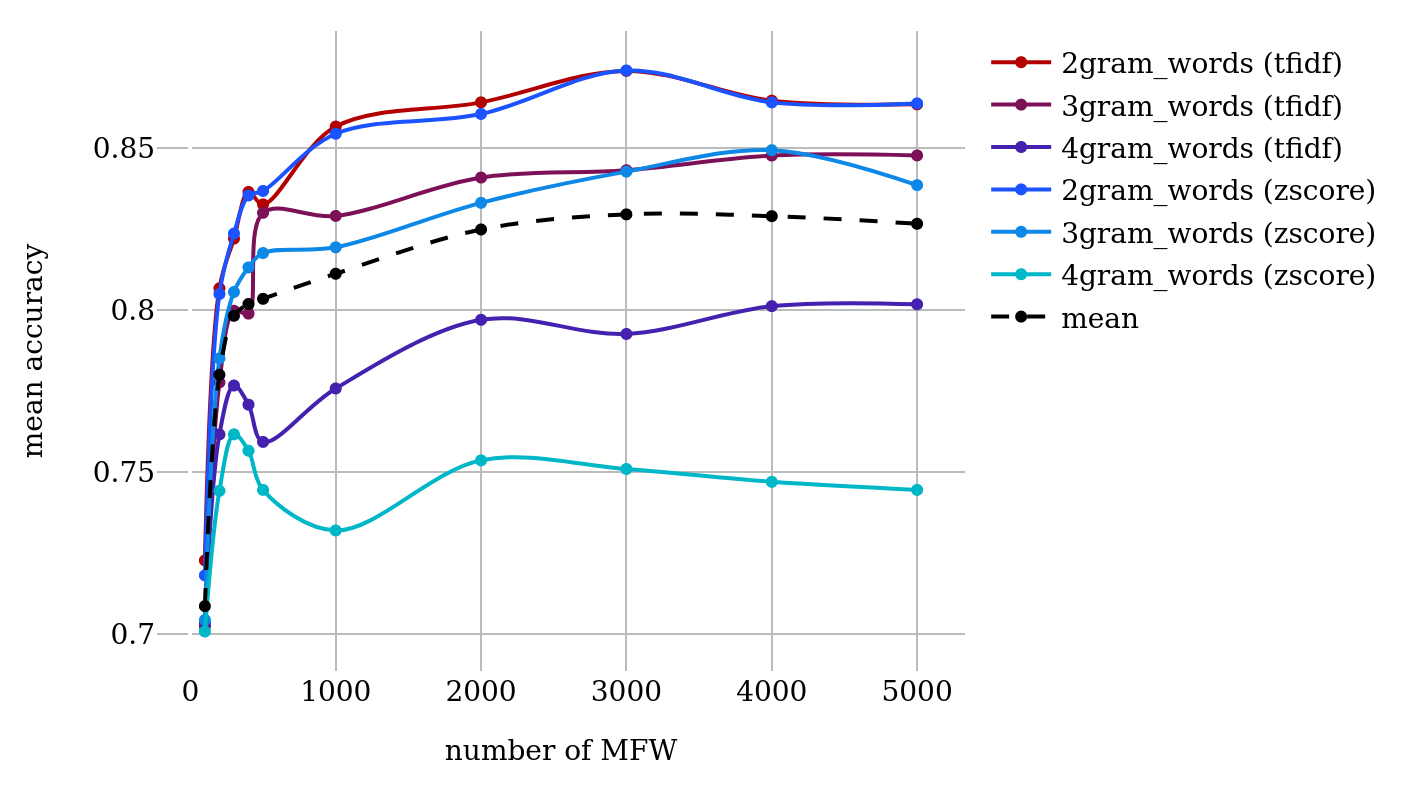
733The results for word n-grams are similar to the ones for
thematic subgenres in that word 2-grams produce better results than word
3-grams or 4-grams. Here, too, the best mean accuracy of 0.87 is reached
with 3,000 MFW for tf-idf and also for z-scores. As for word features,
also for word n-grams, the results get much better with 1,000 MFW or
more. It is of interest that the word 2-grams are almost as good as the
word features which reached 0.88 because interpreting word 2-gram
features might reveal further relevant aspects about the subgenres. Next,
the classification results for normal character n-gram features are given
in figure 77.
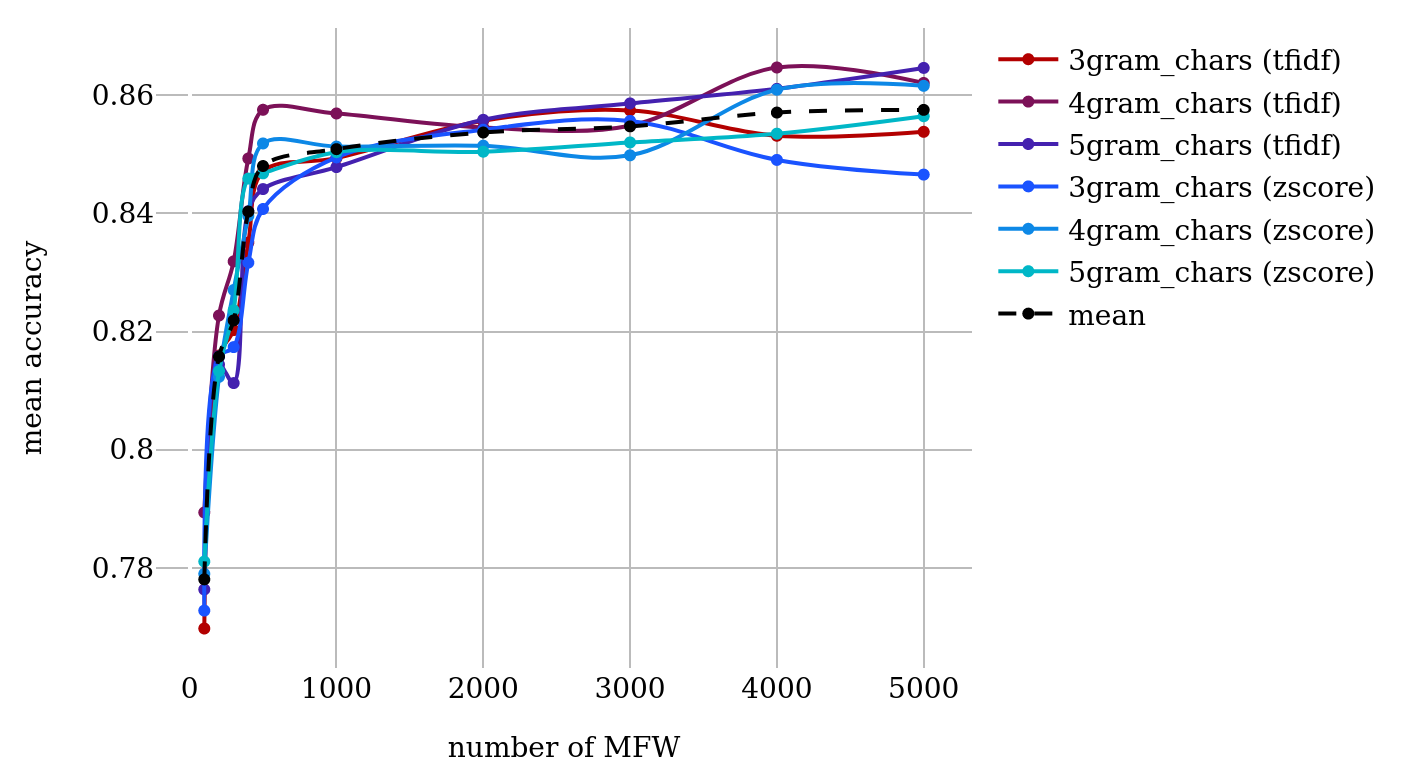
734For the character n-grams, the highest mean accuracy of
0.86 is achieved with character 4-grams, 4,000 MFW, and tf-idf, so it is
slightly worse than for word 2-grams or basic MFW. Other n-gram units
lead to very similar results, but interestingly, with more than 3,000
MFW, the scores drop a bit for character 3-grams but rise for the 4-grams
and also the 5-grams. As more content words are included with higher
numbers of MFW, maybe it is advantageous for the classification of
subgenres when a bigger part of these words is captured with the larger
character n-grams. In contrast to word units or word 2-grams, the results
for character n-grams already stabilize largely with 500 MFW. The results
for the special n-gram type “word”, which only contains character n-grams
from the inside of words and n-grams that include the end of one word and
the beginning of another, are shown in figure 78.
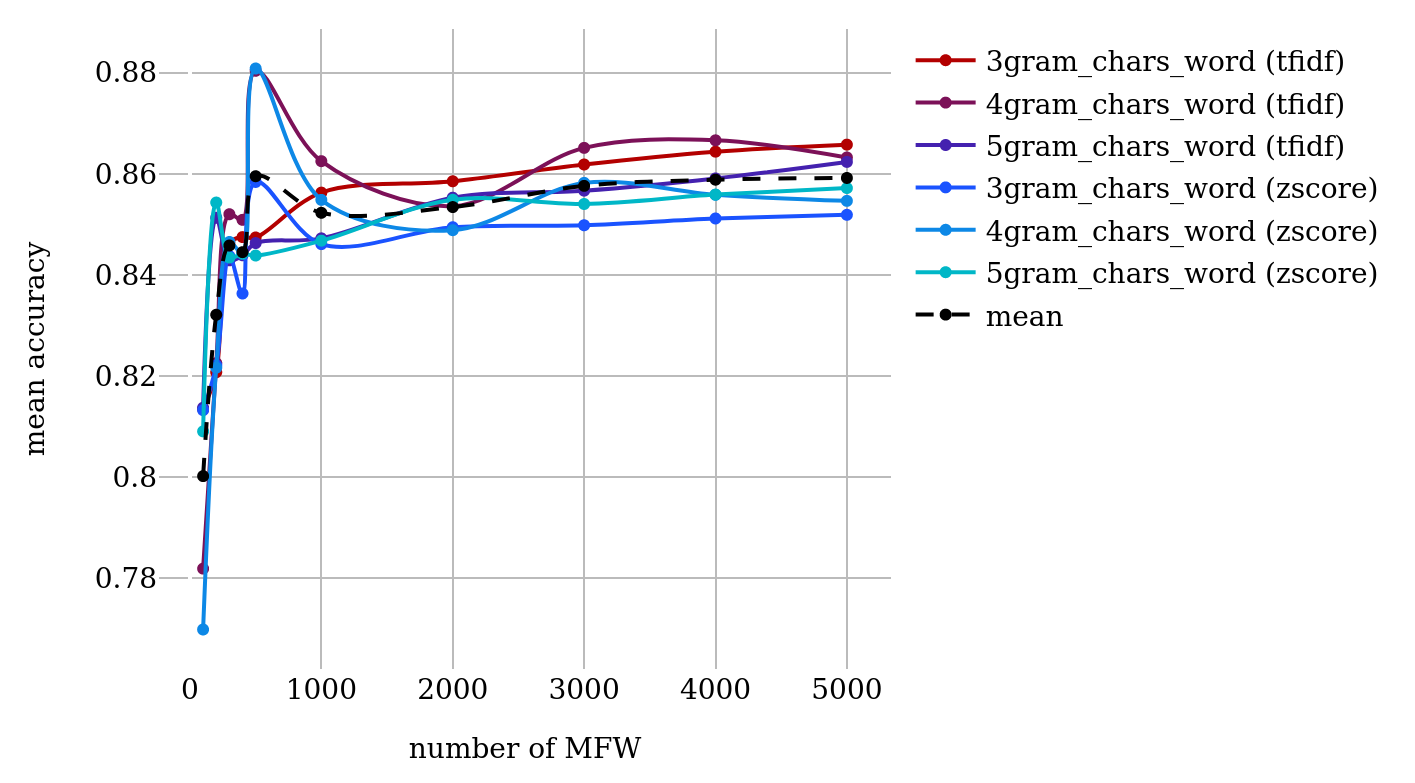
735Here the highest mean accuracy of 0.88 is reached with 500
MFW, character 4-grams, and tf-idf values or z-scores. This is higher
than for the normal character n-grams, but this special character n-gram
type does not outperform other feature types completely because it is
equal to the highest score that was achieved with basic MFW. The other
special n-gram type, “affix-punct”, which only includes prefixes, (i.e.,
word beginnings), and punctuation marks, yields 0.87 as the best score.
The same is achieved with character 4-grams, this time with 2,000 MFW and
tf-idf values, as shown in figure
79. That 4-grams are the best token unit for character n-grams
was also found out by Hettinger et al. (2015 Hettinger, Lena, Martin Becker, Isabella Reger,
Fotis Jannidis, and Andreas Hotho. 2015. “Genre Classification on German Novels.”
In Proceedings of the 26th International Workshop on Database and Expert
Systems Applications (DEXA), 249–253. Valencia. https://doi.org/10.1109/DEXA.2015.62.), so they seem to be
generally useful for subgenre classification.
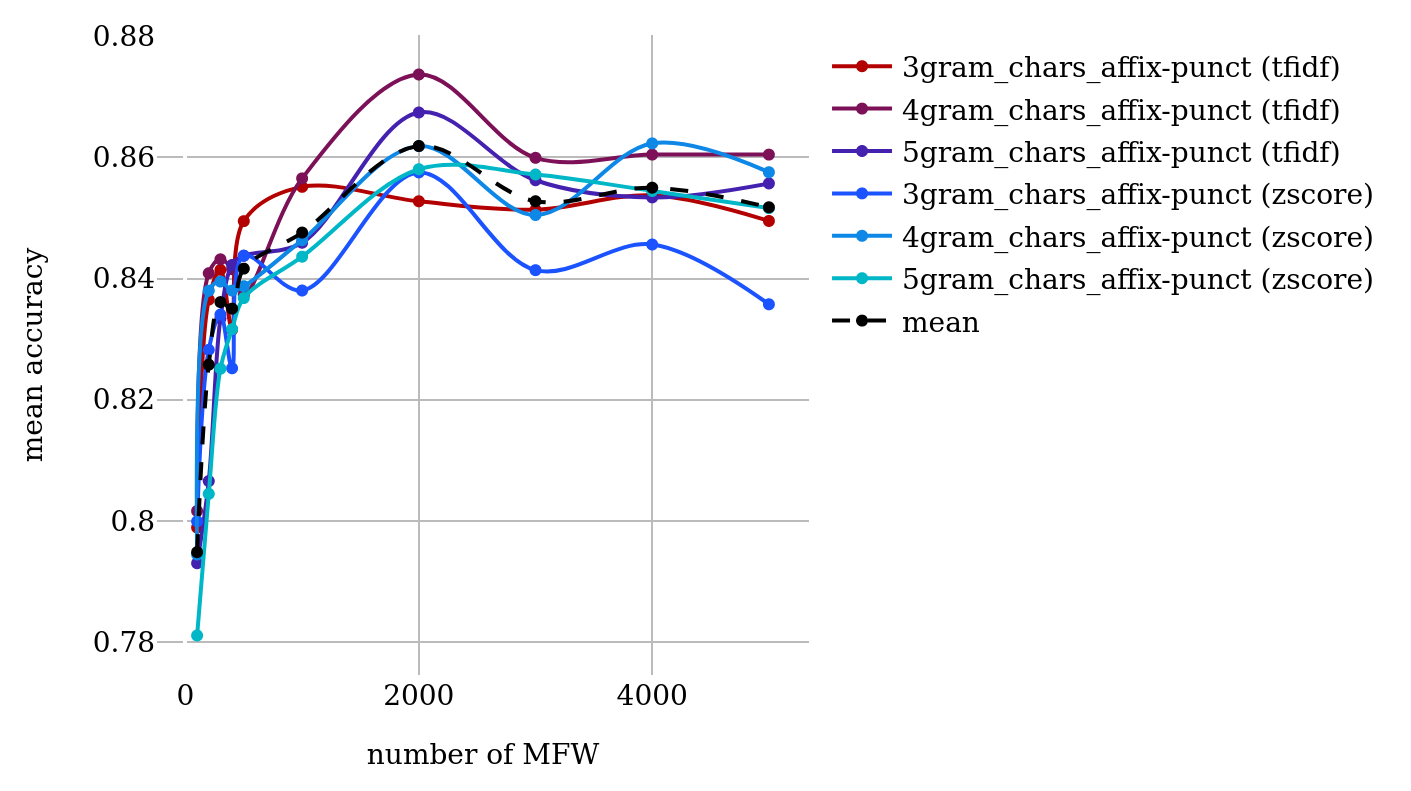
736In table 43, the classification results for the different constellations of literary currents are given, based on the SVM classifier, 3,000 MFW, and tf-idf values.608
| Subgenre 1 | Subgenre 2 | Top accuracy | Mean accuracy | SD accuracy | Top F1 | Mean F1 | SD F1 |
|---|---|---|---|---|---|---|---|
| novela romántica | other | 1 | 0.93 | 0.06 | 1 | 0.93 | 0.06 |
| novela realista | other | 1 | 0.87 | 0.12 | 1 | 0.87 | 0.12 |
| novela naturalista | other | 1 | 0.83 | 0.12 | 1 | 0.82 | 0.13 |
| novela romántica | novela realista | 1 | 0.91 | 0.09 | 1 | 0.90 | 0.10 |
| novela romántica | novela naturalista | 1 | 0.90 | 0.10 | 1 | 0.90 | 0.11 |
| novela realista | novela naturalista | 1 | 0.86 | 0.14 | 1 | 0.87 | 0.13 |
737With MFW features, the subgenre constellation for which the highest mean accuracy was reached in the classification is the novela romántica versus the other novels with 0.93. The same constellation also had the highest value with topic features, but here it is even slightly higher. The second best result is 0.92 for the novela romántica versus the novela realista, followed by 0.90 for the novela romántica versus the novela naturalista. The contrast of the realist novel with all others yields a mean accuracy of 0.87, the realist novel against the naturalistic novel 0.86, and the worst result is 0.83 for the naturalistic novel versus the other novels. Compared to the topic features, here, all values are higher except the ones involving the naturalistic novel. This result is intriguing because it seems that the naturalistic novel is better captured with features related to themes than with word features. The change goes in the other direction for the realist novel. Here, the contrast between the novela realista versus the other novels is 7 % higher than with topic features, and the opposition of the novela realista and the novela naturalista is 9 % higher here than with topic features. The novela romántica versus the novela realista is only 1 % better with MFW than with topic features, though. So the realist novel wins if word features are used instead of topics. The result is so interesting because the label “novela naturalista” is used in subtitles of several novels in the corpus. In addition, its status as a (thematic) subgenre versus a literary current or movement has been discussed, for example, by Schlickers, who confirms that the naturalistic novel was a concept that was consciously applied and communicated by contemporary writers in the nineteenth century.609
738To get an insight into the kind of MFW features that are
relevant for the classification by literary current, the two contrasts of
the novela romántica versus the novela realista
and the novela realista versus the novela
naturalista are analyzed here. Figure 80 shows the top feature weights for the
romantic versus the realist novels.
739The features that are distinctive for the realist novels
are on the left side and the ones for the romantic novels on the right
side. Among the top 25 features, there are 17 which are important for the
realist novel and only 8 for the romantic novel, which is a sign that the
realist novel is stylistically more homogeneous than the romantic novel.
Among the top words for realist novels, there are several adjectives, of
which the most important one is “rojo”. The others are “duro”, “gran”,
“duros”, “excelente”, and “listo”. In the list of the romantic novels,
there is no adjective. A more frequent use of adjectives could be due to
more descriptive passages in the realist novels. Nouns, too, are only
present in the list for realist novels: “corriente”, “grupo”, “política”,
“envidia”, “hoja”, “importancia”. So politics is an important topic in
realist novels. Groups of people are also relevant, and “envy” points to
their materialist orientation. The other three nouns are not so easily
interpreted at first sight. Furthermore, there are some verbs in the past
tense: “mostraba”, “habló”, and “escribió”. The last one, together with
“hoja”, seems to indicate that people frequently write things down in
realist novels. The words that are distinctive for the romantic novel
include the first person plural verb form “hemos”, the participle
“quedado”, the adverbs “verdaderamente” and “entonces”, the demonstrative
pronouns “esta” and “este”, and the adjective “solo”. The fact that the
word “lonely” is typical for the romantic novel fits well with the
concept of the individual romantic hero or heroine. Furthermore, it is
noticeable that the words with the top weights for the two different
literary currents belong to different grammatical categories. The feature
importances of the naturalistic versus realist novel are shown in figure 81.
740Here, the words that are distinctive for the naturalistic
novels are on the left side, and the ones that are typical for the
realist novels are on the right. Again, the proportion of top features is
8:17, with more features for the realist novels. The nouns that are
typical for the naturalistic novels are “mitad” and “pasajeros”. The
first one is an indication of quantity. The passengers could either be
connected to transport in a city or to travel. The word “costado” is here
probably the participle “cost” and not the noun “side” and alludes to the
importance of money in naturalistic novels. The adverbs “hasta” and
“recién” indicate that time also matters in novels of this literary
current. The verb “convencer” is the only infinitive in the whole list.
To convince someone means the need to discuss and the will to achieve a
certain goal. The words “cual” and “fuesen” are not easily interpreted.
As to the words that are distinctive for the realist novels, there are
some which did already appear in contrast with the romantic novels.
Again, there are several verbs in the past tense: “traía”, “dieron”, and
“oyeron”. The nouns “figura”, “gracia”, and “voces” are new. The verbs in
past tense could mean that narrative passages in which the actions of
characters are described are more frequent in realist novels than in
romantic and naturalistic ones. Altogether, the MFW features that are
weighted highly by the SVM classifier can be interpreted well as
stylistic cues of the literary currents in the same way as the topic
features could be explained for the thematic subgenres. To conclude the
discussion of the classification results for literary currents, the
classification profiles with the proportions of true
positives, false positives, and false negatives are visualized in figures
82 to 84. On the one hand, they serve to see how many
novels were always classified correctly and are part of the conventional
as well as the textual genres. On the other hand, it is checked whether
there are any cases of novels that are misclassified very frequently and
are only part of either the text type or the conventional genre.
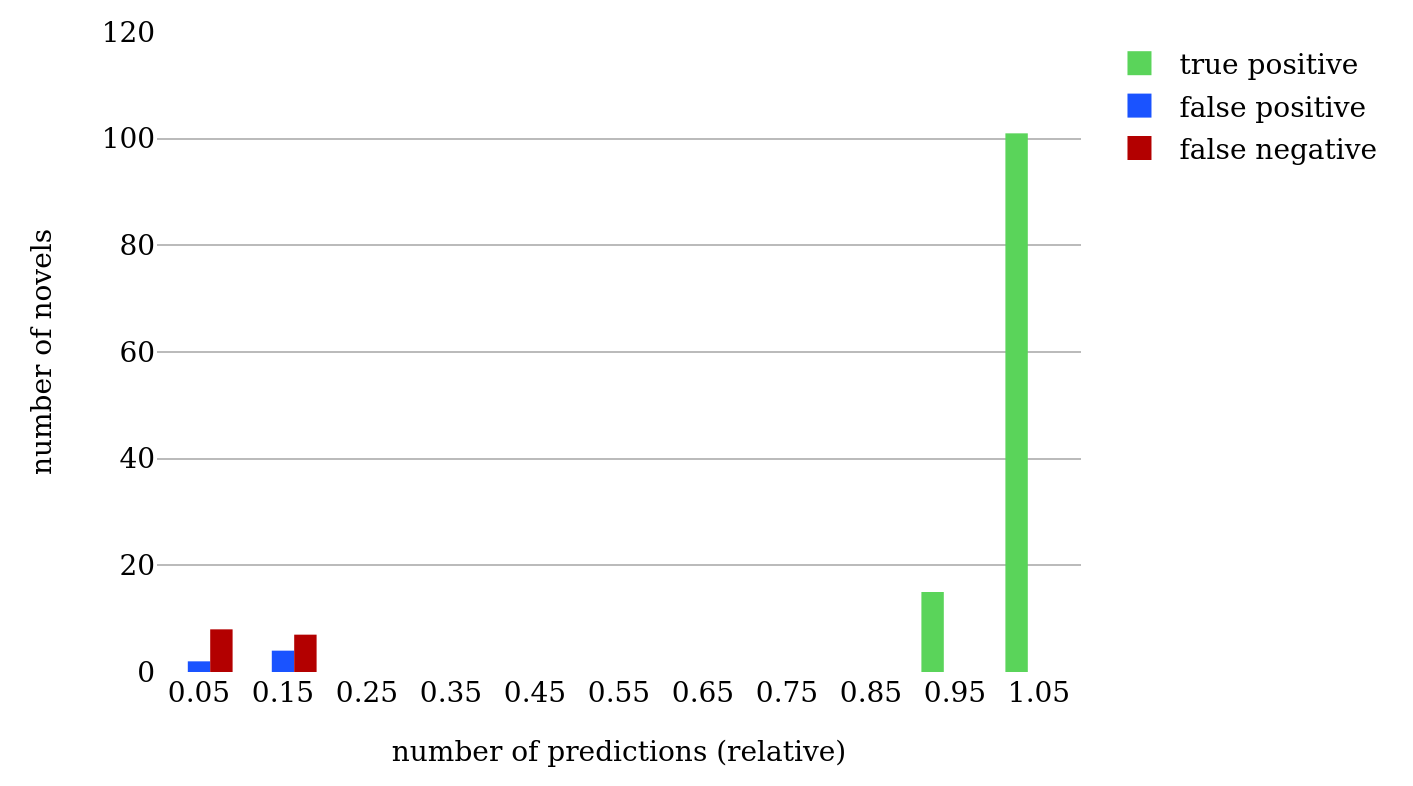
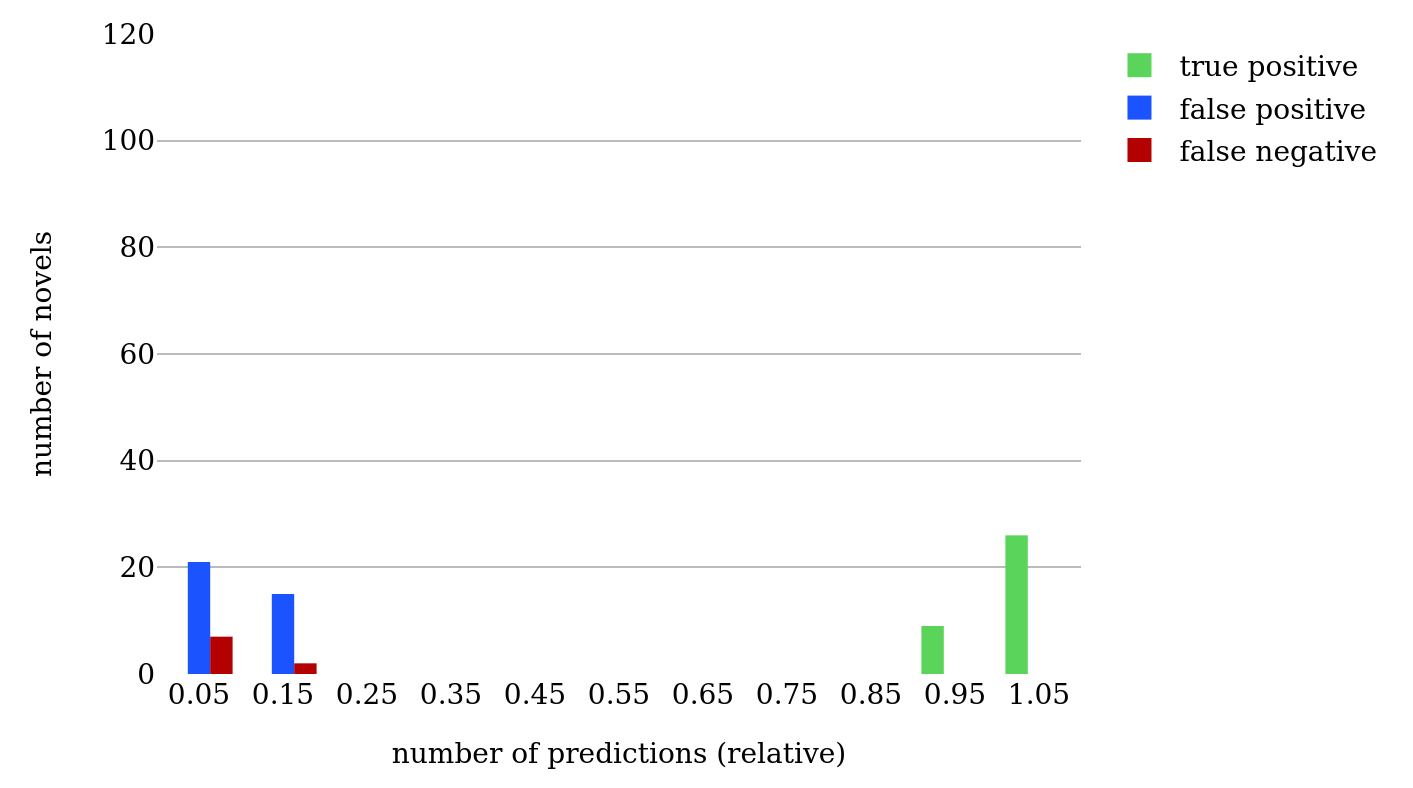
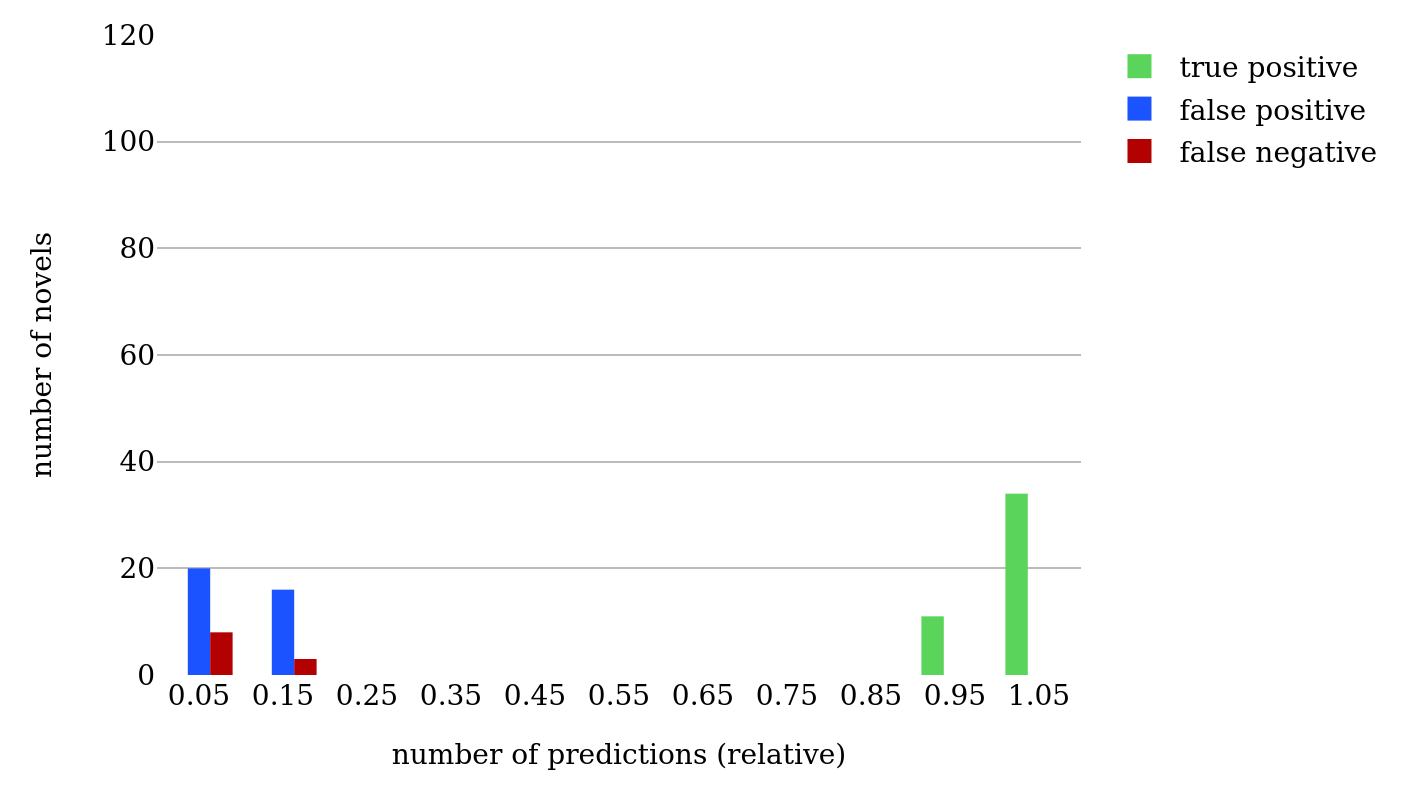
741What is striking is that there are no cases of novels that are false positives or false negatives in more than 20 % of the cases for none of the literary currents. This was very different for the thematic subgenres. It means that there are more considerable discrepancies between the conventional genres and the text types for the thematic subgenres than for the literary currents. A hypothesis is that the literary currents that the novels belong to are mostly determined by literary historians. Therefore, they could be closer to the textual characteristics of the texts than, for example, explicit historical labels of thematic subgenres that might be misleading. Another hypothesis is that the style of novels that are part of a certain literary current is easier to recognize than the primary theme of a novel. At least in some cases of the novels, there are diverging opinions also among literary historians about which primary topic they have. Furthermore, the primary themes of the novels are not necessarily congruent with the surface topics, which can lead to misclassifications. All in all, the classification results for the literary currents showed that these are indeed categories with a stylistic unity.
742In the previous chapter, statistical classification was used to categorize the novels by subgenre. Overall, high accuracy values of 70 % and more could be achieved when the classifiers tried to recognize which texts match which subgenre labels, so the congruence of the conventional genres and text types is relatively high. Furthermore, the analysis of misclassified examples showed that there are individual cases of less prototypical works or special cases in which the conventional label of a novel does not correspond so well to its textual and stylistic characteristics. As classification aims to match labels and texts, it might cover internal differentiations of the text types. The limits between the different classes are strictly drawn, and the connections that can exist between individual novels or groups of novels that are part of different conventional subgenres are cut off. Therefore, a method relying on network analysis is proposed here as a “family resemblance analysis” with the aim of providing a more open means of categorization. It is very likely that the groups of novels found by this approach are influenced by a number of different factors that determine the style of the texts, such as authorship, period, or narrative perspective. This is not viewed as a principal drawback because such factors are the ones that contribute to the organic whole of the subgenres’ style if the subgenres are understood as groups of historical texts set in a specific geographical, cultural, and temporal context and as texts written by individual authors who shape the subgenres through their works. They are only disturbing if they dominate the categorization completely so that the groupings are no longer about subgenres as the target of the stylistic analysis but about some other factor.
743In the previous chapter, it was shown that even the results of classification could be interpreted in terms of prototypical structures and family resemblance. However, in classification, the similarity between different texts is still determined based on whole feature distributions and not of overlapping parts of it. Even if it is enough for a historical novel to have high weights for some topics that are distinctive for historical novels in order to be classified as such, it is not possible in standard classification that a novel is grouped with novels of one subgenre based on some topics and categorized with novels of another subgenre based on other topics that it has – a decision for one class is always made. Even with multilabel classification, an approach where each sample can be recognized as an instance of several different classes, the assignments are made based on internal comparisons of two classes, and it is decided in each case if the sample is a member of the positive or the negative class. In the network-based family resemblance analysis, in contrast, links between individual novels are decisive. If a group of several novels turns out to have particularly strong links, they are considered members of one category. However, each member still also has links with other novels outside of the “nuclear family”. Furthermore, the similarities are determined for each pair of novels and not for one novel against all others in the group so that partial similarities, understood as individual resemblances, can hold the group together.
744Regarding the analysis of the subgenres, the family resemblance analysis has several functions. It can serve to find out how a subgenre is organized internally: by looking at the network of similarities between the individual novels, do subgroups, i.e. individual families, emerge, and which traits hold them together? Can the prospectively historical novels, for example, be distinguished from the other novels belonging to that subgenre, or the romantic historical novels from the realist and modernist ones? Or are there differences by country or over time? As can be seen, no preliminary assumption is made here as to the kind of connections that the family resemblance analysis might reveal for the internal structure of subgenres. There can be diachronic shifts but also synchronic variations in the subgenres. Another possibility is to analyze novels of several subgenres or the whole corpus of novels together to see how they are connected stylistically when no strict boundaries are applied. That way, it can be tested whether pure or mixed types of subgenres become visible as families. It is useful to test the feature sets with classification beforehand to make it probable that the textual features used are relevant for the distinction of subgenres at all. Here, topics are used as features, for which it was shown in the previous chapter that they work well to classify nineteenth-century Spanish-American novels by subgenre. In particular, the historical novel and the sentimental novel are examined, with a focus on the historical novel, to analyze the internal substructure of these subgenres. In a third network, historical and sentimental novels are compared. In the following, first, the method for the creation of the family resemblance network is outlined. Then the subcorpus of novels that was used for the family resemblance analyses is presented, and the resulting networks are discussed.
745To create the network for the family resemblance analysis, first, the similarities between all the individual novels were calculated for the chosen feature set using cosine similarity.610 After that, the resulting textual similarities were mapped onto a network structure. The novels themselves constitute the nodes in the network. The network relationships (or edges) were determined using the three nearest neighbors of each text, which were selected from a ranking of the text similarities. The strength (or weight) of the edges was calculated by summing up the similarity values of the neighbors.611
746In the overall similarity matrix, there are relationships between all the texts. Reducing the number of connections for the network to the three nearest neighbors makes the network less complex and the closest relationships in it more salient. This, in turn, enhances the interpretability of the network. The choice of three is arbitrary and could be varied. However, using more than one nearest neighbor makes the results of the network more stable, as Eder has shown (Eder 2017, 56–60Eder, Maciej. 2017. “Visualization in stylometry: Cluster analysis using networks.” Digital Scholarship in the Humanities 32 (1): 50–64. https://doi.org/10.1093/llc/fqv061.). Eder introduced the idea of visualizing nearest neighborships based on textual similarities in a network structure, intending to make the results of stylometric cluster analysis more reliable. This technique is adapted here with a different aim: to formalize the family resemblance concept for genre analysis.
747In addition to the creation of the basic network structure, community detection was used to explore the families of novels in the network. Communities are sets of nodes in a network that are more densely connected to each other than to nodes outside.612 Different algorithms for the detection of network communities exist.613 Here, the Louvain modularity algorithm was used. It is based on modularity optimization, which means that possible divisions of the network are checked and optimized to reach high modularity so that the nodes which share a community are more likely to be connected with each other than with other nodes that are not community members. The Louvain algorithm optimizes local communities iteratively until the best global modularity of the network is reached. Here, non-overlapping communities are built, meaning that each node is only part of one community in the result. As it looks for densely connected data points, the Louvain algorithm is suitable to detect families of novels. To that end, the novels are represented as vectors in a space of textual features, in which they can be closer to each other or further away, and these similarities (or distances) are interpreted in terms of network links. Furthermore, the algorithm is also comparatively efficient and has been implemented in Python, which is used to create and visualize the network here.614
748Reflecting on how the concept of family resemblance is formulated by Wittgenstein and in literary genre theory and how it is implemented here, the following observations can be made. Using similarity relationships between novels based on feature distributions means that not the presence or absence of a trait or a set of traits determines the connection between members of a family and the difference to other families, but the numerical strengths of the features in combination and this only between pairs of individual novels.615 The similarities of the various pairs are summed up and interpreted in terms of neighbor rankings to build the families. This transfers the idea of partial and overlapping similarities to a quantitative approach because nearest neighborship between novel A and another novel B, on the one hand, and novel B and C, on the other, does not mean that A and C must also be closest in a direct comparison.
749Second, when communities are calculated and interpreted as families, the boundaries of the categories are retroactively sharpened because communities are clusters, which have members and non-members. This is an advantage that balances out the looseness of the original family resemblance concept. However, there is a significant difference between these communities and classes in a logical sense because the former emerge from a network of similarities and not from the condition of shared common features. The communities mark a boundary between one group of dense relationships and another, they cut off the family at a certain point but they do not lever out the basic idea of family resemblance, because the links to other families and family members in the network can still be explored.616
750The subcorpus of novels used for the family resemblance
analysis includes 83 novels first published between 1840 and 1910. Of
these, 40 are historical novels, and 43 are sentimental novels. 32 of the
novels are Argentinian, 35 are Mexican, and 16 are Cuban. The novels were
written by 74 different authors, 11 of them female and 72 male. To
prevent the authorial signal from interfering too much with the genre
signal, for each subgenre, only one novel per author was chosen.
Nevertheless, if authors wrote novels in both subgenres, these are
included. There are nine authors with both a historical and a sentimental
novel in the subcorpus. Figure
85 shows the distribution of the novels by decade and
subgenre.617
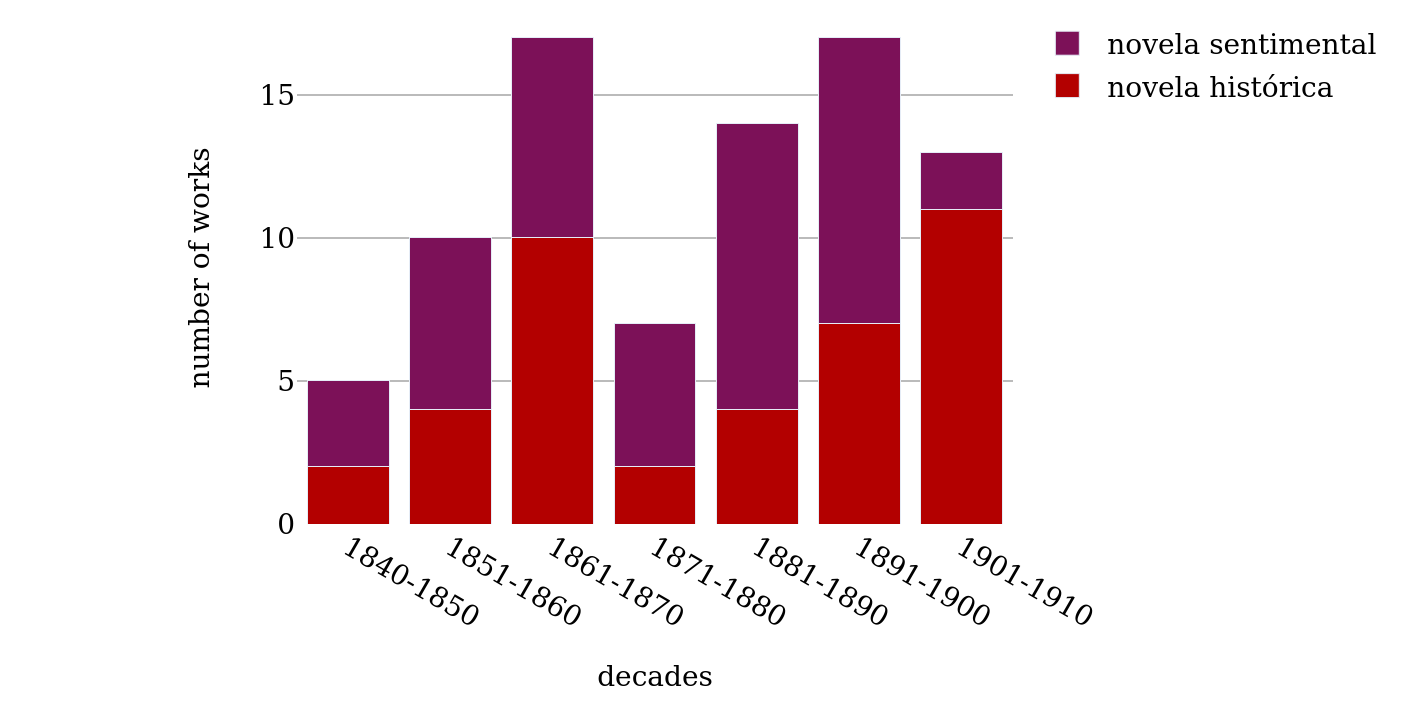
751As features, a topic model with 100 topics and an
optimization interval of 100 was used, which is considered a medium
degree of specification, given that the overall corpus contains 256
novels. The feature set was generated for the whole corpus Conha19 with
the goal of having more stable topics that represent the novel of the
time in a better way than if they had been based on the smaller
subcorpus. For the network analysis, only the features for the novels in
the subcorpus are used.618
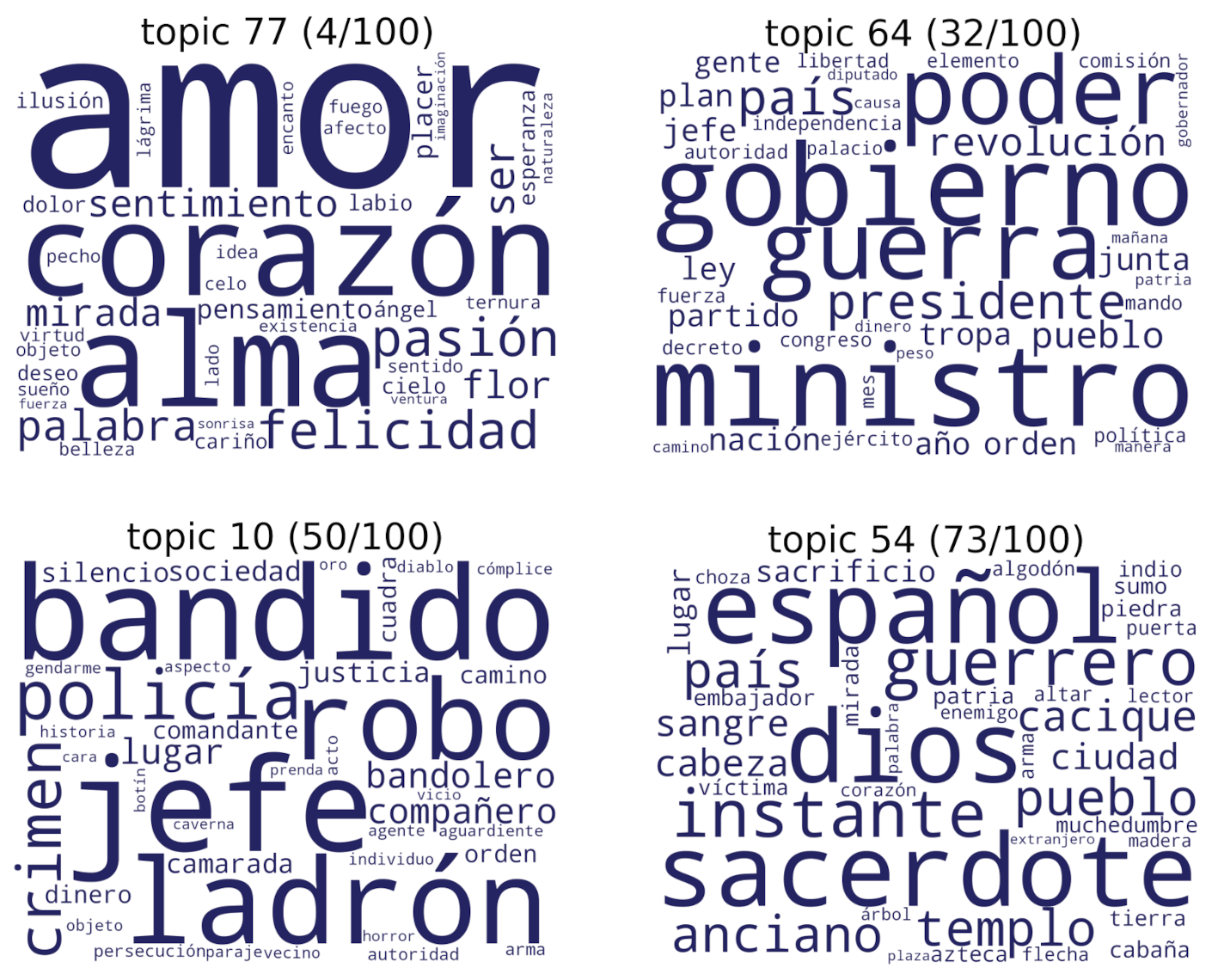
752In figure 86, the top 40 words of four of the resulting 100 topics are visualized. They exemplify the range of themes covered in the novels. The first topic is about love and feelings (“amor”, “corazón”, “alma”, “amor”, “pasión”); the second topic is dominated by politics (“gobierno”, “ministro”, “guerra”, “poder”), the third one is about crime and banditry (“bandido”, “jefe”, “ladrón”, “robo”), and the fourth one about religion and colonization (“sacerdote”, “dios”, “español”, “guerrero”). The first number in parentheses indicates the rank of the topic by its probability in the whole corpus, so the topics are of different importance for the whole collection of texts. The lower the topic rank, the more important the topic is, so the love topic is a very general one, the politics and crime topics are still rather common, and the colonization topic is more special.
753With the approach outlined in the previous section, three kinds of networks were produced, two for the individual subgenres and one for the two subgenres combined, as shown in table 44.619
| Shortcut | Subgenre(s) | Number of novels | Number of clusters (families) |
|---|---|---|---|
| HIST | historical novels | 40 | 6 |
| SENT | sentimental novels | 43 | 6 |
| HIST-SENT | historical + sentimental novels | 83 | 8 |
754The last column indicates how many families,
that is, clusters based on the communities in the network, were produced.
The number of clusters is identical for both historical and sentimental
novels when they are analyzed separately. Given that the number of novels
doubles when the two subgenres are combined, the number of resulting
clusters does not grow proportionally, indicating that there is an
overlap between the subgenres. The discussion of the results focuses on
the historical novels.620
Figure 87 shows the first
network for historical novels and topics (HIST-topics). The communities
detected are indicated by the different colors of the nodes.
755An important question for the interpretation of the network
is which kinds of novels constitute the different families.
Before looking at different clusters in detail, an overview of the
cluster sizes was generated, and the possible influence of some
text-external and -internal factors on the clusters was calculated, as
displayed in figures 88 and
89.
756Four of the resulting six clusters are evenly sized, with 8
novels each, and the other two are smaller. Cuban novels are only
contained in clusters 1, 2, 3, and 5. Clusters 1, 4, and 5 are dominated
by Mexican novels and clusters 2 and 3 by Argentine novels. Cluster 3 is
an Argentine-Cuban cluster, and cluster 5 is a Mexican-Cuban cluster.
Even if there are some tendencies regarding the distribution of novels by
country in the different clusters, there is no cluster consisting only of
novels from one country, and it should also be kept in mind that the
overall number of novels in the individual clusters is quite small. The
narrative perspective is not significant for the historical novels
because there is only one novel with a homodiegetic narrator, the others
all have a heterodiegetic narrator. The five historical novels written by
female authors are distributed over the three clusters 2, 3, and 4, so
there is no clear female cluster. Regarding the distribution of the
novels over the years, there is also much overlap, as all the clusters
have earlier and later novels. Apart from one outlier, cluster 2 is
rather late, and cluster 4 is mostly filled with earlier works.
757When one looks at one cluster in detail, it is possible to retrace the family resemblance relationships. In table 45, the novels contained in cluster 3 are listed together with their nearest neighbors (N-1, N-2, N-3), including the weight of the edge to the respective neighbor. The strongest relationship exists between “La novela de la sangre” (1903, AR) by Carlos Octavio Bunge and “Los misterios del Plata” (1868, AR) by Juana Manso de Noronha because they are mutually closest to each other. Other bilateral nearest neighborships between novels in the cluster are highlighted in lighter orange. The novel “Pepa Larrica” (1884, AR) by Rafael Barreda has two nearest neighbors in the cluster, but the relationships are only unilateral. Boxes that are not highlighted show which nearest neighbors are outside of the current cluster. It becomes clear that some novels are central members of the family while others are rather distant relatives.
| Idno | Author | Title | N-1 | N-2 | N-3 | |||
|---|---|---|---|---|---|---|---|---|
| nh0017 | Mármol | Amalia | Misterios | 1.4 | Sangre | 1.2 | Cl 1 | 0.3 |
| nh0081 | Bunge | La novela de la sangre | Misterios | 1.5 | Crucis | 1.2 | Amalia | 1.2 |
| nh0094 | Manso | Los misterios del plata | Sangre | 1.5 | Amalia | 1.4 | Cl 4 | 0.6 |
| nh0160 | Barreda | Pepa Larrica | Cl 4 | 0.4 | Misterios | 0.4 | Sangre | 0.4 |
| nh0166 | Bacardí-Moreau | Vía Crucis | Sangre | 1.2 | Cl 4 | 0.6 | Cl 5 | 0.6 |
758The topic distributions for the five novels are visualized
in figure 90 to see what
topics are decisive for the relationships in this cluster of historical
novels. The axis on the top shows the absolute value that the topic
achieved in each novel, and the axis to the left shows the individual 100
topics.621 In
addition to the lines for the five novels in the cluster, a black dashed
line indicating the mean topic values for all the historical novels in
the network is added. The topics are ordered by importance in the whole
corpus of 256 novels from top to bottom so that more general topics are
at the top and more special topics are further down. Some topics of
interest are labeled, the black ones being particularly important for
this cluster and the red ones less important when compared to all the
historical novels in the corpus. What makes the family approach visible
is that not all the decisive topics are equally relevant for the
individual novels in the cluster. For example, the topics
“sacerdote-dios-español” and “fortaleza-batería-plaza” are
underrepresented in the whole cluster, but “amor-corazón-alma” and
“soldado-fuego-columna” are only partly less relevant. The first
corresponds to the mean for the novel “Amalia” and the second reaches
almost the mean for “Vía Crucis”. Topics that are overrepresented in
several novels in the cluster are “voz-palabra-brazo”,
“idea-espíritu-instante”, “pueblo-ley-país”, “calle-puerta-voz”,
“agua-cuerpo-sangre”, “gobierno-ministro-guerra”,
“puerta-espíritu-cabeza”, and “cabeza-rosa-asesino”. They stand for the
general characteristics of the family: historical novels that are not so
much mixed with love stories, not focused on military actions and not
about the Conquest or colonial history, but about political ideas and
conditions, and about (inter)personal contacts and states, about voices,
words, and bodies. However, as specific topic values are not necessary
conditions, some of the novels have their own special topics. The topic
“mar-buque-puerto” is specific for “Los misterios del Plata”,
“negro-esclavo-amo” for “Vía Crucis”, the only Cuban novel in this
cluster, and “capitán-voz-revolución” for “Pepa Larrica”.
759A more general overview of the topics that are distinctive
for the different clusters in the network of historical novels is given
in figure 91. In the heatmap,
the brighter the boxes, the more important the topics are for the
cluster, and the darker, the lesser important they are. The
distinctiveness was calculated by normalizing the topic values to
z-scores. Here, only the top 30 most distinctive topics are shown. The
values in parentheses at the end of the topic labels indicate the ranks
of the topics in the whole corpus, so the topic “voz-palabra-brazo”, for
example, is much more general than “fortaleza-batería-plaza”.
760The distinctive topics of cluster 3 that were already discussed can be recognized in the heatmap. The smallest cluster 0 seems to be about the Conquest and colonial history, as the most distinctive topics are concerned with Indians and Spaniards (“indio-español-tierra”), rural church (“cura-fraile-pueblo”), and seafaring (“mar-buque-puerto”). In Cluster 1, topics about military campaigns and rural life prevail, making one think about internal struggle, bandits, and gauchos. The topics that are distinctive for this cluster are about conversation and social roles of bandits (“palabra-asunto-razón”, “bandido-jefe-razón”, “bandido-jefe-ladrón”), provincial police forces (“cabellero-comisario-provincia”), horses (“caballo-amo-instante”), soldiers and military actions (“manera-soldado-muerte”, “ejército-prisionero-jefe”), and ranches (“hacienda-compadre-pueblo”). Cluster 2 is not so easy to interpret. It is also about military action (“soldado-fuego-columna”, “sargento-cerro-gruta”, and “ejército-guerra-ciudad”), but there are other, individual topics. Cluster 4 is clearly romantic, as it contains topics about love (“corazón-alma-lágrima”, “amor-corazón-alma”), about the missionary work, colonial administration and aristocracy (“sacerdote-dios-español”, “alcalde-dama-barón”), and illness (“instante-doctor-sitio”). This fits well with the observation that it contains mostly earlier novels. The last cluster is politico-historical with top topics about the military (“soldado-jefe-coronel”, “fortaleza-batería-plaza”), government (“gobierno-ministro-guerra”), and the time of the French intervention in Mexico (“francés-emperador-estudiante”).
761The results for the network of sentimental novels and the
one containing both types of subgenres are only summarized briefly here.
Regarding the metadata, the cluster sizes vary more for the sentimental
novels. The biggest cluster has 14 novels, and the smallest one has only
two. All the clusters are mixed by country. Among the sentimental novels,
there are more with an autodiegetic and a homodiegetic narrator, and the
narrative perspective has an influence on the results. The smallest
cluster, for instance, consists solely of autodiegetic texts featuring
topics related to inner life and landscape. For the sentimental novels,
there are also clearer tendencies of topic changes over time, as figure 92 shows. The early
cluster 0 is romantic with letters, dance, aristocracy, and much
emotionality. The three later clusters are the ones dominated by
interiorization, and the mid-century cluster 5 is worldly about food,
marriage, business, and money.
762When both subgenres are analyzed together, they are not
neatly sorted into different families. As can be seen in
figure 93, there are
clusters dominated by one subgenre – clusters 1, 3, and 6 by sentimental
novels and clusters 2, 4, and 7 by historical novels – but there is no
cluster containing only novels of one subgenre and the clusters 0 and 5
are entirely mixed. In the combined network, the cluster sizes vary
moderately from 7 to 13 novels. Here, too, there is no clear tendency for
countries. Different narrative perspectives are not concentrated in
single clusters, so this aspect observed for the sentimental novels alone
disappears when they are analyzed in the more general setup. Regarding
the distribution by years, cluster 1 is early, clusters 3, 4, and 6 are
late, and the others are mixed. The topics that are distinctive for the
different families reflect the relative purity or mixture of
subgenres as well as the preferences of the early versus late nineteenth
century.
763To conclude, with the analysis of topics in nineteenth-century Spanish-American historical and sentimental novels in a network-based approach, a proposal was made here how the concept of family resemblance that has been introduced into genre theory in the 1960s and argued for by several genre theorists also recently, can be applied in a digital genre stylistics approach. When one looks at the current strategies to categorize genres in this field, the majority focuses on classificatory groupings based on the assumption of features that are common to all members of a class. Yet, there are also alternative ways to analyze genres in digital stylistics. Especially stylometric network analyses implicitly contain the idea of overlapping similarities and unsharp boundaries characteristic of the family resemblance approach. Here these two scenarios were brought together. With the chosen approach to compare feature distributions of the novels in terms of nearest neighborships and to organize the resulting network of similarities into communities interpreted as families, the original idea of family resemblance is adjusted for the digital analysis. First, because rather than the presence or absence of individual textual features, the degree of their joint presence in individual pairs of novels is decisive, and second, because communities or clusters found in the similarity network constitute a way to delimit the “families” retroactively, without changing the underlying concept of intertwining shared characteristics of individual members of the groups.
764For the Argentine, Mexican, and Cuban historical and sentimental novels, the analysis confirmed that there are subtypes of the subgenres that have been described in literary-historical approaches, such as a novel with a historical setting and a sentimental plot or a historical novel focusing on contemporary political conditions in contrast to novels about historical events about colonial times. In addition, influences of the narrative perspective on subtypes of the sentimental novel became visible. Analyzing both types of subgenres together resulted in mixed groups as well as some that are dominated by one subgenre. While the country the novels were published in does not have a clear impact on the resulting families of novels, the year of publication has an influence in some cases when the preferred and avoided topics reflect the literary development in the nineteenth century.
765The family resemblance analysis is a categorization method that is more open than classification, and if it is applied to more than one type of novel, it allows the novels to be grouped based on criteria other than only their conventional subgenre. All kinds of factors that have an influence on the surface features – as the topics in the analysis conducted here – potentially have an impact on the structure of the family resemblance network if these factors are not controlled beforehand through the composition of the corpus, as was done here with authorship. So depending on how many and which determining factors of style are permitted to enter the network, the family resemblance analysis reveals different stylistic connections between the works, conventional subgenre being one of them. All in all, the results show that features common to all novels of a conventional subgenre cannot be expected and that the textual factors that influence the subgroups or families of subgenres are diverse. There is not one decisive factor, each family has its own traits that hold it together, and inside of each one, there are additional individual traits as well as connections to other families.
766The algorithm producing the family resemblance network and the resulting data offer an empirical ground on which literary historians can look for sense in genre historical terms. The idea of family resemblance that is implemented here is different from Wittgenstein’s metaphor because it is not about resemblances caused by biological kinship or because of the use of the same word for concepts that do not have necessary common semantic features but partial similarities in meaning. It is also not about conventional relationships between the literary works and does not say anything about the historico-cultural and communicative relevance of the connections inside the network. Here the concept is interpreted in terms of textual families. As the family resemblance network is based on stylistic features, it might reveal previously unrecognized textual similarities in addition to confirming known ones on a broader textual basis. By not presupposing strict uniformity inside and strict boundaries between the text types, it might come closer to the multi-faceted genre that the novel is.
n_neighbors (KNN).
weights
(KNN).
metric
(KNN).
C
(SVM).
max_features (RF).
{kind=link}
{kind=link}
{kind=link}